大模型基础(四):transformers库(上):pipline、模型、分词器
transformers库(上)
- 1 简介
- 2 pipeline函数
- 3 pipeline流程分解
- 3.1 分词
- 3.2 将预处理好的输入送入模型
- 3.3 对模型输出进行后处理
- 4 模型
- 4.1 Transformers 封装的常见模型类型
- 4.2 加载模型
- 4.3 保存模型
- 5 分词器
- 5.1 分词策略
- 5.1.1 按词切分(Word-based)
- 5.1.2 按字符切分 (Character-based)
- 5.1.3 按子词切分 (Subword)
- 5.2 加载与保存分词器
- 5.3 文本的编码与解码
- 5.3.1 文本编码
- 5.3.2 文本解码
- 6 处理多段文本
- 6.1 Batch 维度
- 6.2 Padding 操作
- 6.3 Attention Mask
- 6.4 直接使用分词器
- 6.5 指定返回值格式
- 6.6 编码句子对
- 7 总结
1 简介
🤗 Hugging Face Transformers 库 是一个用于自然语言处理(NLP)和计算机视觉(CV)的 开源深度学习库,以提供丰富的预训练模型和便捷的模型调用接口而闻名。以下是其核心要点:
核心功能
-
预训练模型支持
• 提供 数千种预训练模型(如 BERT、GPT、T5、ViT、Stable Diffusion 等),涵盖文本、图像、音频等多模态任务。
• 支持 PyTorch、TensorFlow 和 JAX 框架,可自由选择模型格式。 -
统一接口设计
• 通过AutoModel、AutoTokenizer等 自动类(Auto Classes)统一加载模型和分词器,无需手动指定架构。
• 高层pipeline()函数实现 零代码推理,适用于快速原型开发。 -
任务全覆盖
• NLP 任务:文本分类、问答、翻译、生成、摘要、实体识别等。
• CV 任务:图像分类、目标检测、图像生成(如 Stable Diffusion)等。
• 多模态任务:图文匹配、视觉问答等。
主要特点
• 开源社区驱动:依托 Hugging Face Hub 共享模型、数据集和演示应用。
• 即插即用:支持从本地或云端(Hugging Face Hub)直接加载模型。
• 灵活扩展:支持模型微调(Fine-tuning)、量化、分布式训练等高级用法。
• 多语言支持:涵盖 100+ 语言的预训练模型(如 XLM-R、mT5)。
典型应用场景
- 快速推理
from transformers import pipeline
# 文本生成
generator = pipeline("text-generation", model="gpt2")
print(generator("AI will change the world by"))
- 模型微调
- 部署生产:支持导出为 ONNX、TorchScript 格式,或通过 FastAPI 部署 API。
通过 Transformers 库,开发者可以轻松实现从研究到生产的全流程 AI 应用,大幅降低复杂模型的开发门槛,限于篇幅,我们这里只介绍和大模型开发相关的内容。
2 pipeline函数
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。
常用参数:
- task (必填): 指定任务类型,例如 “text-classification”, “question-answering”。
- model (可选): 指定预训练模型名称或本地路径(默认使用该任务的推荐模型)。
- device (可选): device=0 使用 GPU(ID指定显卡),device=-1 使用 CPU。
- tokenizer (可选): 自定义分词器。
- batch_size (可选): 批量处理输入时的批次大小。
目前常用的 pipelines 任务有:
- feature-extraction (获得文本的向量化表示)
- fill-mask (填充被遮盖的词、片段)
- ner(命名实体识别)
- question-answering (自动问答)
- sentiment-analysis (情感分析)
- summarization (自动摘要)
- text-generation (文本生成)
- translation (机器翻译)
- zero-shot-classification (零训练样本分类)
pipeline 模型会自动完成以下三个步骤:
- 1 将文本预处理为模型可以理解的格式;
- 2 将预处理好的文本送入模型;
- 3 对模型的预测值进行后处理,输出人类可以理解的格式。
pipeline 会自动选择合适的预训练模型来完成任务,例如对于情感分析,默认就会选择微调好的英文情感模型 distilbert-base-uncased-finetuned-sst-2-english。
pipeline的使用很简单,在调用pipeline函数时只需要指定任务,随后它会返回一个函数对象,然后我们只需要把参数输入到这个函数中即可。
