论文速读《Embodied-R: 基于强化学习激活预训练模型具身空间推理能力》
项目主页:https://embodiedcity.github.io/Embodied-R/
论文链接:https://arxiv.org/pdf/2504.12680
代码链接:https://github.com/EmbodiedCity/Embodied-R.code
0. 简介
具身智能是通用人工智能的重要组成部分。我们希望预训练模型不仅能在信息空间中实现问答、多模态理解,还能像人一样在真实三维空间中基于连续的视觉观测实现感知、思考和动作。这意味着预训练模型在感知基础上,形成对环境的形而上的理解,并结合意图规划自我动作,比如:“总结历史动作轨迹”、“归纳自身与周围对象的空间关系”、"根据导航目标确定下一步的动作"等。
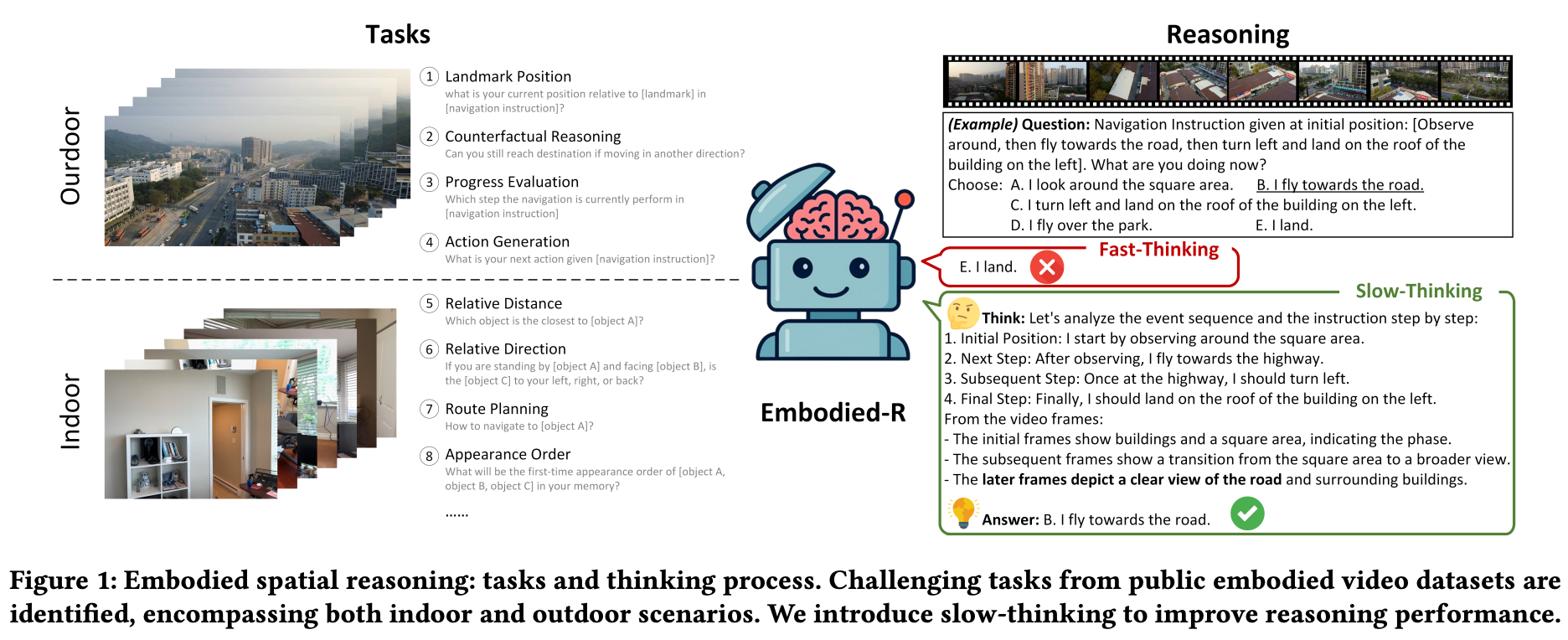
图1:具身空间推理:任务与思维过程。我们从公共的具身视频数据集中识别出具有挑战性的任务,涵盖室内和室外场景。我们引入了慢思考的概念,以提升推理性能。
受OpenAI-o1/o3、DeepSeek-R1等推理模型的启发,本论文提出了首个基于连续视觉感知的具身空间推理框架Embodied-R,通过强化学习(RL, Reinforcement Learning)和大小模型协同,将R1推理训练范式拓宽至具身智能领域。在训练资源受限情况下,只训练其中的小规模参数基座模型,最终表现媲美Gemini-2.5-Pro、OpenAI-o1等SOTA多模态推理模型。

1. 主要贡献
-
首个基于连续视觉感知的具身空间推理框架:Embodied-R将推理训练范式拓展到具身智能领域,处理第一人称视角下的连续视觉输入。
-
创新的大小模型协同架构:将感知与推理分离,利用大规模VLM进行感知,小规模LM进行推理,实现资源高效的模型训练。
-
有效的奖励机制设计:提出专门针对具身推理的逻辑一致性奖励,解决训练过程中的奖励欺骗问题。
-
显著性能提升:相比商用多模态大模型提升超10%,相比SFT训练模型提升5%以上,在分布外数据集上表现媲美Gemini-2.5-Pro。
2. 相关工作
2.1 大型语言模型推理
近期,增强推理能力已成为大模型技术的关键焦点,在数学和逻辑问题求解等任务上展现出显著性能。随着OpenAI的o1发布,众多研究提出了各种技术方法以实现类似功能,包括:
- 思维链(Chain-of-Thought, CoT):通过中间推理步骤提高复杂问题解决能力
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS):探索多种可能的推理路径
- 知识蒸馏:从强推理能力模型中提取知识
- 监督微调(SFT)或直接偏好优化(DPO):结合拒绝采样改进推理质量
DeepSeek-R1和Kimi K1.5引入了基于规则的奖励结合强化学习培养大型语言模型推理能力涌现的方法,这种强化学习范式引起了极大关注,后续工作成功复现了相关结果。
2.2 基于视觉-语言模型的具身空间推理
