RocketMQ与Kafka的区别
文章目录
- 相同之处
- 不同之处
- 存储形式
- 性能对比
- 传输系统调用
- 存储可靠性
- 单机支持的队列数
- 延时消息
- 消息重复
- 消息过滤
- 消息失败重试
- 死信队列 DLQ
- 回溯消息
- 分布式事务
- 服务发现
- 开发语言友好性
- 开源社区活跃度
- 商业支持
- 成熟度
- 总结
- Kafka 和 RocketMQ 怎么选?
本文参考:
RocketMQ 内部开发者的文章+读者观点:https://www.cnblogs.com/qiumingcheng/p/5387008.html
结合图片有比较清晰的对比点:https://mp.weixin.qq.com/s/oje7PLWHz_7bKWn8M72LUw
Kafka吞吐性能强的原因:https://mp.weixin.qq.com/s?__biz=MzkxNTU5MjE0MQ==&mid=2247495430&idx=1&sn=53aa4332e44993792e9f06b9b5725a73
相同之处
- 分区机制:消息通过 rocketmq queue/kafka partition 进行分区,提高了消费者并行处理能力
- 副本机制:通过对分区进行副本 replication,提升了容灾能力
- 页缓存:两者均利用了操作系统的页缓存 Page Cache 机制,加载数据时,以该数据所在的页提前缓存到操作系统内存中,从而实现相邻数据的快速访问
- 顺序 IO:两者都尽可能通过顺序 IO 降低读写的随机性,将读写集中在比较集中的区域,从而减少缺页终端,提高了性能
- 零拷贝:都使用零拷贝降低用户空间和内核空间的转换以及 CPU 的利用率,但是在具体使用上仍然有差异
- 单分区有序:都仅支持单Topic分区有序,全局有序也是基于使用单个分区
- 消息压缩:都支持对消息压缩,减少网络传输数据量
不同之处
存储形式
- RocketMQ 采用 CommitLog + ConsumeQueue,单个 broker 所有 topic 在 CommitLog 中顺序写,同时每个 topic 的每个 queue 都有一个对应的 ConsumeQueue 文件作为消息索引。
RocketMQ 中的 ConsumeQueue 只存储一些简要的信息,比如消息在 CommitLog 中的偏移量,RocketMQ 消费消息,broker 先从 ConsumeQueue 上读取到消息对应的 offset,再根据 offset 从 CommitLog 中取出完整的消息,需要「读两次」。 - Kafka 采用 partition,每个 topic 的每个 partition 对应一个文件,顺序写入,定时异步刷盘。但一旦单个 broker 的 partition 过多,则损续写退化为随机写, page cache 脏页过多,频繁触发缺页中断,性能大幅下降。
Kafka 中的 partition 会存储完整的消息体,kafka 消费消息,broker 只需要从 partition 「读取一次」拿到消息内容就好。
性能对比
- RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
- Kafka单机写入TPS约在百万条/秒,消息大小10个字节
