Milvus(14):更改 Collections 字段、Schema 设计实践
1 更改 Collections 字段
可以更改 Collections 字段的属性,以更改列约束或执行更严格的数据完整性规则。
- 每个 Collection 只包含一个主字段。一旦在创建 Collections 时设置,就不能更改主字段或改变其属性。
- 每个 Collection 只能有一个 Partition Key。一旦在创建 Collections 时设置,就不能更改分区键。
1.1 更改 VarChar 字段
VarChar 字段有一个名为max_length 的属性,用于限制字段值可包含的最大字符数。您可以更改max_length 属性。下面的示例假定 Collections 有一个名为varchar 的 VarChar 字段,并设置了它的max_length 属性。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)client.alter_collection_field(collection_name="my_collection",field_name="varchar",field_params={"max_length": 1024}
)1.2 更改 ARRAY 字段
数组字段有两个属性,即element_type 和max_capacity 。前者决定数组中元素的数据类型,后者限制数组中元素的最大数量。您只能更改max_capacity 属性。下面的示例假定 Collections 有一个名为array 的数组字段,并设置了它的max_capacity 属性。
client.alter_collection_field(collection_name="my_collection",field_name="array",field_params={"max_capacity": 64}
)1.3 更改字段级 mmap 设置
内存映射(Mmap)可实现对磁盘上大型文件的直接内存访问,允许 Milvus 在内存和硬盘中同时存储索引和数据。这种方法有助于根据访问频率优化数据放置策略,在不影响搜索性能的情况下扩大 Collections 的存储容量。下面的示例假定 Collections 有一个名为doc_chunk 的字段,并设置其mmap_enabled 属性。
client.alter_collection_field(collection="my_collection",field_name="doc_chunk",properties={"mmap.enabled": True}
)2 Schema 设计实践
信息检索(IR)系统,又称搜索引擎,是各种人工智能应用(如检索增强生成(RAG)、图像搜索和产品推荐)的关键。开发 IR 系统的第一步是设计数据模型,其中包括分析业务需求、确定如何组织信息以及为数据编制索引,使其具有语义可搜索性。
Milvus 支持通过 Collections Schema 定义数据模型。Collections 组织文本和图像等非结构化数据,以及它们的向量表示,包括用于语义搜索的各种精度的密集向量和稀疏向量。此外,Milvus 还支持存储和过滤称为 "标量 "的非向量数据类型。标量类型包括 BOOL、INT8/16/32/64、FLOAT/DOUBLE、VARCHAR、JSON 和数组。
搜索系统的数据模型设计包括分析业务需求,并将信息抽象为 Schema 表达的数据模型。例如,要搜索一段文本,必须通过 "embedding "将字面字符串转换为向量,实现向量搜索,从而对其进行 "索引"。除了这一基本要求外,可能还需要存储其他属性,如出版时间戳和作者。有了这些元数据,就可以通过过滤来完善语义搜索,只返回特定日期之后或特定作者发表的文本。它们可能还需要与主要文本一起检索,以便在应用程序中呈现搜索结果。为了组织这些文本片段,应该为每个片段分配一个唯一的标识符,用整数或字符串表示。这些元素对于实现复杂的搜索逻辑至关重要。
设计良好的 Schema 非常重要,因为它抽象了数据模型,并决定能否通过搜索实现业务目标。此外,由于插入 Collections 的每一行数据都需要遵循 Schema,因此大大有助于保持数据的一致性和长期质量。从技术角度来看,定义明确的 Schema 可以带来组织良好的列数据存储和更简洁的索引结构,从而提升搜索性能。
2.1 新闻搜索
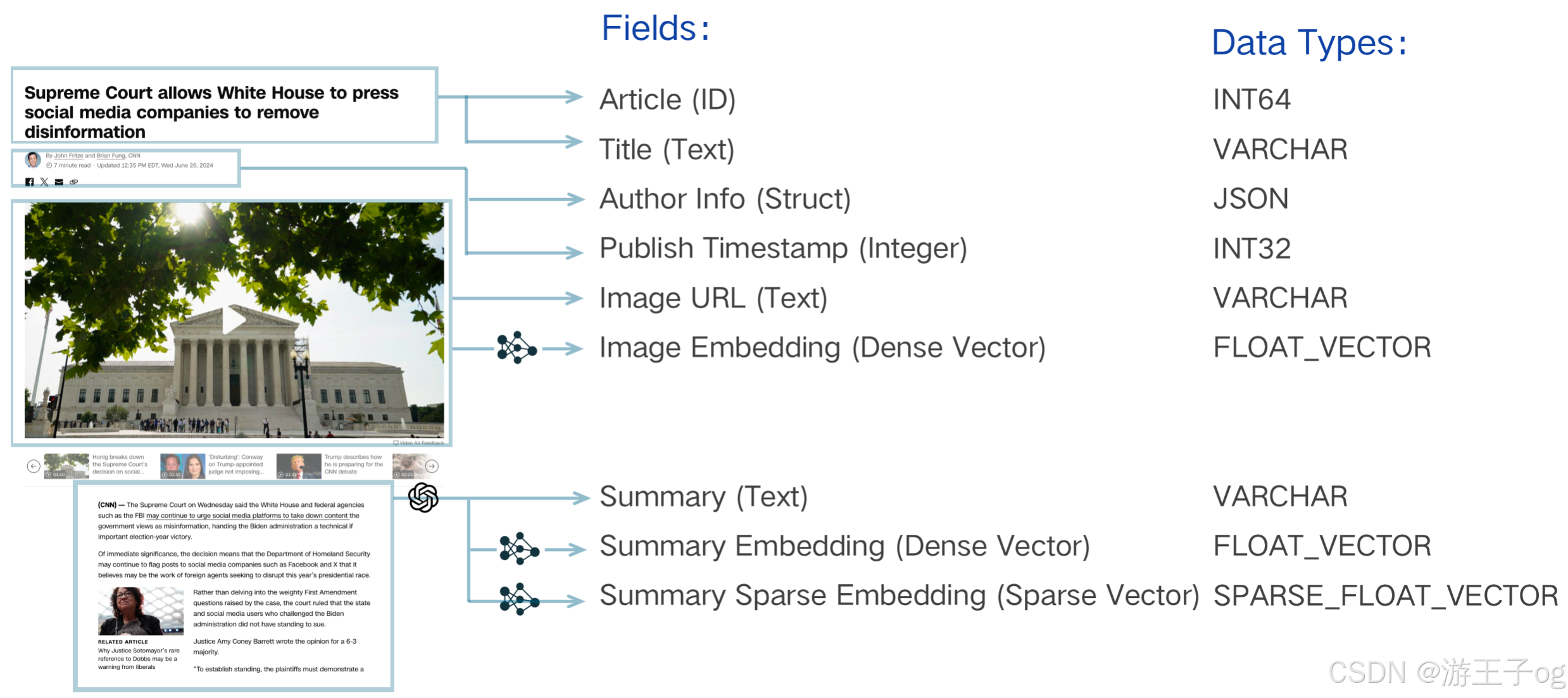
假设我们想为一个新闻网站建立搜索,我们有一个包含文本、缩略图像和其他元数据的新闻语料库。首先,我们需要分析如何利用这些数据来支持搜索的业务需求。试想一下,我们的需求是根据缩略图和内容摘要检索新闻,并将作者信息和发布时间等元数据作为过滤搜索结果的标准。这些需求可以进一步细分为
- 要通过文本搜索图片,我们可以通过多模态嵌入模型将图片嵌入向量,该模型可以将文本和图片数据映射到同一个潜空间。
- 通过文本嵌入模型将文章摘要文本嵌入向量。