具身智能旨在开发利用大型多模态模型作为其"大脑",在三维物理世界中实现感知、导航和操作的智能体。人类视觉-空间感知更类似于连续的RGB观察(如视频流),而非静态图像或点云。具身视频基准测试表明,虽然感知任务相对容易解决,但空间推理任务——如空间关系推断、导航和规划——仍然极具挑战性。现有研究主要关注非具身内容推理,很少关注涉及具身连续视觉输入的场景。
2.3 大小模型协作
现有研究主要关注解决与大模型相关的资源消耗和隐私风险,以及小模型在特定场景中的效率和性能优势。小模型可以协助大模型进行数据选择、提示优化和推理增强。有研究探索了使用小模型检测幻觉和隐私泄露,提高整体系统可靠性。虽然本研究与减少计算资源需求的目标相同,但它强调了大规模VLM在感知和小规模LM在增强具身空间推理方面的互补性角色。
3. 核心算法
们首先定义具身空间推理问题。随后,介绍基于VLM的感知模块和基于LM的推理模块。协作框架如图2所示。
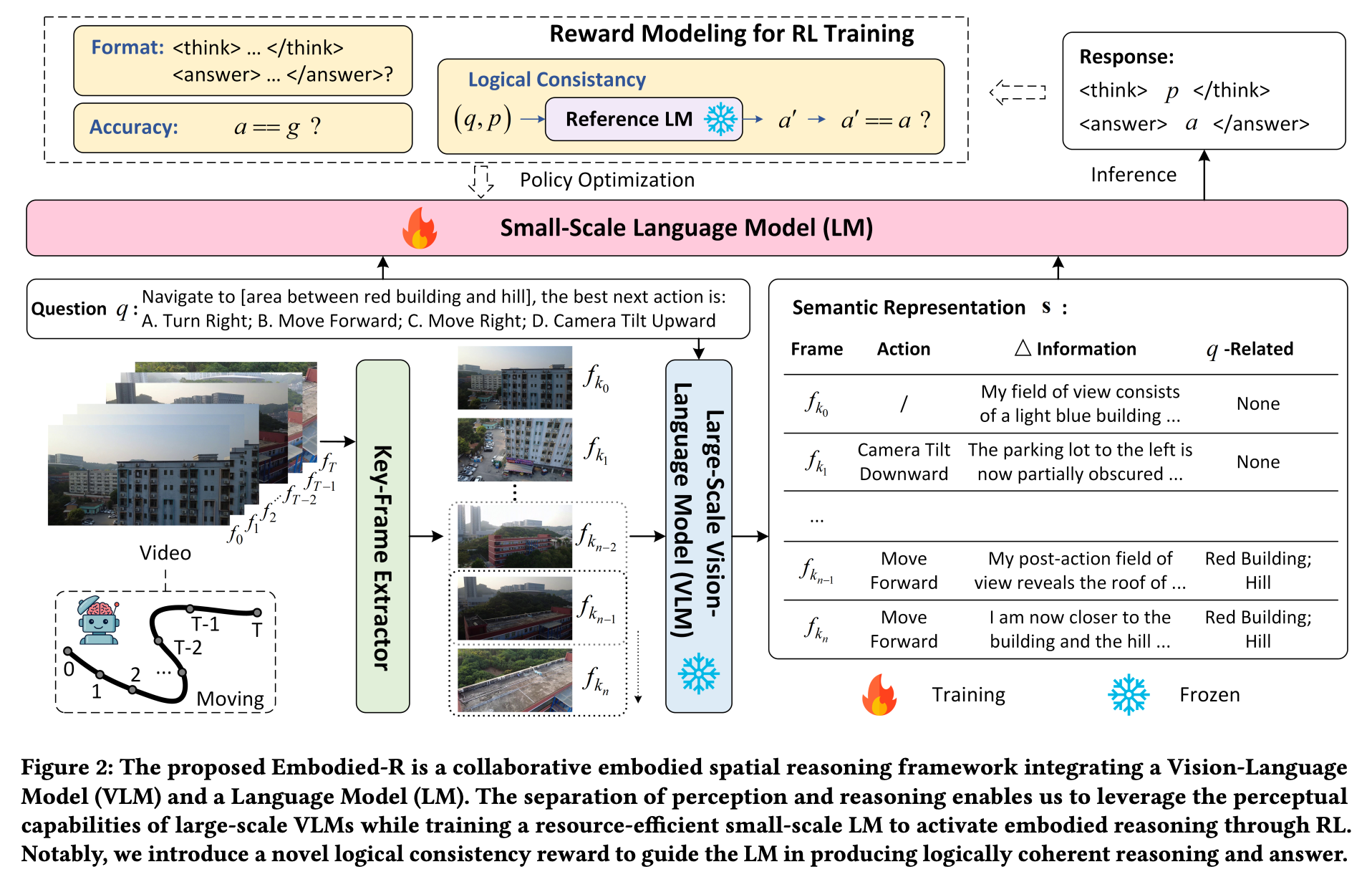
图2:所提出的Embodied-R是一个协作的具身空间推理框架,它集成了视觉-语言模型(VLM)和语言模型(LM)。感知与推理的分离使我们能够利用大规模VLM的感知能力,同时训练一个资源高效的小规模LM,通过强化学习(RL)激活具身推理。值得注意的是,我们引入了一种新颖的逻辑一致性奖励,以引导LM生成逻辑上连贯的推理和答案。
3.1 问题定义
在物理世界中,智能体在空间中移动,生成一系列视频帧(连续视觉观察) f = [ f 0 , f 1 , … , f T ] f = [f_0, f_1, \ldots, f_T] f=[f0,f1,…,fT]。假设空间推理问题表示为 q q q。我们的目标是构建一个模型,以 q q q和 f f f作为输入,输出答案 a a a。如果答案 a a a在语义上与真实答案 g g g一致,则认为是正确的;否则,视为不正确。
3.2 基于大规模VLM的感知
3.2.1 关键帧提取器
随着智能体在空间中连续移动,高采样频率导致连续帧之间存在显著重叠。一方面,VLM依赖环境中静态物体在帧间的变化来推断智能体姿态变化。另一方面,帧间过度重叠会导致VLM和LLM的推理成本增加。针对这一问题,我们设计了一个针对具身视频特性的关键帧提取器,选择既保持重叠又确保帧间信息增益充分的关键帧。
关键帧的提取基于由运动连续性引起的视野重叠。当智能体向前移动时,后一帧的视觉内容预期与前一帧部分重叠;向后移动时情况相反。类似地,在左右旋转时,后一帧应在水平方向与前一帧部分重叠;在上下旋转时,重叠发生在垂直方向。由于视觉观察的采样频率通常远高于智能体的运动速度,帧间通常表现出显著重叠。