以情感分析为例,在调用pipeline函数时,指定任务为sentiment-analysis,随后返回一个函数对象,接着我们把要分析的句子当成参数输入到这个函数对象中,就可以得到其情感标签(积极/消极)以及对应的概率:
from transformers import pipelineclassifier = pipeline("sentiment-analysis")
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)
results = classifier(["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
print(results)
上述代码会自动缓存下载的模型权重,默认保存到 ~/.cache/huggingface/transformers(Windows为C:\Users\xxx.cache\huggingface\hub),但由于国内访问https://huggingface.co受限,因此会报错,此时可以去魔搭社区把模型权重下载到本地,然后通过指定路径调用,即pipeline("sentiment-analysis", model=model_path)。
输出:
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)[{'label': 'POSITIVE', 'score': 0.9598048329353333}]
[{'label': 'POSITIVE', 'score': 0.9598048329353333}, {'label': 'NEGATIVE', 'score': 0.9994558691978455}]
再比如文本生成,在调用pipeline函数时,指定任务为text-generation,随后将提示词送入到模型(即pipeline返回的函数对象,在text-generation任务中,pipeline 自动选择预训练好的 gpt2 模型来完成任务)中来生成后续文本。
注意,由于文本生成具有随机性,因此每次运行都会得到不同的结果。代码如下:
from transformers import pipelinegenerator = pipeline("text-generation")
results = generator("In this course, we will teach you how to")
print(results)
results = generator("In this course, we will teach you how to",num_return_sequences=2, # 生成两次max_length=50 # 最大长度
)
print(results)
输出:
No model was supplied, defaulted to gpt2 (https://huggingface.co/gpt2)[{'generated_text': "In this course, we will teach you how to use data and models that can be applied in any real-world, everyday situation. In most cases, the following will work better than other courses I've offered for an undergrad or student. In order"}]
[{'generated_text': 'In this course, we will teach you how to make your own unique game called "Mono" from scratch by doing a game engine, a framework and the entire process starting with your initial project. We are planning to make some basic gameplay scenarios and'}, {'generated_text': 'In this course, we will teach you how to build a modular computer, how to run it on a modern Windows machine, how to install packages, and how to debug and debug systems. We will cover virtualization and virtualization without a programmer,'}]
3 pipeline流程分解
以情感分析为例,输入“This course is amazing!”,pipeline背后做的是下面的工作:
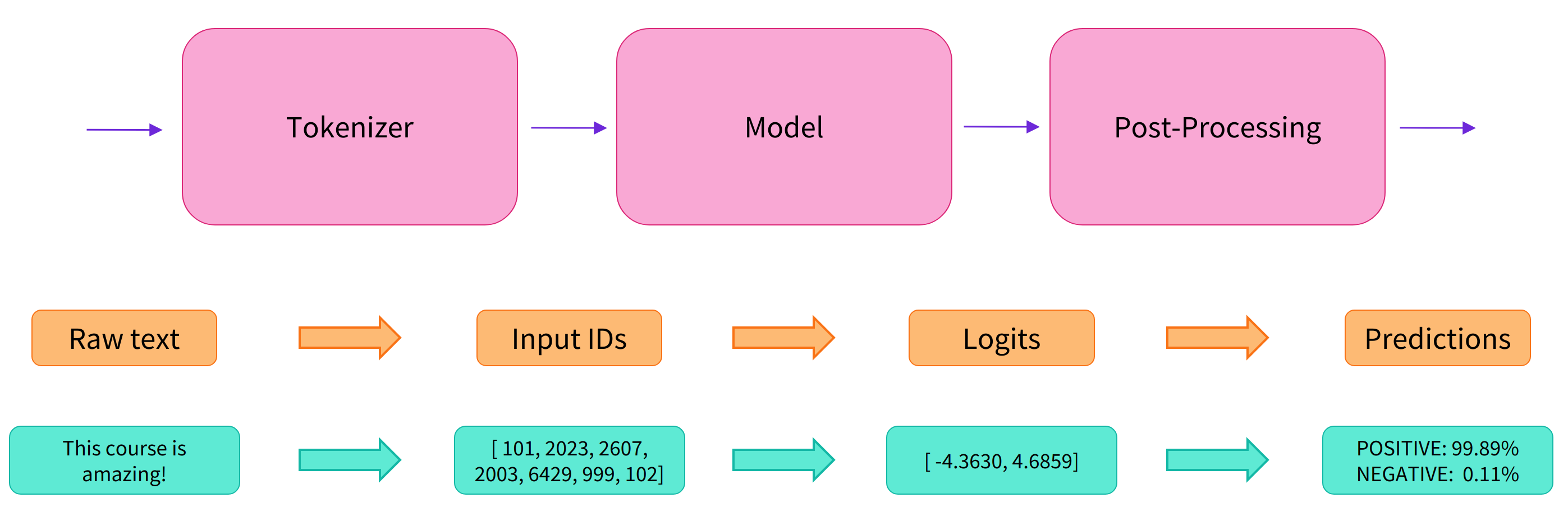
