2、Kafka Replica机制与ISR、HW、LEO、AR、OSR详解
Kafka 作为分布式高可用消息队列,其副本(Replica)机制是实现高可靠性和数据一致性的核心。本文将系统介绍 Kafka 的 Replica 机制,并详细解释 ISR、HW、LEO、AR、OSR 等关键概念。
一、Kafka Replica机制概述
在分布式系统中,高可用是一个无法回避的重要问题。Kafka 通过副本机制实现高可用。
在创建 Topic 时,可以指定副本数(至少一个副本)。例如,创建一个 Topic,指定 3 个分区和 3 个副本,这样每个分区都有 3 个副本。Kafka 会根据一定策略,将每个分区的副本分布在不同的 Broker 上,并为每个分区选举出一个 leader,其余为 follower。
当某个 Broker 宕机时,会触发分区副本选举机制,从剩余的副本中选举出新的 leader,保证服务的持续可用。
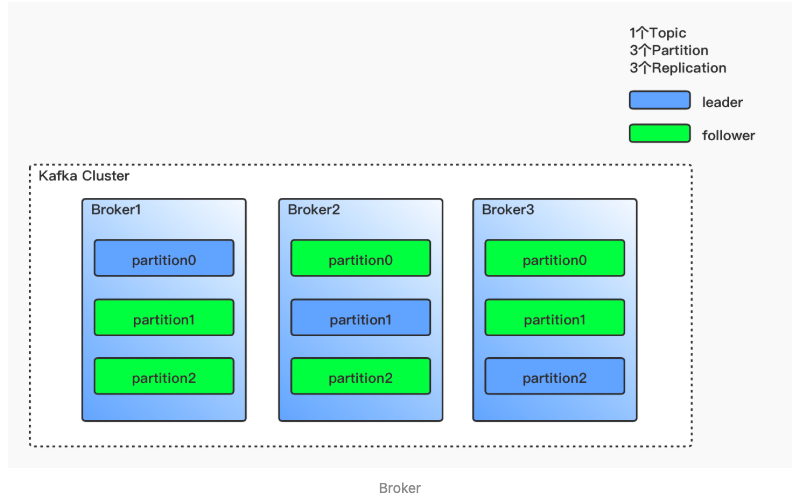
副本分为两类:
- Leader Replica:负责处理所有读写请求。
- Follower Replica:从 Leader 同步数据,作为备份。
副本机制的主要作用:
- 保证数据高可用,防止单点故障。
- 支持故障转移,提升系统容错能力。
二、AR、ISR、OSR 概念
- AR(Assigned Replicas):分区所有分配的副本集合,包括 Leader 和所有 Follower,即分区中的所有副本。
- ISR(In-Sync Replicas):所有与 Leader 副本保持一定程度同步的副本集合。
- OSR(Out-of-Sync Replicas):与 Leader 副本同步滞后过多的副本集合。
由此可见,AR = ISR + OSR。
Leader 副本负责维护和跟踪 ISR 集合中所有 Follower 副本的滞后状态:
- 当 Follower 副本落后太多或失效时,Leader 会将其从 ISR 集合中剔除,转入 OSR。
- 如果 OSR 集合中的 Follower 副本追上了 Leader,Leader 会将其从 OSR 集合转移回 ISR 集合。
- 默认情况下,当 Leader 副本发生故障时,只有 ISR 集合里的副本才有资格被选举为新的 Leader。
三、ISR 机制详解
ISR(In-Sync Replicas)是 Kafka 保证数据可靠性的关键。只有 ISR 内的副本才参与高水位(HW)推进和 Leader 选举。
- 当 Follower 长时间未同步数据或宕机,会被移出 ISR,进入 OSR。
- Follower 恢复并追上 Leader 后,会重新加入 ISR。
四、HW(High Watermark)与 LEO(Log End Offset)

- LEO(Log End Offset):它标识当前日志文件中下一条待写入消息的 offset,即每个副本当前日志的最大 offset。
- HW(High Watermark):高水位,标识一个特定的消息偏移量 offset,消费者只能拉取到这个 offset 之前(包含该 offset)的消息。HW 是所有 ISR 副本中最小的 LEO。
举例说明:
- 假设 ISR 中有三个副本,LEO 分别为 8、4、6,则 HW=4。
- 新写入的消息只有在所有 ISR 副本都同步后,HW 才会推进。
为什么消费者只能拉取到 HW 之前的消息?
Kafka 规定,消费者只能拉取到高水位(HW, High Watermark)之前(包含 HW)的消息。HW 是所有 ISR(In-Sync Replicas)副本中最小的 LEO。也就是说,只有当一条消息被所有"健康"的副本(ISR 集合)都成功复制后,这条消息才对消费者可见。
这样设计的出发点和好处
-
保证数据可靠性与一致性
如果允许消费者读取还未被所有副本同步的消息,一旦 leader 副本宕机,而这些消息还未同步到其他副本,就会造成数据丢失。消费者可能已经消费了这些"未同步"的消息,但这些消息在集群中实际上已经丢失,导致数据不一致和业务风险。 -
防止"脏读"
只有同步到所有 ISR 副本的消息才被认为是"已提交",对消费者可见。这样可以防止消费者读取到尚未被集群多数副本确认的数据,避免了"脏读"问题。 -
提升系统容错性
当 leader 副本发生故障时,Kafka 会从 ISR 集合中选举新的 leader。由于 HW 之前的消息已经被所有 ISR 副本同步,无论哪个副本成为新的 leader,都能保证数据完整性和一致性。 -
权衡性能与可靠性
这种机制既保证了高可用和高可靠性,又不会像强同步复制那样极大影响性能。只有 ISR 内副本同步后才推进 HW,既能保证数据安全,又能兼顾吞吐量。
总结:
Kafka 通过 HW 机制,确保了只有"真正安全"的消息才会被消费者读取,极大提升了分布式消息系统的数据一致性和可靠性。这是 Kafka 能够在大规模分布式场景下广泛应用的重要基础。
五、Replica机制的意义
- 保证数据不丢失:只有同步到 ISR 的消息才对外可见。
- 容错性强:Leader 故障时,从 ISR 中选举新的 Leader。
- 支持高并发和高可用。
由此可见,Kafka 的复制机制既不是完全的同步复制,也不是单纯的异步复制。
- 同步复制要求所有可用 follower 副本都复制完毕,消息才算提交成功,这会极大影响性能。
- 异步复制则只要 leader 副本写入即算提交,性能高但可靠性差,leader 宕机时可能丢数据。
- Kafka 采用的 ISR 机制则有效权衡了数据可靠性和性能:只有 ISR 集合内的副本都同步后,消息才被确认提交,既保证了高可用,也兼顾了吞吐性能。
六、Producer消息确认机制与副本同步参数
在副本机制下,生产者(Producer)向 Topic 发送消息,如何判定消息发送成功?