具体而言,我们使用透视变换来模拟帧间的几何关系。假设 f t f_t ft是一个关键帧,要确定 f t + 1 f_{t+1} ft+1是否也应被视为关键帧,我们使用Oriented FAST和Rotated BRIEF (ORB)算法计算 f t f_t ft和 f t + 1 f_{t+1} ft+1的关键点和描述符。接着,应用暴力匹配器等特征匹配算法匹配两帧间的描述符,并使用随机样本一致性(RANSAC)算法估计单应性矩阵。然后计算两帧间的重叠率。如果重叠率低于预定义阈值,表明帧间存在显著视觉变化,标记 f t + 1 f_{t+1} ft+1为关键帧。否则,算法继续计算 f t f_t ft和 f t + 2 f_{t+2} ft+2之间的重叠率。此过程持续进行,直到识别出新的关键帧,该关键帧随后成为后续帧的参考。考虑视点变化的影响,旋转(水平和垂直)会导致更大的视野变化,在这些运动过程中会记录更多帧。如果提取的关键帧索引表示为 f ′ = [ f k 0 , f k 1 , … , f k n ] f' = [f_{k_0}, f_{k_1}, \ldots, f_{k_n}] f′=[fk0,fk1,…,fkn],则关键帧提取过程可总结为:
f ′ = K-Extractor ( f ) f' = \text{K-Extractor}(f) f′=K-Extractor(f)
3.2.2 具身语义表示
由于感知能力与模型大小呈正相关,我们使用大规模VLM处理视觉输入以确保高质量感知。每个关键帧的差异信息会被顺序描述。这种方法提供两个关键优势:
- 顺序和动态处理更符合具身场景的特性,其中视觉观察随时间持续生成。在每个时刻,模型应该将历史语义表示与最新视觉观察整合,快速更新空间感知的语义理解。
- 它有助于通过避免同时处理所有帧时出现的输入token限制来处理长视频。
具体来说,对于第一帧,VLM识别场景中存在的物体、它们的属性和空间位置。对于后续帧,将前一帧和当前帧输入VLM以提取关键语义表示 s k j s_{k_j} skj:
s k j ∼ ψ θ ( s ∣ f k j − 1 , f k j ; q ) , j = 1 , 2 , . . . , n s_{k_j} \sim \psi_\theta(s|f_{k_{j-1}}, f_{k_j};q), j = 1, 2, ..., n skj∼ψθ(s∣fkj−1,fkj;q),j=1,2,...,n
其中 s k j s_{k_j} skj包含三个项目:
- 动作:根据连续帧间视觉观察的变化推断智能体的动作。
- △信息:确定智能体与已知物体之间空间关系的变化,以及识别视野中是否出现新物体。
- 与 q q q相关的内容:检测与推理任务相关的物体或信息是否出现在最新视野中。
通过这种方式,我们可以从关键帧 f ′ f' f′中提取空间语义表示 s = [ s k 0 , s k 1 , . . . , s k n ] s = [s_{k_0}, s_{k_1}, ..., s_{k_n}] s=[sk0,sk1,...,skn]。
3.3 基于小规模LM的推理
给定语义感知,我们可以训练一个训练友好的小规模语言模型,能够执行具身空间推理。假设小规模LM表示为 π θ \pi_\theta πθ,模型推断的响应 o o o可表示为: o ∼ π θ ( o ∣ q , s ) o \sim \pi_\theta(o | q, s) o∼πθ(o∣q,s)。