3.1 分词
因为神经网络模型无法直接处理文本,因此首先需要通过预处理环节将文本转换为模型可以理解的数字。具体地,我们会使用每个模型对应的分词器 (tokenizer) 来进行:
- 1 将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens;
- 2 根据模型的词表将每个 token 映射到对应的 token 编号(就是一个数字);
- 3 根据模型的需要,添加一些额外的输入(例如调用Bert模型时,需要加起始符、分隔符等)。
对输入文本的预处理需要与模型自身预训练时的操作完全一致,只有这样模型才可以正常地工作。注意,每个模型都有特定的预处理操作,如果对要使用的模型不熟悉,可以通过 Model Hub 查询。这里我们使用 AutoTokenizer 类和它的 from_pretrained() 函数,它可以自动根据模型 checkpoint 名称来获取对应的分词器。
from transformers import AutoTokenizercheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint) # 国内访问 HuggingFace 受限,可以从魔搭下载模型权重,然后把checkpoit换成权重路径raw_inputs = ["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
输出:
{'input_ids': tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0,0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])
}
可以看到,输出中包含两个键 input_ids 和 attention_mask,其中 input_ids 对应分词之后的 tokens 映射到的数字编号列表,而 attention_mask 则是用来标记哪些 tokens 是被填充的(这里“1”表示是原文,“0”表示是填充字符)。padding、truncation 这些参数,以及 attention_mask 项,后面我们会详细介绍。
3.2 将预处理好的输入送入模型
预训练模型的下载方式和分词器 (tokenizer) 类似,Transformers 包提供了一个 AutoModel 类和对应的 from_pretrained() 函数。下面我们手工下载这个 distilbert-base 模型:
from transformers import AutoModelcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
预训练模型的本体只包含基础的 Transformer 模块,对于给定的输入,它会输出一些神经元的值,称为 hidden states 或者特征 (features)。对于 NLP 模型来说,可以理解为是文本的高维语义表示。这些 hidden states 通常会被输入到其他的模型部分(称为 head),以完成特定的任务,例如送入到分类头中完成文本分类任务。过程如下:
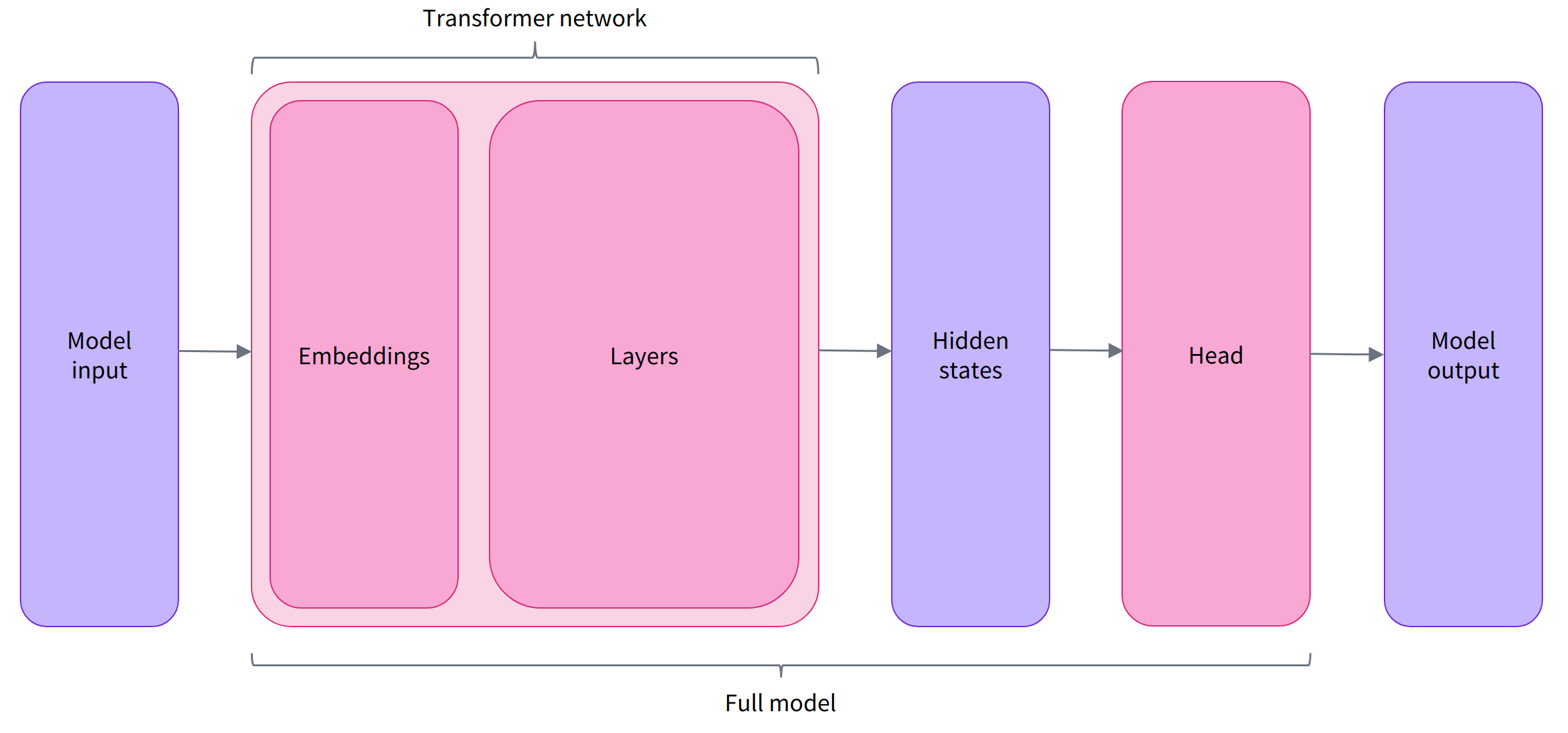
Transformer 模块的输出是一个维度为 (Batch size, Sequence length, Hidden size) 的三维张量,其中 Batch size 表示每次输入的样本(文本序列)数量,即每次输入多少个句子,上例中为 2;Sequence length 表示文本序列的长度,即每个句子被分为多少个 token,上例中为 16;Hidden size 表示每一个 token 经过模型编码后的输出向量(语义表示)的维度。预训练模型编码后的输出向量的维度通常都很大,例如 Bert 模型 base 版本的输出为 768 维,一些大模型的输出维度为 3072 甚至更高。
我们可以打印出这里使用的 distilbert-base 模型的输出维度:
from transformers import AutoTokenizer, AutoModelcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)raw_inputs = ["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
输出:
torch.Size([2, 16, 768])
Transformers 模型的输出格式类似 namedtuple 或字典,可以像上面那样通过属性访问,也可以通过键(outputs["last_hidden_state"]),甚至索引访问(outputs[0])。
对于情感分析任务,很明显我们最后需要使用的是一个文本分类 head。因此,我们这里不使用 AutoModel 类,而是使用 AutoModelForSequenceClassification,它自带后处理功能:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)raw_inputs = ["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits.shape)