总结:Kafka的TPS跑到单机百万,主要是由于Producer端将多个小消息合并,批量发向Broker。
RocketMQ为什么没有这么做?
1.Producer通常使用Java语言,缓存过多消息,GC是个很严重的问题
2.Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错
3.Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。
4.缓存的功能完全可以由上层业务完成。
传输系统调用
RocketMQ 与 Kafka 虽然都运用了零拷贝的传输形式,但是两者在具体实现上仍然有差别
- **RocketMQ 使用的是 mmap + write **
- kafka 使用的是 sendfile
sendfile 相比于 mmap 更快,没有 CPU 拷贝,内核空间和用户空间的切换也从4减少到了2
mmap 返回的是数据的具体内容,应用层能获取到消息内容并进行一些逻辑处理。
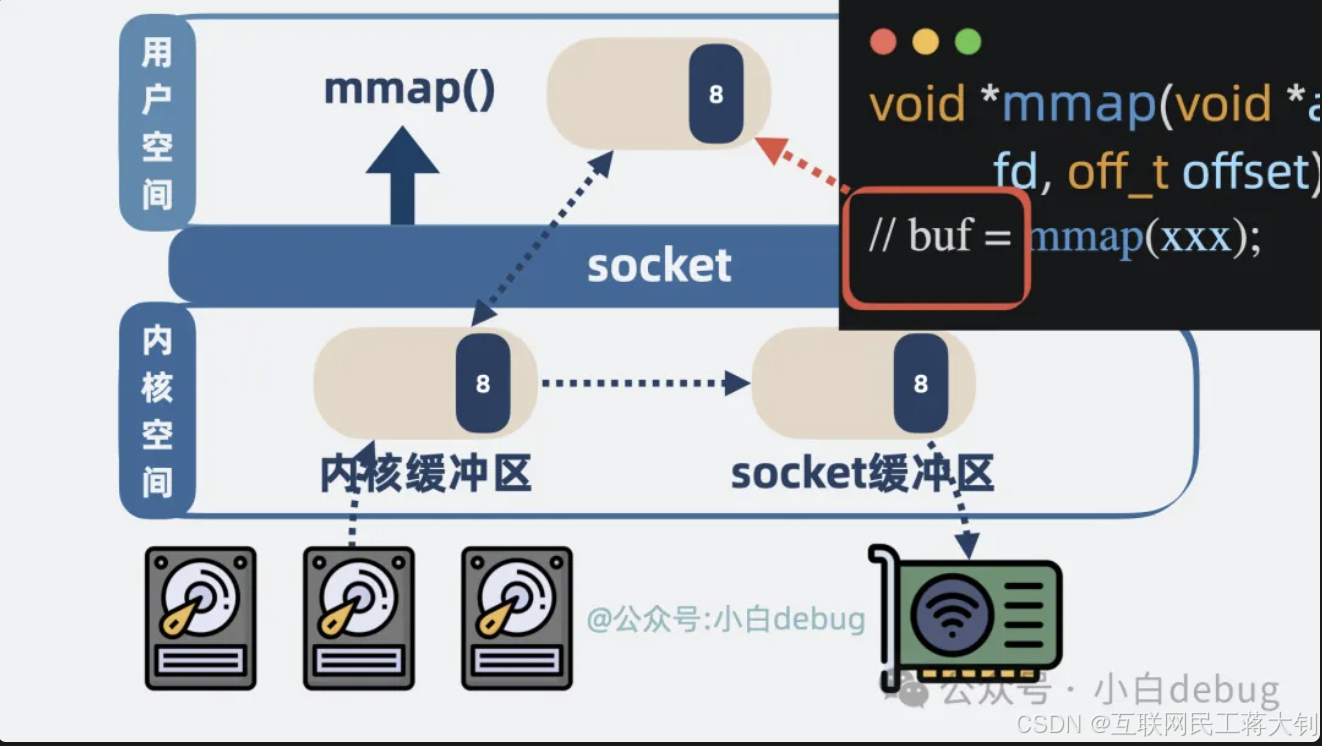
而 sendfile 返回的则是发送成功了几个字节数,具体发了什么内容,应用层根本不知道。
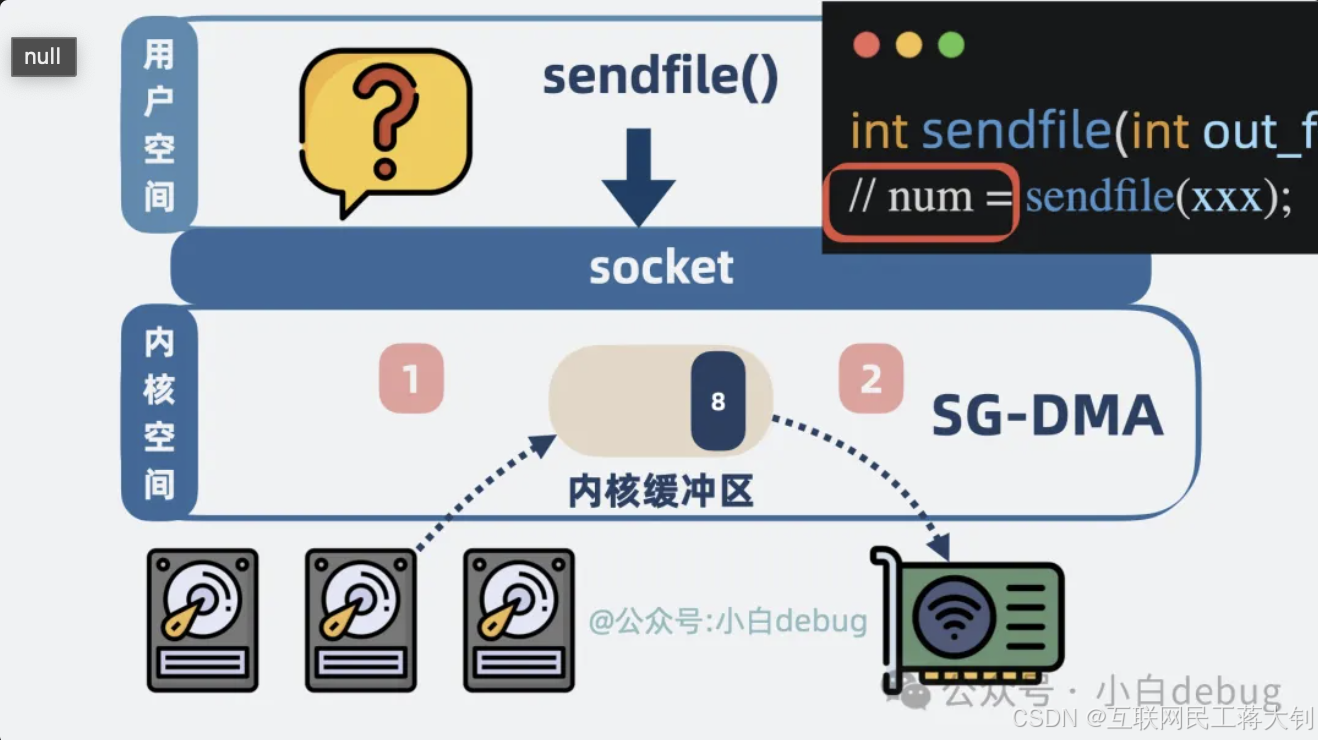
而 RocketMQ 的一些功能,却需要了解具体这个消息内容,方便二次投递等,比如将消费失败的消息重新投递到死信队列中,如果 RocketMQ 使用 sendfile,那根本没机会获取到消息内容长什么样子,也就没办法实现一些好用的功能了。而 kafka 却没有这些功能特性,追求极致性能,正好可以使用 sendfile。
存储可靠性
-
RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication
-
Kafka使用异步刷盘方式,异步Replication,同步 Replication (request.required.acks=-1,代表所有 replicas 接收才返回 ack)
单机支持的队列数
- RocketMQ单机支持最高5万个队列,Load不会发生明显变化,对多队列的支持好于 Kafka
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
延时消息
- RocketMQ 支持固定延时等级的延时消息,等级可配置
- Kafka 不支持延时消息,需要业务自己实现
消息重复
- RocketMQ 仅支持 At Least Once
- Kafka 支持 At Least Once、Exactly Once
消息过滤
- RocketMQ 支持消息过滤是在 Broker 端,支持 tag 过滤以及自定义 SQL 过滤
- Kafka 不支持 Broker 端的消息顾虑,需要在消费端自定义实现
消息失败重试
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
- Kafka消费失败不支持重试
死信队列 DLQ
- RocketMQ 通过 DLQ 来记录所有消费失败的消息
- Kafka 无 DLQ。Spring 等第三方工具有实现,方式为将失败的消息写入一个专门的 topic
回溯消息
- RocketMQ支持按照时间来回溯消息,精度毫秒,实现原理与 Kafka 相同,例如从一天之前的某时某分某秒开始重新消费消息