我们的训练目标是确保模型遵循"思考-回答"范式,其中思考过程逻辑严密,答案正确。我们遵循DeepSeek-R1-Zero并采用计算效率高的RL训练策略——分组相对策略优化(Group Relative Policy Optimization, GRPO)。除了基于规则的格式和准确性奖励外,我们还提出了针对具身推理任务量身定制的新型推理过程奖励,以缓解奖励欺骗并增强推理过程与最终答案之间的逻辑一致性。
3.3.1 分组相对策略优化
对于给定的查询 q q q和语义标注 s s s,GRPO使用参考策略 π ref \pi_{\text{ref}} πref生成一组输出 { o 1 , o 2 , … , o G } \{o_1, o_2, \ldots, o_G\} {o1,o2,…,oG}。参考策略通常指未经GRPO训练的原始模型。然后通过优化以下目标更新策略模型 π θ \pi_\theta πθ:
J ( θ ) = E ( q , s ) ∼ D , { o i } i = 1 G ∼ π old ( o ∣ q , s ) [ 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q , s ) π old ( o i ∣ q , s ) A i , clip ( π θ ( o i ∣ q , s ) π old ( o i ∣ q , s ) , 1 − ϵ , 1 + ϵ ) A i ) − β D KL ( π θ ∥ π ref ) ) ] J(\theta) = \mathbb{E}_{(q,s)\sim D,\{o_i\}^G_{i=1}\sim\pi_{\text{old}}(o|q,s)}\left[\frac{1}{G}\sum^{G}_{i=1}\left(\min\left(\frac{\pi_\theta(o_i|q, s)}{\pi_{\text{old}}(o_i|q, s)}A_i, \text{clip}\left(\frac{\pi_\theta(o_i|q, s)}{\pi_{\text{old}}(o_i|q, s)}, 1 - \epsilon, 1 + \epsilon\right)A_i\right) - \beta D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}})\right)\right] J(θ)=E(q,s)∼D,{oi}i=1G∼πold(o∣q,s)[G1i=1∑G(min(πold(oi∣q,s)πθ(oi∣q,s)Ai,clip(πold(oi∣q,s)πθ(oi∣q,s),1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref))]