print(outputs.logits)
输出
torch.Size([2, 2])
tensor([[-1.5607, 1.6123],[ 4.1692, -3.3464]], grad_fn=<AddmmBackward0>)
3.3 对模型输出进行后处理
由于模型的输出只是一些数值(logits 值),因此并不适合人类阅读,我们需要将这些数值转化成概率值。例如我们打印出上面例子的输出:
import torch
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)raw_inputs = ["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
打印:
tensor([[4.0195e-02, 9.5980e-01],[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward0>)
这样模型的预测结果就是容易理解的概率值:第一个句子 [ 0.0402 , 0.9598 ] [0.0402, 0.9598] [0.0402,0.9598],第二个句子 [ 0.9995 , 0.0005 ] [0.9995, 0.0005] [0.9995,0.0005]。最后,为了得到对应的标签,可以读取模型 config 中提供的 id2label 属性:
print(model.config.id2label)
输出:
{0: 'NEGATIVE', 1: 'POSITIVE'}
于是我们可以得到最终的预测结果:
- 第一个句子: NEGATIVE: 0.0402, POSITIVE: 0.9598
- 第二个句子: NEGATIVE: 0.9995, POSITIVE: 0.0005
4 模型
4.1 Transformers 封装的常见模型类型
Transformers 库封装了很多不同的模型类型,常见的有:
- *Model (返回 hidden states),这里表示以 Model 结尾的类名,如 BertModel、AutoModel等
- *ForCausalLM (用于条件语言模型)
- *ForMaskedLM (用于遮盖语言模型)
- *ForMultipleChoice (用于多选任务)
- *ForQuestionAnswering (用于自动问答任务)
- *ForSequenceClassification (用于文本分类任务)
- *ForTokenClassification (用于 token 分类任务,例如命名实体识别)
4.2 加载模型
除了像之前使用 AutoModel 根据 checkpoint 自动加载模型以外,我们也可以直接使用模型对应的 Model 类,例如 BERT 对应的就是 BertModel:
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
在大部分情况下,我们都应该使用 AutoModel,它能根据 checkpoints 来确定该加载什么模型,checkpoints是模型名称,也可以将 checkpoints 替换成本地模型路径。这样如果我们想要使用另一个模型(比如把 BERT 换成 RoBERTa),只需修改 checkpoint,其他代码可以保持不变。
使用 AutoModel 是相对于 BertModel 而言的,也就是说相对于具体特征提取器而言的。如果你知道了模型用来做什么任务,比如我知道模型用来做分类任务,那就使用 AutoModelForSequenceClassification,具体是哪个分类模型,不用管,完形填空任务就用AutoModelForMaskedLM,具体用哪个完形填空任务,也不用管,生成任务就用AutoModelForCausalLM,具体用哪个生成模型也不用管。
所有存储在 HuggingFace Model Hub 上的模型都可以通过 Model.from_pretrained() 来加载权重,参数可以像上面一样是 checkpoint 的名称(此时会自动下载模型权重至本地),也可以是本地路径(预先下载的模型目录),例如:
from transformers import BertModel
model = BertModel.from_pretrained("./models/bert/")
由于名称加载方式需要连接网络,因此在大部分情况下我们都会采用本地路径的方式加载模型。
部分模型的 Hub 页面中会包含很多文件,我们通常只需要下载模型对应的 config.json 和 pytorch_model.bin,以及分词器对应的 tokenizer.json、tokenizer_config.json 和 vocab.txt。
4.3 保存模型
保存模型通过调用 Model.save_pretrained() 函数实现,例如保存加载的 BERT 模型:
from transformers import AutoModelmodel = AutoModel.from_pretrained("bert-base-cased")
model.save_pretrained("./models/bert-base-cased/")
这会在保存路径下创建两个文件:
- config.json:模型配置文件,存储模型结构参数,例如 Transformer 层数、特征空间维度等;
- pytorch_model.bin:又称为 state dictionary,存储模型的权重。
简单来说,配置文件记录模型的结构,模型权重记录模型的参数,这两个文件缺一不可。我们自己保存的模型同样通过 Model.from_pretrained() 加载,只需要传递保存目录的路径。
5 分词器
由于神经网络模型不能直接处理文本,因此我们需要先将文本转换为数字,这个过程被称为编码 (Encoding),其包含两个步骤:
- (1) 使用分词器 (tokenizer) 将文本按词、子词、字符切分为 tokens;
- (2)将所有的 token 映射到对应的 token ID。
词表就是一个映射字典,负责将 token 映射到对应的 ID(从 0 开始),神经网络模型就是通过这些 token ID 来区分每一个 token。
5.1 分词策略
根据切分粒度的不同,分词策略可以分为以下几种:
5.1.1 按词切分(Word-based)
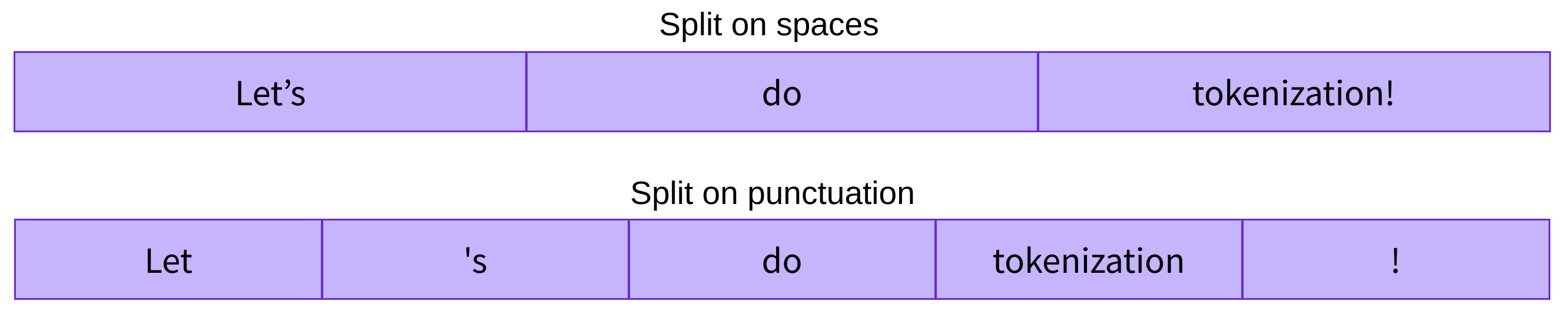
例如直接利用 Python 的 split() 函数按空格进行分词:
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
输出
['Jim', 'Henson', 'was', 'a', 'puppeteer']
这种策略的问题是会将文本中所有出现过的独立片段都作为不同的 token,从而产生巨大的词表。而实际上很多词是相关的,例如 “dog” 和 “dogs”、“run” 和 “running”,如果给它们赋予不同的编号就无法表示出这种关联性。
当遇到不在词表中的词时,分词器会使用一个专门的 [UNK] token 来表示它是 unknown 的。显然,如果分词结果中包含很多 [UNK] 就意味着丢失了很多文本信息,因此一个好的分词策略,应该尽可能不出现 unknown token。
5.1.2 按字符切分 (Character-based)

这种策略把文本切分为字符而不是词语,这样就只会产生一个非常小的词表,并且很少会出现词表外的 tokens。
但是从直觉上来看,字符本身并没有太大的意义,因此将文本切分为字符之后就会变得不容易理解。这也与语言有关,例如中文字符会比拉丁字符包含更多的信息,相对影响较小。此外,这种方式切分出的 tokens 会很多,例如一个由 10 个字符组成的单词就会输出 10 个 tokens,而实际上它们只是一个词。
目前主流大模型处理中文就是用这种切分方式,因为中文每个字符都有含义,但这种切分方式不太合适处理英文。因此对于英文,现在广泛采用的是一种同时结合了按词切分和按字符切分的方式——按子词切分 (Subword tokenization)。
5.1.3 按子词切分 (Subword)
高频词直接保留,低频词被切分为更有意义的子词。例如 “annoyingly” 是一个低频词,可以切分为 “annoying” 和 “ly”,这两个子词不仅出现频率更高,而且词义也得以保留。下图展示了对 “Let’s do tokenization!“ 按子词切分的结果:

可以看到,“tokenization” 被切分为了 “token” 和 “ization”,不仅保留了语义,而且只用两个 token 就表示了一个长词。这种策略只用一个较小的词表就可以覆盖绝大部分文本,基本不会产生 unknown token。尤其对于土耳其语等黏着语,几乎所有的复杂长词都可以通过串联多个子词构成。
5.2 加载与保存分词器
分词器的加载与保存与模型相似,使用 Tokenizer.from_pretrained() 和 Tokenizer.save_pretrained() 函数。例如加载并保存 BERT 模型的分词器:
from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
同样地,在大部分情况下我们都应该使用 AutoTokenizer 来加载分词器:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
调用 Tokenizer.save_pretrained() 函数会在保存路径下创建三个文件:
special_tokens_map.json:映射文件,里面包含 unknown token 等特殊字符的映射关系;tokenizer_config.json:分词器配置文件,存储构建分词器需要的参数;vocab.txt:词表,一行一个 token,行号就是对应的 token ID(从 0 开始)。
5.3 文本的编码与解码
