用 GRPO 魔法点亮Text2SQL 的推理之路:让模型“思考”得更像人类
推理能力(Chain of Thought, CoT)可以帮助模型逐步解释其思考过程,从而提高Text-to-SQL 生成的准确性和可解释性。本文探讨了如何将一个标准的 7B 参数的大型语言模型(Qwen2.5-Coder-7B-Instruct)转变为一个能够为Text-to-SQL 任务提供结构化推理的模型,使用的技术是 GRPO(Guided Reward Policy Optimization)。重点在于设计有效的奖励函数,鼓励模型正确推理并生成准确的 SQL。
为什么 GRPO 非常适合Text-to-SQL?
你可能已经对 GRPO(引导式奖励策略优化)有所了解,这是 DeepSeek 为训练其 R1 推理模型而引入的一种强化学习技术。在众多应用场景中,文本到 SQL 是 GRPO 细调的绝佳选择,原因如下:
推理很重要 SQL 不仅仅是语法,它是结构化的逻辑。GRPO 鼓励模型解释为什么选择某些表、连接或过滤条件,训练它们像人类分析师一样“思考”,从而更贴近用户意图。
它能捕捉到隐性错误 如果没有推理,模型可能会在问题为“上个月活跃用户”时返回 SELECT * FROM users。GRPO 的双重奖励系统(推理 + SQL)可以帮助早期发现这些微妙的不匹配。
小模型需要引导 小型模型(如 7B)通常在处理复杂逻辑时会遇到困难。GRPO 就像是训练轮子:它奖励连贯的逐步思考,并惩罚逻辑不合理的输出,即使 SQL 看起来没问题。
通过透明度建立信任 如果模型写到:“我使用了 purchases 表,因为问题涉及销售”,那么调试和验证就会变得更加容易。GRPO 将这种清晰性直接融入训练循环中。
但要实现这一点,奖励设计至关重要
文本到 SQL 推理的挑战在于创建有效的奖励函数,这些函数既要评估解释的质量,又要评估生成的 SQL 的准确性。
为推理基础的细调设计奖励函数
为了在文本到 SQL 生成中实现结构化推理,我创建了多部分奖励函数,每个函数都捕捉模型行为的一个关键方面。这些奖励函数被用于通过 Unsloth 框架对 7B 模型进行细调。
每个函数在塑造模型的推理能力和 SQL 准确性方面都发挥着独特的作用:
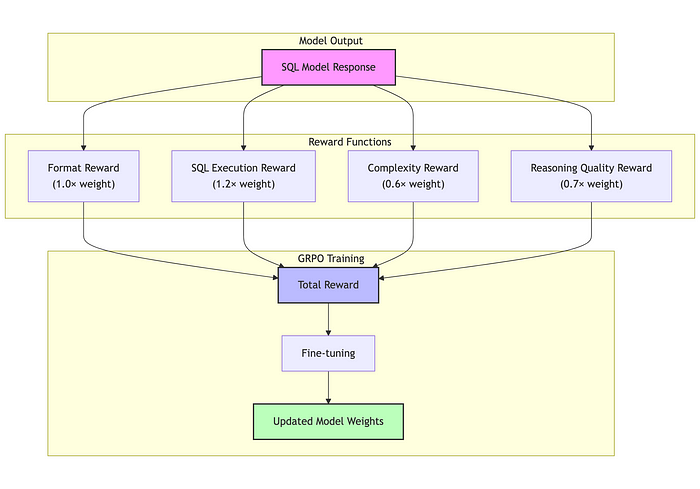
soft_format_reward_func(权重:1.0)
这个简单的函数检查完成内容是否符合软模式:<reasoning>(.*?)</reasoning>\s*<sql>(.*?)</sql>
如果匹配,则返回完整的 format 奖励权重(默认值为 1.0),否则返回 0。
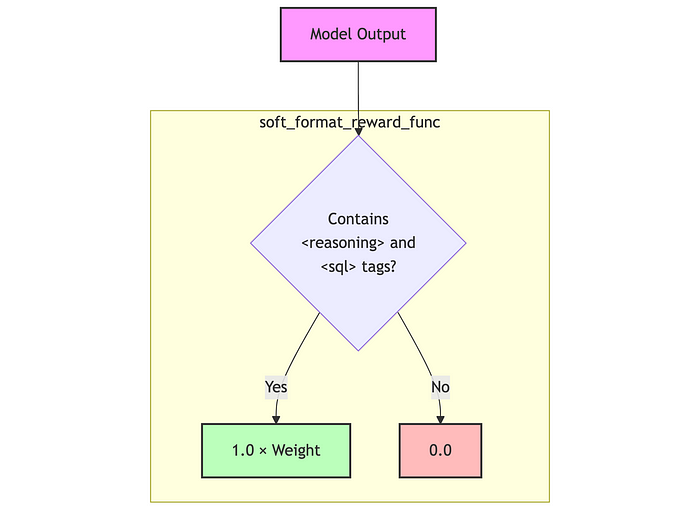
complexity_reward(权重:0.6)
这个函数确保 SQL 的复杂度与目标 SQL(答案)一致,避免过度或不足的复杂性。
如果没有目标 SQL:
- 如果复杂度在 [1.5, 8.0] 范围内,则返回 0.4 *
complexity_weight,否则返回 0.1 *complexity_weight
如果有目标 SQL,则奖励计算公式为:
reward = exp ( − 0.5 × ( log ( ratio ) ) 2 ) × complexity_weight \text{reward} = \exp(-0.5 \times (\log(\text{ratio}))^2) \times \text{complexity\_weight} reward=exp(−0.5×(log(ratio))2)×complexity_weight
其中,ratio = gen_complexity / gold_complexity(限制在 [0.001, 1000] 范围内),使用 高斯相似性 对数比率进行计算。
最终奖励值由 complexity 权重(默认值为 0.6)缩放。
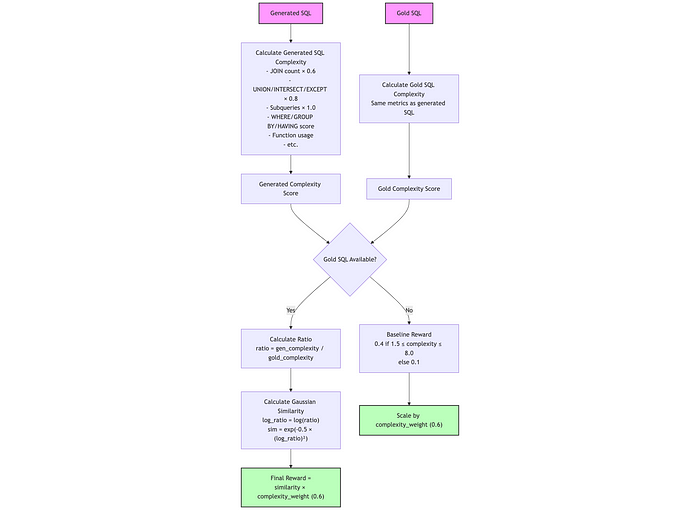
reasoning_quality_reward(权重:0.7)
这个奖励函数评估模型生成的 推理部分 的质量,使用一组启发式规则来反映类似人类的分析性思维。
reward = min ( 1.0 , ∑ ( c o m p o n e n t _ s c o r e s ) ) × r e a s o n i n g _ w e i g h t \text{reward} = \min(1.0, \sum(component\_scores)) \times reasoning\_weight reward=min(1.0,∑(component_scores))×reasoning_weight
组件得分如下:
- 长度:如果推理部分≥50 个单词,得 0.20 分;≥25 个单词,得 0.15 分;≥10 个单词,得 0.10 分;否则得 0 分。
- SQL 术语:得分不超过 0.20,具体为
term_count \* 0.03。 - 结构:如果推理部分≥3 行,得 0.15 分;≥2 行,得 0.10 分;否则得 0 分。
- 步骤指示:如果提到了初始步骤和后续步骤,则得 0.15 分。
- 模式引用:得分不超过 0.30,具体为
total_mentions \* 0.05。
最终奖励值由 reasoning 权重(默认值为 0.7)缩放。
execute_query_reward_func(权重:1.2)
基于执行的评估,执行奖励是最重要的部分。它测试生成的 SQL 是否能够正常运行并产生正确的结果:
- 基础奖励:如果语句类型匹配,则返回 0.1 *
sql_correctness_weight。 - 对于
SELECT语句:- 如果执行成功,则返回 0.3 *
sql_correctness_weight。 - 如果结果完全匹配,则返回完整的
sql_correctness_weight。 - 对于部分匹配:
- 如果列集相同,则计算 Jaccard 相似度:
Jaccard = ∣ g o l d _ r o w s ∩ g e n _ r o w s ∣ ∣ g o l d _ r o w s ∪ g e n _ r o w s ∣ \text{Jaccard} = \frac{|gold\_rows \cap gen\_rows|}{|gold\_rows \cup gen\_rows|} Jaccard=∣gold_rows∪gen_rows∣∣gold_rows∩gen_rows∣ - 如果列不同:
- 找出目标结果和生成结果之间的公共列。
- 将两组结果投影到仅包含公共列。
- 计算 Jaccard 相似度:
Jaccard = ∣ g o l d _ p r o j e c t e d ∩ g e n _ p r o j e c t e d ∣ ∣ g o l d _ p r o j e c t e d ∪ g e n _ p r o j e c t e d ∣ \text{Jaccard} = \frac{|gold\_projected \cap gen\_projected|}{|gold\_projected \cup gen\_projected|} Jaccard=∣gold_projected∪gen_projected∣∣gold_projected∩gen_projected∣ - 如果没有公共列,则 Jaccard = 0。
- 部分奖励计算公式为:
max ( b a s e _ r e w a r d , 0.5 × s q l _ c o r r e c t n e s s _ w e i g h t × s i m i l a r i t y ) \max(base\_reward, 0.5 \times sql\_correctness\_weight \times similarity) max(base_reward,0.5×sql_correctness_weight×similarity)
- 如果列集相同,则计算 Jaccard 相似度:
- 如果执行成功,则返回 0.3 *
- 对于 DML 语句(
INSERT、UPDATE、DELETE):- 如果执行成功,则返回 0.5 *
sql_correctness_weight。 - 如果执行需要修正大小写,则返回 0.4 *
sql_correctness_weight。
- 如果执行成功,则返回 0.5 *
错误处理:
- 将 SQL 错误分类为不同类型(语法错误、缺少表等)。
- 根据错误严重性分配部分分数(0.0–0.2 *
sql_correctness_weight)。 - 对于小问题(如模糊列名:0.2 分)给予更多分数。
- 对于结构错误(语法错误:0.0 分)给予较少分数。
所有奖励值由 sql_correctness 权重(默认值为 1.2)缩放。
在 GRPO 训练过程中,这些奖励函数指导模型同时实现以下目标:
- 保持正确的格式(基本要求)。
- 生成语法正确且功能正常的 SQL(最高优先级)。
- 提供清晰、结构化的推理,并引用模式元素。
- 匹配预期的 SQL 复杂度。
这种平衡的方法确保模型同时发展强大的推理能力和 SQL 准确性,而不是仅优化单一维度的性能。
在 GRPO 训练中的实现
以下是使用 Unsloth 设置这些奖励函数与 GRPO 训练器的代码:
from trl import GRPOConfig, GRPOTrainer# 配置训练
training_args = GRPOConfig(use_vllm = True,learning_rate = 5e-6,per_device_train_batch_size = 1,gradient_accumulation_steps = 1,num_generations = 8,max_prompt_length = 256,max_completion_length = 200,max_steps = 250,output_dir = "outputs",...