其中 ϵ \epsilon ϵ和 β \beta β是超参数, D KL ( π θ ∥ π ref ) D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) DKL(πθ∥πref)是KL散度惩罚: D KL ( π θ ∥ π ref ) = π ref ( r i ∣ q , s ) log π ref ( r i ∣ q , s ) π θ ( r i ∣ q , s ) − 1 D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) = \pi_{\text{ref}}(r_i|q, s) \log \frac{\pi_{\text{ref}}(r_i|q,s)}{\pi_\theta(r_i|q,s)} - 1 DKL(πθ∥πref)=πref(ri∣q,s)logπθ(ri∣q,s)πref(ri∣q,s)−1。 A i A_i Ai表示与输出 o i o_i oi对应的优势,从对应的 { r 1 , r 2 , … , r G } \{r_1, r_2, \ldots, r_G\} {r1,r2,…,rG}计算: A i = r i − mean ( { r 1 , r 2 , . . . , r G } ) std ( { r 1 , r 2 , . . . , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1,r_2,...,r_G\})}{\text{std}(\{r_1,r_2,...,r_G\})} Ai=std({r1,r2,...,rG})ri−mean({r1,r2,...,rG})。
3.3.2 奖励建模
奖励建模是RL算法的关键组件,因为其设计引导模型优化方向。我们提出三种奖励类型:格式奖励、准确性奖励和逻辑一致性奖励。这些奖励分别设计用于引导模型学习"思考-回答"推理模式、准确的具身空间推理和推理与答案之间的逻辑一致性。
格式奖励:我们的目标是让模型首先生成具身推理过程 p i p_i pi,然后给出最终答案 a i a_i ai。推理过程和答案分别封装在<think></think>和<answer></answer>标签中:
请扮演一个智能体的角色。给定一个问题和一系列帧,你应首先思考推理过程,然后提供最终答案。推理过程和答案分别封装在<think>和<answer></answer>标签中,如:<think>此处为推理过程</think><answer>此处为答案</answer>。
确保你的答案与思考过程一致且直接从中推导出,保持两部分之间的逻辑连贯性。这些帧代表你从过去到现在的自我中心观察。问题: q q q。视频: f ′ f' f′。助手:
应用正则表达式评估 o i o_i oi是否满足指定要求,从而生成格式奖励 r i ′ r'_i ri′:
r i ′ = { 1 , 如果格式正确 ; 0 , 如果格式不正确 . r'_i = \begin{cases} 1, & \text{如果格式正确}; \\ 0, & \text{如果格式不正确}. \end{cases} ri′={1,0,如果格式正确;如果格式不正确.
