学习Python网络爬虫的实例
30岁程序员学习Python的第二天之网络爬虫的练习实例
爬取软科2025年中国大学排名
思路:
1、百度查到到网页地址:https://www.shanghairanking.cn/rankings/bcur/2025
2、编写爬取代码,具体步骤分3步,第一步通过requests库爬取网页全部信息。第二步将爬取的网页信息通过BeautifulSoup库进行解析,确定名单的标签组成结构,并将名单主体内容按数组的方式进行存储。第三步将数组内容按格式打印输出。
import bs4
import requests
from bs4 import BeautifulSoup#获取html页面
def get_html(url):try:r = requests.get(url,timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""#查到HTML中大学排名名单
def findUnivList(ulist,html):soup = BeautifulSoup(html, 'html.parser')for td in soup.find('tbody').children:if isinstance(td, bs4.element.Tag):tds = td('td')ulist.append([tds[0].div.string.replace(' ','').replace('\n',''), tds[1].find_all('span',attrs='name-cn')[0].string.replace(' ','').replace('\n',''), tds[2].text.replace(' ','').replace('\n',''),tds[4].string.replace(' ','').replace('\n','')])#将大学排名榜单进行打印
def printUnviList(ulist,num):tplt = "{:^10}\t{:^10}\t{:^10}\t{:^10}"print(tplt.format("排名","学校名称","省市","总分",chr(12288)))for i in range(num):u = ulist[i]print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))if __name__ == '__main__':#2025年国内大学排名网站ulist=[]url = "https://www.shanghairanking.cn/rankings/bcur/2025"html = get_html(url)findUnivList(ulist,html)printUnviList(ulist,20)
运行结果:
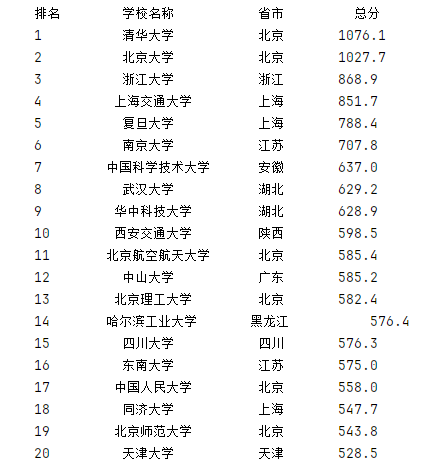
总结:在编写代码的过程中,遇到的第一个问题是程序提示TypeError: unsupported format string passed to NoneType.__format__错误,经过百度核查发现是,格式化输出时,由于该位置对应的内容为None,程序就会提示该错误。一层一层分析,发现造成该报错的实际原因是,解析获取大学所属省市时,用的tds[2].string的形式,由于省市所在的td标签中除了具体省市外还存在注释内容,导致string不知道该返回那个数据而将None返回。