架构思维:构建高并发读服务_基于流量回放实现读服务的自动化测试回归方案
文章目录
- 引言
- 一、升级读服务架构,为什么需要自动化测试?
- 二、自动化回归测试系统:整体架构概览
- 三、日志收集
- 1. 拦截方式
- 2. 存储与优化策略
- 3. 架构进化
- 四、数据回放
- 技术实现
- 关键能力
- 五、差异对比
- 对比方式
- 灵活配置
- 六、三种回放模式详解
- 1. 离线回放
- 2. 实时回放(对比新旧服务)
- 3. 无录制实时回放
- 七、使用注意事项与最佳实践
- 八、模拟核心Code
- 九、小结

引言
在高并发读服务的架构优化过程中,我们往往关注系统如何抗压、如何缓存命中率更高,甚至在性能提升方案落实后迅速投入重构。然而,在这一过程中,容易被忽略的一环就是“测试回归”。
接下来我们将从实际落地角度,系统性地介绍一种支持读服务快速升级、业务稳定推进的「自动化测试回归系统架构」方案,构建一套覆盖全量场景、支持自助回归的自动化测试体系。
一、升级读服务架构,为什么需要自动化测试?
假设我们已落地了支持高并发的读服务架构,包括懒加载缓存、全量缓存、数据同步机制等。但读服务的升级改造带来的“回归压力”却是另一种挑战:
- 架构重构往往影响范围广,测试周期按“月”计。
- 日常需求中即便仅修改部分接口逻辑,也可能因底层复用代码影响其他未修改接口,造成线上 Bug。
新老版本的接口未变架构图
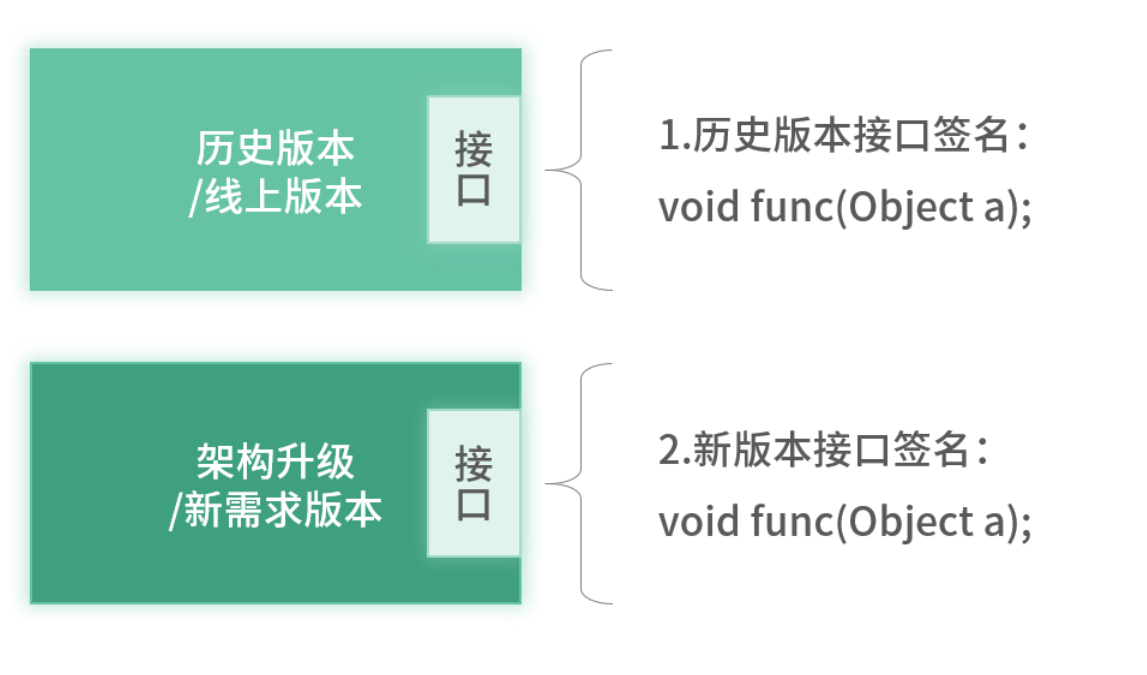
解决这类回归测试痛点,最优解是:自动化测试系统。这不仅提升了测试效率,也为系统升级提供了「安全缓冲带」。