准确性奖励:准确性奖励模型 r i ′ ′ r''_i ri′′评估答案 a i a_i ai是否在语义上与真实答案 g g g一致。例如,多项选择题通常具有精确且唯一的答案,当响应遵循指定格式时容易提取。
r i ′ ′ = { 1 , a i = g ; 0 , a i ≠ g . r''_i = \begin{cases} 1, & a_i = g; \\ 0, & a_i \neq g. \end{cases} ri′′={1,0,ai=g;ai=g.
逻辑一致性奖励:当仅使用格式奖励和准确性奖励时,我们一致观察到欺骗行为。具体而言,对于可能答案有限的空间推理任务(如物体相对于智能体身体的相对位置),出现了错误推理过程 p i p_i pi导致正确答案 a i a_i ai的情况,这被错误地分配了正奖励。随着此类案例积累,模型响应的逻辑一致性恶化。为解决这一问题,我们引入了一个简单而有效的过程奖励。我们的目标是确保逻辑一致性的下限,使得 π θ \pi_\theta πθ的推理能力不应低于参考模型 π ref \pi_{\text{ref}} πref。因此,当模型的答案正确时( a i = g a_i = g ai=g),我们将问题 q q q和推理过程 p i p_i pi输入参考模型而不提供视频帧,得到一个答案:
a i ′ ∼ π ref ( a ∣ q , p i ) a'_i \sim \pi_{\text{ref}}(a|q, p_i) ai′∼πref(a∣q,pi)
如果 a i ′ a'_i ai′与 a i a_i ai一致,表明推理过程可以逻辑地导致答案;否则,反映了推理过程与答案之间的逻辑不一致。
r i ′ ′ ′ = { 1 , a i = a i ′ = g ; 0 , 其他情况 . r'''_i = \begin{cases} 1, & a_i = a'_i = g; \\ 0, & \text{其他情况}. \end{cases} ri′′′={1,0,ai=ai′=g;其他情况.