)trainer = GRPOTrainer(model = model,processing_class = tokenizer,reward_funcs = [soft_format_reward_func,execute_query_reward_func,reasoning_quality_reward,complexity_reward,],args = training_args,train_dataset = dataset,
)trainer.train()
系统提示应该明确指示模型使用推理:
你是一个将自然语言问题转换为 SQL 查询的 AI 助手。
给定一个数据库模式和一个问题,生成正确的 SQL 查询。请仅按照以下格式进行响应,包括 <reasoning> 和 <sql> 标签:
<reasoning>
逐步思考以理解数据库模式和问题。
确定必要的表、列、连接和条件。
解释构建 SQL 查询的逻辑。
</reasoning>
<sql>
-- 你的 SQL 查询在这里
</sql>
评估奖励系统的有效性
为了评估我们多维度奖励函数的有效性,我使用了 LLM-as-a-Judge 来评估经过细调的模型在 SQL 正确性和推理质量方面的表现。
经过细调的 Qwen2.5-Coder-7B-Instruct 模型使用 GPT-4o-mini 作为专家评委进行评估:
-
评估数据集:从评估数据集中随机选择的 50 个示例。
-
评估维度:四个关键方面,评分范围为 1–5:
- SQL 正确性:生成的 SQL 的准确性和有效性。
- 推理质量:推理的清晰度和正确性。
- 格式遵循:是否正确使用推理和 SQL 标签。
- 教育价值:是否有助于学习 SQL 概念。
评估提示:
作为一名 SQL 专家,请评估这段文本到 SQL 的转换。每个维度的评分范围为 1-5(1=差,5=优秀)。数据库模式:{sample['sql_context']}问题:{sample['sql_prompt']}正确的 SQL(目标):{sample['sql']}模型输出:{sample['model_output']}请按照以下格式提供评分:SQL_SCORE: [1-5] - SQL 是否能够正常运行并产生正确结果?REASONING_SCORE: [1-5] - 推理是否清晰、逻辑正确且引用了正确的模式?FORMAT_SCORE: [1-5] - 是否遵循 <reasoning>...</reasoning><sql>...</sql> 格式?EDUCATIONAL_SCORE: [1-5] - 是否有助于学习 SQL?OVERALL_SCORE: [平均值]EXPLANATION: [简要说明优点和缺点]ERROR_TYPE: [none/syntax/logic/format/other]
结果
经过仅 300 个示例和 250 步训练的细调模型取得了不错的评估结果:
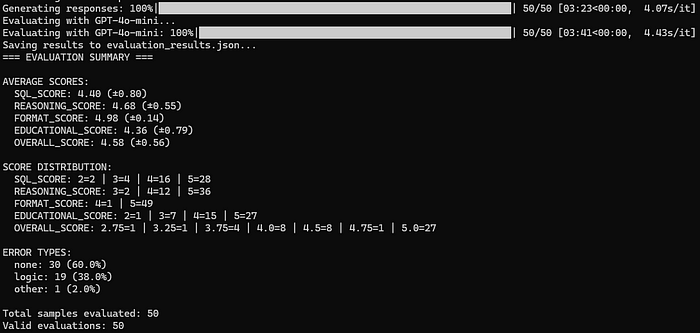
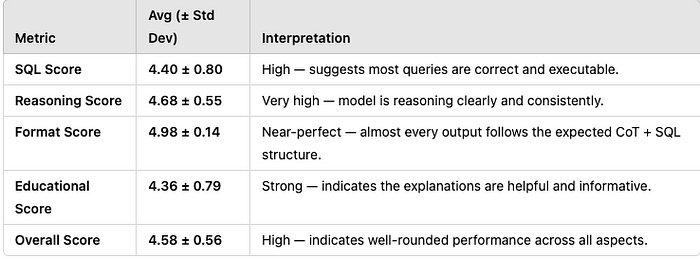
该模型在 SQL 生成方面表现出色(50 个样本中有 44 个得分在 4 或 5 之间),推理质量优秀(50 个样本中有 48 个得分在 4 或 5 之间),格式遵循近乎完美(50 个样本中有 49 个得分在 5),并且具有明确的教育价值。总体而言,88% 的输出得分在 4.0 或更高,反映出模型结果的一致性、结构化和可解释性。
结论
我创建的推理奖励函数在细调过程中表现可靠,并产生了连贯的结果。你可以探索完整的实现代码,并自行尝试,源代码可在 GitHub 上找到。
from Yi_Ai yai333/Text-to-SQL-GRPO-Fine-tuning-Pipeline:main