5.3.1 文本编码
前面说过,文本编码 (Encoding) 过程包含两个步骤:
- 分词:使用分词器按某种策略将文本切分为 tokens;
- 映射:将 tokens 转化为对应的 token IDs。
下面我们首先使用 BERT 分词器来对文本进行分词:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)print(tokens)
输出
['using', 'a', 'transform', '##er', 'network', 'is', 'simple']
可以看到,BERT 分词器采用的是子词切分策略,它会不断切分词语直到获得词表中的 token,例如 “transformer” 会被切分为 “transform” 和 “##er”。
然后,我们通过 convert_tokens_to_ids() 将切分出的 tokens 转换为对应的 token IDs:
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
输出
[7993, 170, 13809, 23763, 2443, 1110, 3014]
还可以通过 encode() 函数将这两个步骤合并,并且 encode() 会自动添加模型需要的特殊 token,例如 BERT 分词器会分别在序列的首尾添加 [CLS] 和 [SEP]:
rom transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")sequence = "Using a Transformer network is simple"
sequence_ids = tokenizer.encode(sequence)print(sequence_ids)
输出
[101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102]
其中 101 和 102 分别是 [CLS] 和 [SEP] 对应的 token IDs。
注意,上面这些只是为了演示。在实际编码文本时,最常见的是直接使用分词器进行处理,这样不仅会返回分词后的 token IDs,还包含模型需要的其他输入。例如 BERT 分词器还会自动在输入中添加 token_type_ids 和 attention_mask:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_text = tokenizer("Using a Transformer network is simple")
print(tokenized_text)
输出
{'input_ids': [101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
也就是说,使用分词器可以有三种途径:
- (1)
tokenizer.tokenize+convert_tokens_to_ids得到的结果不会自动添加模型需要的特殊 token,如[CLS]和[SEP]; - (2)
tokenizer.encode得到的结果会自动添加模型需要的特殊 token; - (3)
tokenizer(text)得到的结果会有特殊的 token,还有模型需要的其他输入。
5.3.2 文本解码
文本解码 (Decoding) 与编码相反,负责将 token IDs 转换回原来的字符串。注意,解码过程不是简单地将 token IDs 映射回 tokens,还需要合并那些被分为多个 token 的单词。下面我们通过 decode() 函数对前面生成的 token IDs 进行解码:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)decoded_string = tokenizer.decode([101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102])
print(decoded_string)
输出
Using a transformer network is simple
[CLS] Using a Transformer network is simple [SEP]
解码文本是一个重要的步骤,在进行文本生成、翻译或者摘要等 Seq2Seq (Sequence-to-Sequence) 任务时都会调用这一函数。
6 处理多段文本
6.1 Batch 维度
现实场景中,我们往往会同时处理多段文本,而且模型也只接受批 (batch) 数据作为输入。
即使只有一段文本,也需要将它组成一个只包含一个样本的 batch,例如:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence = "I've been waiting for a HuggingFace course my whole life."tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