总奖励:总奖励是上述三种奖励的线性组合:
r i = ω 1 r i ′ + ω 2 r i ′ ′ + ω 3 r i ′ ′ ′ r_i = \omega_1 r'_i + \omega_2 r''_i + \omega_3 r'''_i ri=ω1ri′+ω2ri′′+ω3ri′′′
4. 实验
4.1 实验设置
研究主要关注三维物理空间运动中的推理问题,选用两个主要数据集:
- UrbanVideo-Bench:无人机航拍的室外数据
- VSI-Bench:室内第一人称导航数据
从每个数据集中选取四种任务类型,具有长推理链和低准确率特点。Embodied-R的基座模型为:
- VLM:Qwen2.5-VL-72B-Instruct
- LLM:Qwen2.5-3B-Instruct
4.2 实验结果
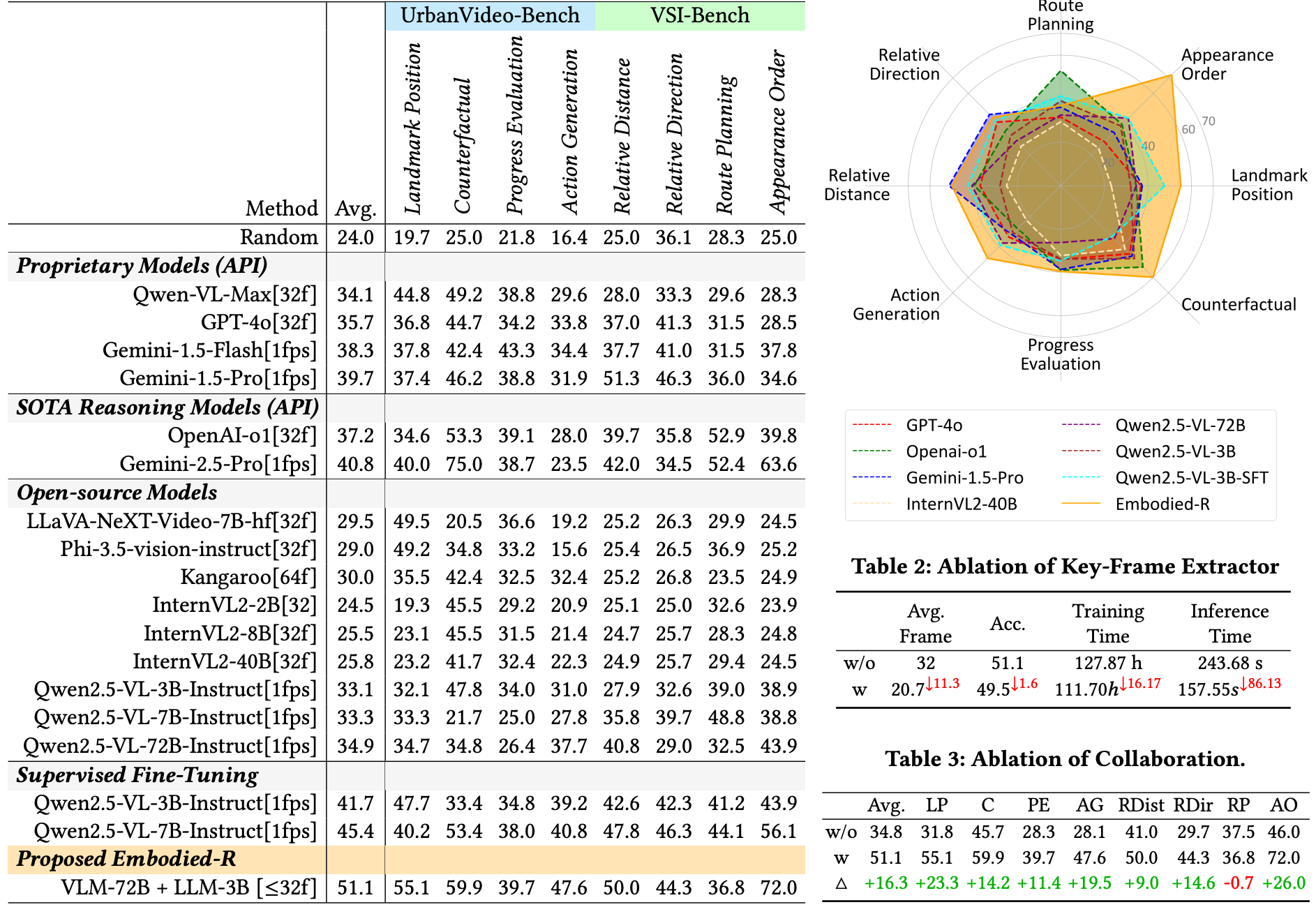
- Embodied-R的推理增强模型在性能上显著优于现有模型
- 相比商用多模态大模型提升超10%
- 相比SFT训练模型提升5%以上
5. 结论与思考
-
推理能力、Aha Moment与回答长度的关系:
- 在具身空间推理任务中,简洁推理模式可能比冗长的推理过程更有效
- LM训练趋于最优文本输出分布,不一定需要长文本推理
-
直接对VLMs进行RL训练的效果:
- 尝试对Qwen2.5-VL-3B-Instruct模型直接RL训练,相似参数和时间下表现远逊于LM
- VLM感知能力有限,制约推理提升
-
奖励设计的重要性:
- 仅使用准确率和格式奖励会导致模型产生奖励欺骗行为
- 逻辑一致性奖励能显著提升推理与答案的一致性,将逻辑一致输出比例从46.01%提升至99.43%
-
RL与SFT训练模型的泛化能力:
- 在分布外数据集测试中,RL训练模型普遍表现更好
- Embodied-R在EgoSchema数据集表现媲美Gemini-2.5-Pro
- RL可能是比SFT更具泛化能力的训练方式