- Kafka需要先根据时间戳找到 offset,然后从Offset开始消费
分布式事务
- RocketMQ 支持事务消息,采用二阶段提交+broker定时回查。但也只能保证生产者与broker的一致性,broker与消费者之间只能单向重试,即保证最终一致性。
- Kafka从0.11版本开始支持事务消息,除支持最终一致性外,还实现了消息Exactly Once 语义(单个 partition)。
服务发现
- RocketMQ 自己实现了 Nameserver,通过一种更轻便的方式,管理 broker 集群信息
- Kafka 之前使用 Zookeeper 作为配置管理中间件,但是太重了,所以从 2.8.0 版本就支持将 Zookeeper 移除,通过在 broker 之间加入一致性算法 raft 实现同样的效果,这就是所谓的 KRaft 或 Quorum 模式。
开发语言友好性
- RocketMQ采用Java语言编写
- Kafka采用Scala编写
开源社区活跃度
-
RocketMQ的github社区有250个个人、公司用户登记了联系方式,QQ群超过1000人。
-
Kafka社区更新较慢,但国际化推广较好,由于是 linkin 开源的
商业支持
- RocketMQ在阿里云上已经开放公测近半年,目前以云服务形式免费供大家商用,并向用户承诺99.99%的可靠性,同时彻底解决了用户自己搭建MQ产品的运维复杂性问题
- Kafka原开发团队成立新公司,目前暂没有相关产品看到
成熟度
- RocketMQ在阿里集团内部有大量的应用在使用,每天都产生海量的消息,并且顺利支持了多次天猫双十一海量消息考验,是数据削峰填谷的利器。
- Kafka在日志领域比较成熟
总结
- RocketMQ 相比于 Kafka 在架构上做了减法,在功能上做了加法
- 跟 kafka 的架构相比,RocketMQ 简化了集群信息协调方式和分区以及备份模型。同时增强了消息过滤、消息回溯和事务能力,加入了延迟队列,死信队列等新特性。
- Kafka 的单机写入性能仍然强于 RocketMQ,拥有更高的吞吐量。我认为主要原因:1. Kafka Producer 端小消息体合并批量发送 2. Kafka Scala 语言天然支持 map-reduce 并发编程 3. Kafka 零拷贝的性能更强,当然这是牺牲了部分功能性换来的
Kafka 和 RocketMQ 怎么选?
经典的选型发问了,上面也总结了多处差异点,可以结合自己的业务场景进行选型:
- Kafka 吞吐快,适合数据流处理相关的场景,没有比较复杂的业务处理,比方说常用的日志处理,或者涉及到 Hive、Spark、Flink 等大数据等场景,字节内部的 Dorado 数据转换平台使用的就是 Kafka,能够实现 Hive 表转 Kafka 消息
- 复杂业务场景下尽量用 RocketMQ,RocketMQ 本身性能也不低,而且还有许多业务上能用到的功能特性。比方说之前我就由于没有做到消息队列的隔离,PPE 环境的 RocketMQ 消费者集群消费了线上的消息,又由于代码内部依赖的表结构还未更新(但是自动生成的 Mapper 文件已经更新了),导致这部分消息一直报错表结构异常,最终消费失败。补救方案是通过 DLQ 死信队列重新回放这些消费失败的消息,才保证了业务一致性的。