- 为了根据发布时间进行过滤,日期被存储为一个标量字段,并且需要为标量字段建立一个索引,以实现高效过滤。其他更复杂的数据结构(如 JSON)也可以存储在标量中,并对其内容进行过滤搜索(即将推出 JSON 索引功能)。
- 为了检索图像缩略图字节并将其呈现在搜索结果页面上,还需要存储图像的 url。同样,摘要文本和标题也是如此。(如果需要,我们也可以将原始文本和图像文件数据存储为标量字段)。
- 为了改善摘要文本的搜索结果,我们设计了一种混合搜索方法。对于一种检索路径,我们使用常规嵌入模型从文本中生成密集向量,例如 OpenAI 的
text-embedding-3-large或开源的bge-large-en-v1.5。这些模型善于表现文本的整体语义。另一种路径是使用稀疏嵌入模型(如 BM25 或 SPLADE)生成稀疏向量,类似于全文检索,它善于把握文本中的细节和单个概念。由于 Milvus 的多向量功能,它支持在同一数据 Collections 中同时使用这两种向量。对多个向量的搜索可以在一次hybrid_search()操作符中完成。 - 最后,我们还需要一个 ID 字段来标识每个单独的新闻页面,在 Milvus 术语中正式称为 "实体"。这个字段被用作主键(简称 "pk")。
| 字段名称 | 文章 ID(主键) | 标题 | 作者信息 | 出版日期 | 图像URL | 图像向量 | 摘要 | 摘要密集向量 | 摘要稀疏向量 |
|---|---|---|---|---|---|---|---|---|---|
| 类型 | INT64 | VARCHAR | JSON | INT32 | VARCHAR | FLOAT_VECTOR | VARCHAR | FLOAT_VECTOR | 稀疏浮点型向量 |
| 需要索引 | N | N | N(即将提供支持) | Y | N | Y | N | Y | Y |
2.2 实施示例 Schema
2.2.1 创建 Schema
首先,我们创建一个 Milvus 客户端实例,用于连接 Milvus 服务器并管理 Collections 和数据。为了建立模式,我们使用create_schema() 创建模式对象,并使用add_field() 为模式添加字段。
from pymilvus import MilvusClient, DataTypecollection_name = "my_collection"# client = MilvusClient(uri="http://localhost:19530")
client = MilvusClient(uri="./milvus_demo.db")schema = MilvusClient.create_schema(auto_id=False,
)schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=200, description="article title")
schema.add_field(field_name="author_info", datatype=DataType.JSON, description="author information")
schema.add_field(field_name="publish_ts", datatype=DataType.INT32, description="publish timestamp")
schema.add_field(field_name="image_url", datatype=DataType.VARCHAR, max_length=500, description="image URL")
schema.add_field(field_name="image_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="image vector")
schema.add_field(field_name="summary", datatype=DataType.VARCHAR, max_length=1000, description="article summary")
schema.add_field(field_name="summary_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="summary dense vector")
schema.add_field(field_name="summary_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="summary sparse vector") 您可能会注意到MilvusClient 中的参数uri ,它用于连接 Milvus 服务器。参数设置如下:
- 如果你只需要一个本地向量数据库,用于小规模数据或原型设计,那么将 uri 设置为本地文件,如