# input_ids = torch.tensor(ids), This line will fail.
input_ids = torch.tensor([ids]) # 需要将 ids 转为二维,第一个维度是 batch
print("Input IDs:\n", input_ids)output = model(input_ids)
print("Logits:\n", output.logits)
输出
Input IDs:
tensor([[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607,2026, 2878, 2166, 1012]])
Logits:
tensor([[-2.7276, 2.8789]], grad_fn=<AddmmBackward0>)
上面的代码仅作为演示,我们通过 [ids] 构建了一个只包含一段文本的 batch。
实际场景中,我们应该直接使用分词器对文本进行处理,例如对于上面的例子:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence = "I've been waiting for a HuggingFace course my whole life."tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print("Inputs Keys:\n", tokenized_inputs.keys())
print("\nInput IDs:\n", tokenized_inputs["input_ids"])output = model(**tokenized_inputs)
print("\nLogits:\n", output.logits)
输出:
Inputs Keys:dict_keys(['input_ids', 'attention_mask'])Input IDs:
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,2607, 2026, 2878, 2166, 1012, 102]])Logits:
tensor([[-1.5607, 1.6123]], grad_fn=<AddmmBackward0>)
由于分词器自动在序列的首尾添加了 [CLS] 和 [SEP] ,所以上面两个例子中模型的输出是有差异的。因为 DistilBERT 预训练时是包含 [CLS] 和 [SEP] 的,所以第二个例子才是正确的使用方法。
可以看到,分词器输出的结果中不仅包含 token IDs(input_ids),并且添加了batch维度,还会包含模型需要的其他输入项。前面我们之所以只输入 token IDs 模型也能正常运行,是因为它自动地补全了其他的输入项,例如 attention_mask 等,后面我们会具体介绍。
6.2 Padding 操作
按批输入多段文本产生的一个直接问题就是:batch 中的文本有长有短,而输入张量必须是严格的二维矩形,维度为 (batch size, sequence length),即每一段文本编码后的 token IDs 数量必须一样多。例如下面的 ID 列表是无法转换为张量的:
batched_ids = [[200, 200, 200],[200, 200]
]
我们需要通过 Padding 操作,在短序列的结尾填充特殊的 padding token,使得 batch 中所有的序列都具有相同的长度,例如:
padding_id = 100batched_ids = [[200, 200, 200],[200, 200, padding_id],
]
模型的 padding token ID 可以通过其分词器的 pad_token_id 属性获得。下面我们尝试将两段文本分别以独立以及 batch 的形式送入到模型中:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [[200, 200, 200],[200, 200, tokenizer.pad_token_id],
]print(tokenizer.pad_token_id)
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
输出
pad id: 0
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward0>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward0>)
We strongly recommend passing in an `attention_mask` since your input_ids may be padded. See https://huggingface.co/docs/transformers/troubleshooting#incorrect-output-when-padding-tokens-arent-masked.
tensor([[ 1.5694, -1.3895],[ 1.3374, -1.2163]], grad_fn=<AddmmBackward0>)
可以看到,填充的pad id 为0,当然,不同模型对应的词表不一样,因此 pad id 也不一样。
这里出现了一个警告,建议我们传入attention_mask。我们看到,使用 padding token 填充的序列的结果竟然与其单独送入模型时不同!这是因为模型默认会编码输入序列中的所有 token 以建模完整的上下文,因此这里会将填充的 padding token 也一同编码进去,从而生成不同的语义表示。因此,在进行 Padding 操作时,我们必须明确告知模型哪些 token 是我们填充的,它们不应该参与编码。这就需要使用到 Attention Mask 了,在前面的例子中相信你已经多次见过它了。
6.3 Attention Mask
Attention Mask 是一个尺寸与 input IDs 完全相同,且仅由 0 和 1 组成的张量,0 表示对应位置的 token 是填充符,不参与计算。当然,一些特殊的模型结构也会借助 Attention Mask 来遮蔽掉指定的 tokens。
对于上面的例子,如果我们通过 attention_mask 标出填充的 padding token 的位置,计算结果就不会有问题了:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [[200, 200, 200],[200, 200, tokenizer.pad_token_id],
]
batched_attention_masks = [[1, 1, 1],[1, 1, 0],
]print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
outputs = model(torch.tensor(batched_ids),attention_mask=torch.tensor(batched_attention_masks))
print(outputs.logits)
输出:
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward0>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward0>)
tensor([[ 1.5694, -1.3895],[ 0.5803, -0.4125]], grad_fn=<AddmmBackward0>)
正如前面强调的那样,在实际使用时,我们应该直接使用分词器对文本进行处理,它不仅会向 token 序列中添加模型需要的特殊字符(例如
),还会自动生成对应的 Attention Mask。
目前大部分 Transformer 模型只能接受长度不超过 512 或 1024 的 token 序列,因此对于长序列,有以下三种处理方法:
- 1 使用一个支持长文的 Transformer 模型,例如 Longformer 和 LED(最大长度 4096);
- 2 设定最大长度 max_sequence_length 以截断输入序列:sequence = sequence[:max_sequence_length]。
- 3 将长文切片为短文本块 (chunk),然后分别对每一个 chunk 编码。在后面的快速分词器中,我们会详细介绍。
6.4 直接使用分词器
正如前面所说,在实际使用时,我们可以直接使用分词器来完成包括分词、转换 token IDs、Padding、构建 Attention Mask、截断等操作。例如:
from transformers import AutoTokenizercheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"
]model_inputs = tokenizer(sequences)
print(model_inputs)
输出
{'input_ids': [[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102], [101, 2061, 2031, 1045, 999, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]
}
可以看到,分词器的输出包含了模型需要的所有输入项。对于 DistilBERT 模型,就是 input IDs(input_ids)和 Attention Mask(attention_mask)。
Padding 操作通过 padding 参数来控制:
padding="longest": 将序列填充到当前 batch 中最长序列的长度,即与最长的序列对齐;padding="max_length":将所有序列填充到模型能够接受的最大长度,例如 BERT 模型就是 512。
from transformers import AutoTokenizercheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"