在一般分布式系统中,常用"过半提交"方式(即一半以上副本确认才算提交成功),但 Kafka 并未采用这种机制。Kafka 通过以下参数配置保障消息可靠性与性能:
Producer端 acks 参数
- acks=0:生产者只要将消息发送出去,无需等待任何副本的确认,即算发送成功。此方式吞吐量最大、性能最好,但 Kafka 服务抖动时容易丢消息。
- acks=1(默认):生产者将消息发送出去,只需副本中的 leader 确认,即算发送成功。此方式吞吐量和性能优秀,但当 leader 挂掉时会造成小部分消息丢失。
- acks=all:生产者将消息发送出去,需要 ISR 中的所有副本全部确认,才算发送成功。此方式吞吐量和性能较低,但稳定性最高,消息不容易丢失。
Broker端 replica.lag.time.max.ms 参数
- 如果某个 follower 在指定时间内没有发送 fetch 请求,或未能追上 leader 的日志末尾 offset,leader 会将其从 ISR 集合中剔除。
- 该参数用于控制副本同步的最大允许延迟,保障 ISR 集合的健康和数据可靠性。
七、Consumer消费机制与分区分配
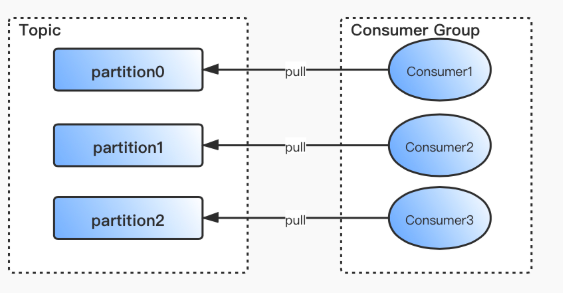
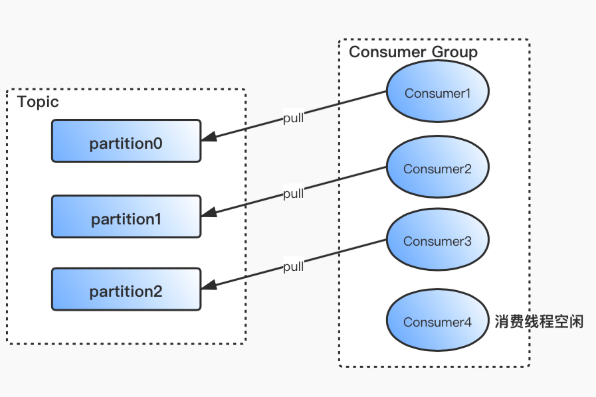
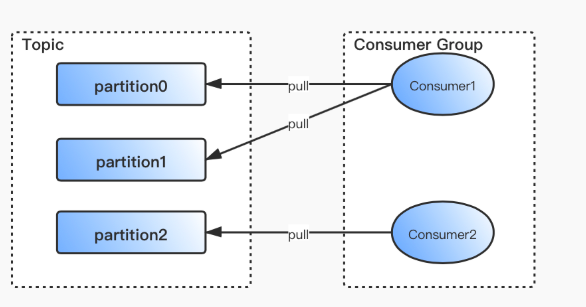
在 Kafka 中,1 个 Partition 只能被 1 个消费线程消费。Kafka 采用消费者主动 pull 数据的模式,而非 Kafka Server 主动 push,这样消费者可以根据自身消费能力灵活拉取数据。如果出现消息堆积,也便于开发人员及时管理和扩容消费者。
- 如果消费线程数大于分区数,多余的消费线程将处于空闲状态。
- 如果消费线程数小于分区数,部分消费线程会消费多个分区的数据。
- 如果消费线程数等于分区数,则每个消费线程对应一个分区,是最理想的情况。
这种设计的好处:
- offset 偏移量管理简单,易于追踪和恢复。
- 消费数据的分配及 offset 提交无需复杂的事务保障,提升了系统效率。
- 便于横向扩展和动态调整消费者数量。
八、Offset提交机制的演变
由于消费者是主动 pull 数据,因此每个分区的 offset 由对应的消费者线程维护,每个消费线程需要记录自己消费到当前分区的偏移量 offset。
- 在早期 Kafka 版本中,每个分区的 offset 由对应的消费线程维护在 Zookeeper 上。但由于 Zookeeper 的单节点写特性(只有 leader 能处理写请求),不适合大量数据的频繁写入,导致性能瓶颈。
- 后续 Kafka 版本中,offset 的存储方式进行了优化,每个分区的 offset 由对应的消费线程维护在 Kafka 内部的
__consumer_offsets主题中,极大提升了 offset 提交的效率和系统的可扩展性。