./milvus.db,是最方便的方法,因为它会自动利用Milvus Lite将所有数据存储在此文件中。 - 如果你有大规模数据,比如超过一百万个向量,你可以在 Docker 或 Kubernetes 上设置性能更强的 Milvus 服务器。在此设置中,请使用服务器地址和端口作为 uri,例如
http://localhost:19530。如果在 Milvus 上启用了身份验证功能,请使用 ":" 作为令牌,否则不要设置令牌。 - 如果您使用Zilliz Cloud(Milvus 的全托管云服务),请调整
uri和token,它们与 Zilliz Cloud 中的公共端点和 API 密钥相对应。
至于MilvusClient.create_schema 中的auto_id ,AutoID 是主字段的一个属性,用于决定是否启用主字段自动递增。 由于我们将字段article_id 设置为主键,并希望手动添加文章 id,因此我们将auto_id 设置为 False 以禁用此功能。将所有字段添加到 Schema 对象后,我们的 Schema 对象与上表中的条目一致。
2.2.2 定义索引
用各种字段(包括元数据和用于图像和摘要数据的向量字段)定义 Schema 后,下一步就是准备索引参数。索引对于优化向量的搜索和检索、确保高效查询性能至关重要。
index_params = client.prepare_index_params()index_params.add_index(field_name="image_vector",index_type="AUTOINDEX",metric_type="IP",
)
index_params.add_index(field_name="summary_dense_vector",index_type="AUTOINDEX",metric_type="IP",
)
index_params.add_index(field_name="summary_sparse_vector",index_type="SPARSE_INVERTED_INDEX",metric_type="IP",
)
index_params.add_index(field_name="publish_ts",index_type="INVERTED",
) 一旦设置并应用了索引参数,Milvus 就能优化处理向量和标量数据的复杂查询。这种索引增强了 Collections 内相似性搜索的性能和准确性,可根据图像向量和摘要向量高效检索文章。通过利用针对密集向量的AUTOINDEX 、针对稀疏向量的SPARSE_INVERTED_INDEX 和针对标量的INVERTED_INDEX ,Milvus 可以快速识别并返回最相关的结果,从而显著改善数据检索过程的整体用户体验和效率。
2.2.3 创建 Collections
定义好 Schema 和索引后,我们就可以用这些参数创建一个 "Collection"。对于 Milvus 来说,Collection 就像关系数据库中的表。
client.create_collection(collection_name=collection_name,schema=schema,index_params=index_params,
)我们可以通过描述集合来验证集合是否已成功创建。
collection_desc = client.describe_collection(collection_name=collection_name
)
print(collection_desc)2.3 其他注意事项
2.3.1 加载索引
在 Milvus 中创建 Collections 时,你可以选择立即加载索引,或者推迟到批量摄取一些数据之后再加载。通常情况下,您不需要对此做出明确的选择,因为上述示例显示,在创建 Collections 后,会立即为任何摄取的数据自动建立索引。这样就能立即搜索到采集的数据。不过,如果在创建 Collections 后有大量批量插入,并且在某一点之前不需要搜索任何数据,那么可以通过在创建 Collections 时省略 index_params 来推迟索引构建,并在摄取所有数据后通过显式调用 load 来构建索引。这种方法对于在大型 Collections 上建立索引更有效,但在调用 load() 之前不能进行任何搜索。
2.3.2 如何为多租户定义数据模型
多租户的概念通常用于单个软件应用程序或服务需要为多个独立用户或组织提供服务的情况,每个用户或组织都有自己的独立环境。这种情况经常出现在云计算、SaaS(软件即服务)应用和数据库系统中。例如,云存储服务可以利用多租户功能,允许不同公司分别存储和管理数据,同时共享相同的底层基础设施。这种方法可以最大限度地提高资源利用率和效率,同时确保每个租户的数据安全和隐私。
区分租户的最简单方法是将其数据和资源相互隔离。每个租户要么独享特定资源,要么与其他租户共享资源,以管理数据库、Collections 和分区等 Milvus 实体。有与这些实体相匹配的特定方法来实现多租户。