]model_inputs = tokenizer(sequences, padding="longest")
print(model_inputs)model_inputs = tokenizer(sequences, padding="max_length")
print(model_inputs)
输出:
{'input_ids': [[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102], [101, 2061, 2031, 1045, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
}{'input_ids': [[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102, 0, 0, 0, 0, 0, 0, 0, 0, ...], [101, 2061, 2031, 1045, 999, 102, 0, 0, 0, ...]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, ...], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]]
}
截断操作通过 truncation 参数来控制,如果 truncation=True,那么大于模型最大接受长度的序列都会被截断,这里说的最大长度,指的是包 含[CLS] 和 [SEP]的最大长度。例如,对于 BERT 模型就会截断长度超过 512 的序列。此外,也可以通过 max_length 参数来控制截断长度:
from transformers import AutoTokenizercheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"
]model_inputs = tokenizer(sequences, max_length=8, truncation=True)
print(model_inputs)
输出:
{'input_ids': [[101, 1045, 1005, 2310, 2042, 3403, 2005, 102], [101, 2061, 2031, 1045, 999, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]
}
6.5 指定返回值格式
前面我们得到的分词器的输出的 token ids,都是列表格式。
分词器还可以通过 return_tensors 参数指定返回的张量格式:设为 pt 则返回 PyTorch 张量;tf 则返回 TensorFlow 张量,np 则返回 NumPy 数组。例如:
from transformers import AutoTokenizercheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"
]model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
print(model_inputs)model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
print(model_inputs)
输出:
{'input_ids': tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,2607, 2026, 2878, 2166, 1012, 102],[ 101, 2061, 2031, 1045, 999, 102, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
}{'input_ids': array([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662,12172, 2607, 2026, 2878, 2166, 1012, 102],[ 101, 2061, 2031, 1045, 999, 102, 0, 0, 0,0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
}
实际使用分词器时,我们通常会同时进行 padding 操作和截断操作,并设置返回格式为 Pytorch 张量,这样就可以直接将分词结果送入模型:
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"
]tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
print(tokens)
output = model(**tokens)
print(output.logits)
输出
{'input_ids': tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,2607, 2026, 2878, 2166, 1012, 102],[ 101, 2061, 2031, 1045, 999, 102, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}tensor([[-1.5607, 1.6123],[-3.6183, 3.9137]], grad_fn=<AddmmBackward0>)
在 padding=True, truncation=True 设置下,同一个 batch 中的序列都会 padding 到相同的长度,并且大于模型最大接受长度的序列会被自动截断。
6.6 编码句子对
除了对单段文本进行编码以外(batch 只是并行地编码多个单段文本),对于 BERT 等包含“句子对”预训练任务的模型,它们的分词器都支持对“句子对”进行编码,例如:
from transformers import AutoTokenizercheckpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)inputs = tokenizer("This is the first sentence.", "This is the second one.")
print(inputs)tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"])
print(tokens)
输出:
{'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
此时分词器会使用 [SEP] 拼接两个句子,输出形式为 “[CLS] sentence1 [SEP] sentence2 [SEP]” 的 token 序列,这也是 BERT 模型预期的“句子对”输入格式。
返回结果中除了前面我们介绍过的 input_ids 和 attention_mask 之外,还包含了一个 token_type_ids 项,用于标记哪些 token 属于第一个句子,哪些属于第二个句子。如果我们将上面例子中的 token_type_ids 项与 token 序列对齐:
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
可以看到第一个句子“[CLS] sentence1 [SEP]”所有 token 的 type ID 都为 0,而第二个句子“sentence2 [SEP]”对应的 token type ID 都为 1。
如果我们选择其他模型,分词器的输出不一定会包含 token_type_ids 项(例如 DistilBERT 模型)。分词器只需保证输出格式与模型预训练时的输入一致即可。实际使用时,我们不需要去关注编码结果中是否包含 token_type_ids 项,分词器会根据 checkpoint 自动调整输出格式。
例如:
from transformers import AutoTokenizercheckpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)sentence1_list = ["First sentence.", "This is the second sentence.", "Third one."]
sentence2_list = ["First sentence is short.", "The second sentence is very very very long.", "ok."]tokens = tokenizer(sentence1_list,sentence2_list,padding=True,truncation=True,return_tensors="pt"
)
print(tokens)
print(tokens['input_ids'].shape)
输出
{'input_ids': tensor([[ 101, 2034, 6251, 1012, 102, 2034, 6251, 2003, 2460, 1012, 102, 0,0, 0, 0, 0, 0, 0],[ 101, 2023, 2003, 1996, 2117, 6251, 1012, 102, 1996, 2117, 6251, 2003,2200, 2200, 2200, 2146, 1012, 102],[ 101, 2353, 2028, 1012, 102, 7929, 1012, 102, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
}
torch.Size([3, 18])
可以看到分词器成功地输出了形式为 “[CLS] sentence1 [SEP] sentence2 [SEP]” 的 token 序列,并且将三个序列都 padding 到了相同的长度。
7 总结
本文主要介绍了 pipeline 函数、模型和分词器,要做到拿到一个新模型之后,分词器可以使用AutoTokenizer,模型可以使用AutoModel,如果知道了任务类型,那么可以使用 AutoModelForXXX。