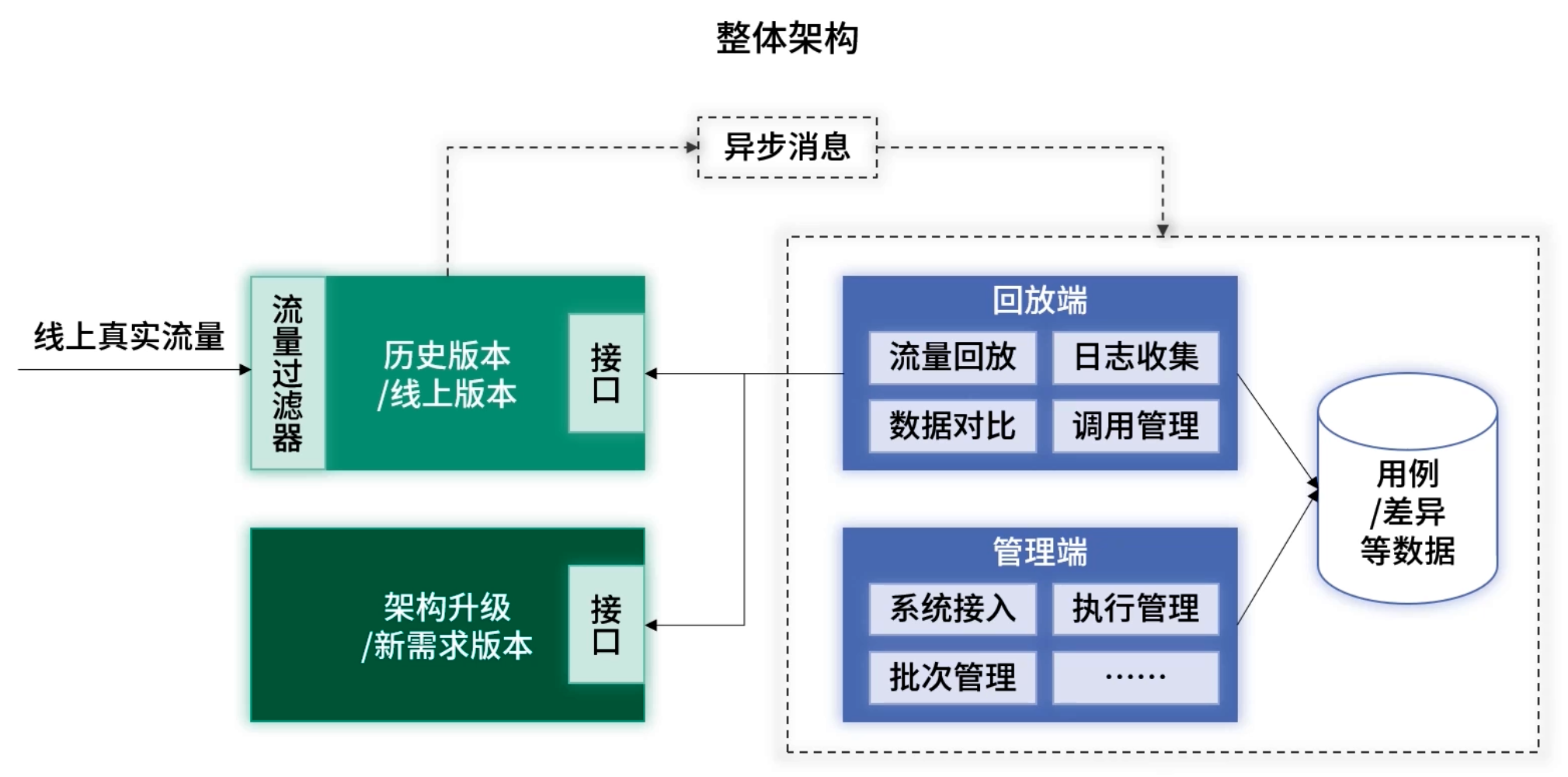
二、自动化回归测试系统:整体架构概览
自动化测试回归系统的核心由三个模块组成:
- 日志收集:拦截线上请求,记录请求参数和响应数据,生成“真实用户用例”。
- 数据回放:基于收集的请求数据,自动向新旧服务发起请求,触发真实的业务流程。
- 差异对比:将新老版本的响应结果进行对比,捕捉潜在 Bug。
三、日志收集
基于过滤器的日志收集架构图
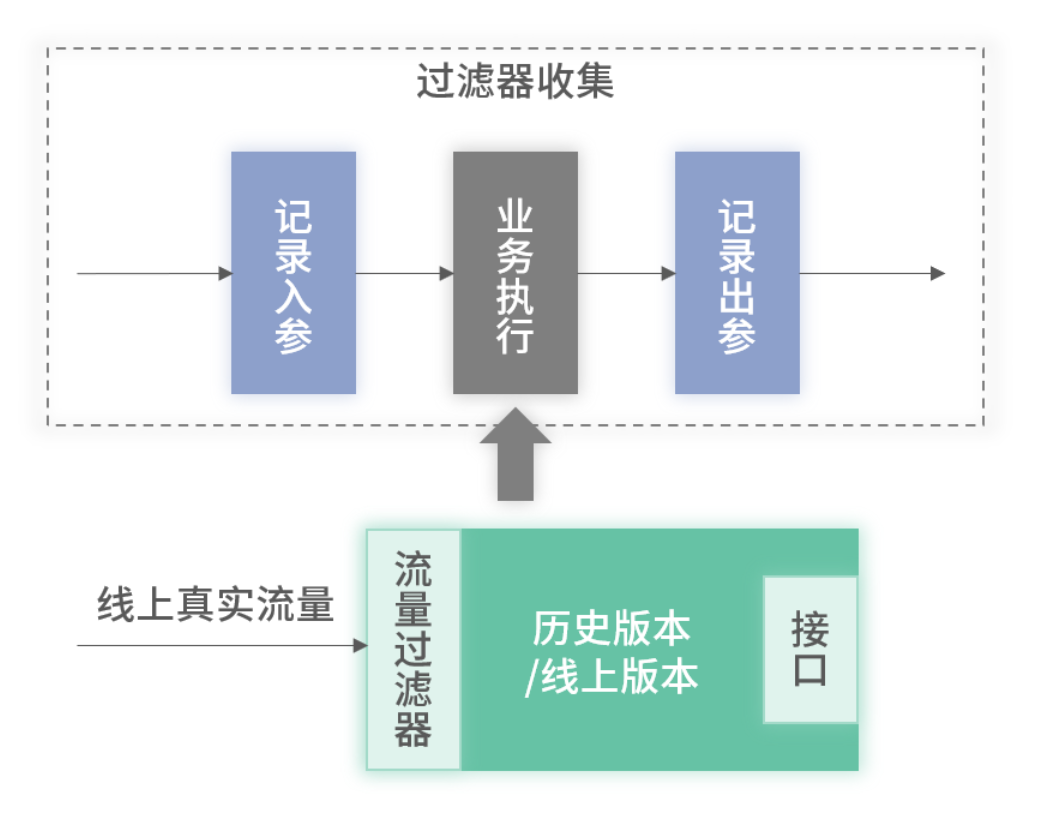
1. 拦截方式
- HTTP 接口:基于 Spring 的
Interceptor或 Servlet 的Filter拦截。 - RPC 接口:拦截 RPC 框架底层通信逻辑(如 Dubbo 的
Filter)。
拦截的请求被封装为统一格式:
{"应用名": "XXX","接口方法名": "/api/order/detail","入参": "{...}","出参": "{...}"
}
这些日志通过 MQ 推送至回归平台进行存储与处理。
2. 存储与优化策略
- 接口元数据存储在关系型数据库
- 大体量出入参数据存储在如 HBase 等高吞吐的 NoSQL
- 提供去重、清洗、采样功能,避免数据爆炸性增长
- 非业务环境如压测数据需剔除
3. 架构进化
单独进程的日志收集架构图
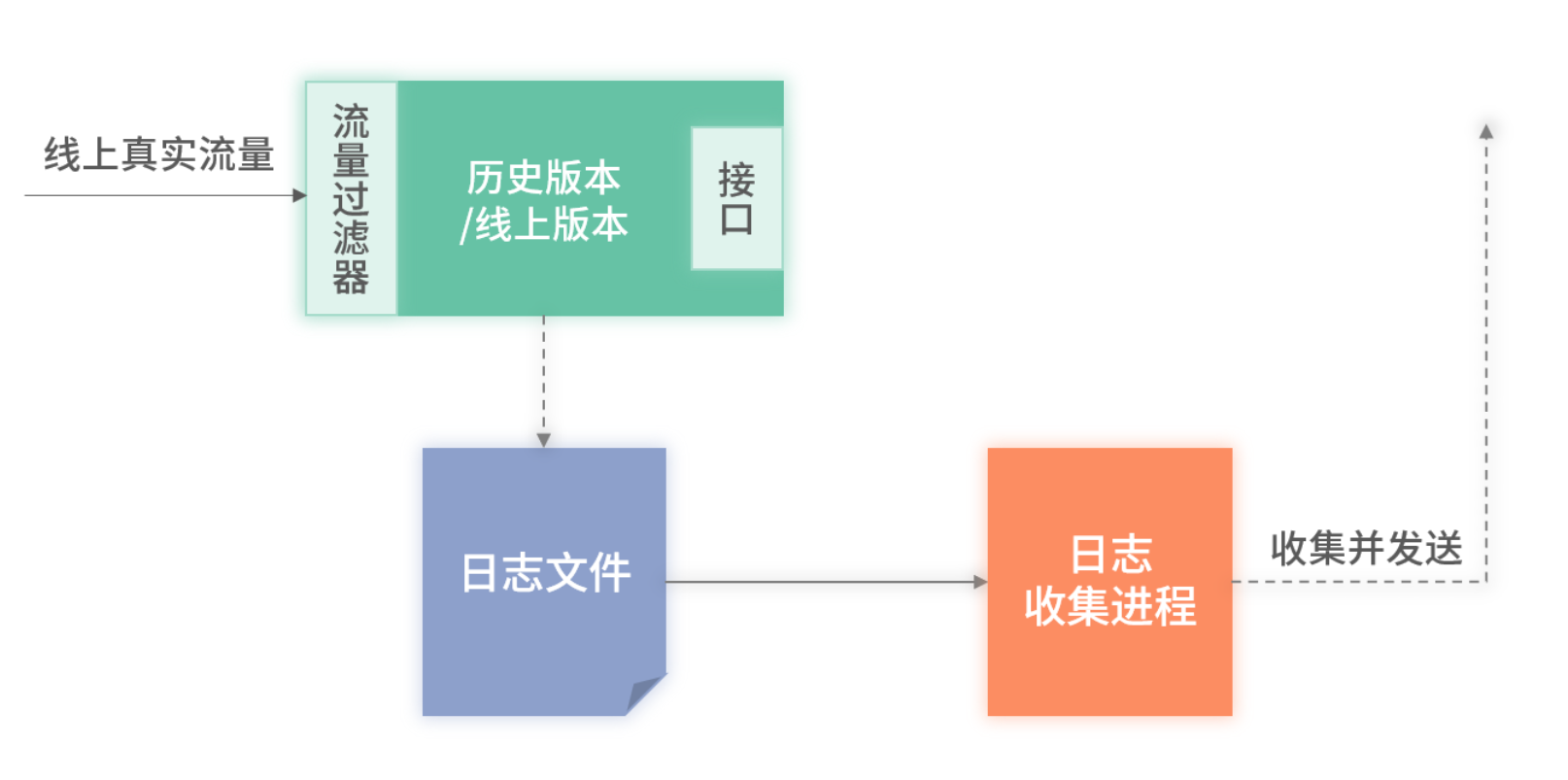
- 同进程采集:轻量集成,但存在侵入性
- 独立进程采集:将日志打印至文件,由单独进程监听并推送 MQ,降低业务系统资源占用
四、数据回放
数据回放模块模拟用户请求,通过原始日志数据中的入参信息,重放请求以获得当前版本的响应数据。
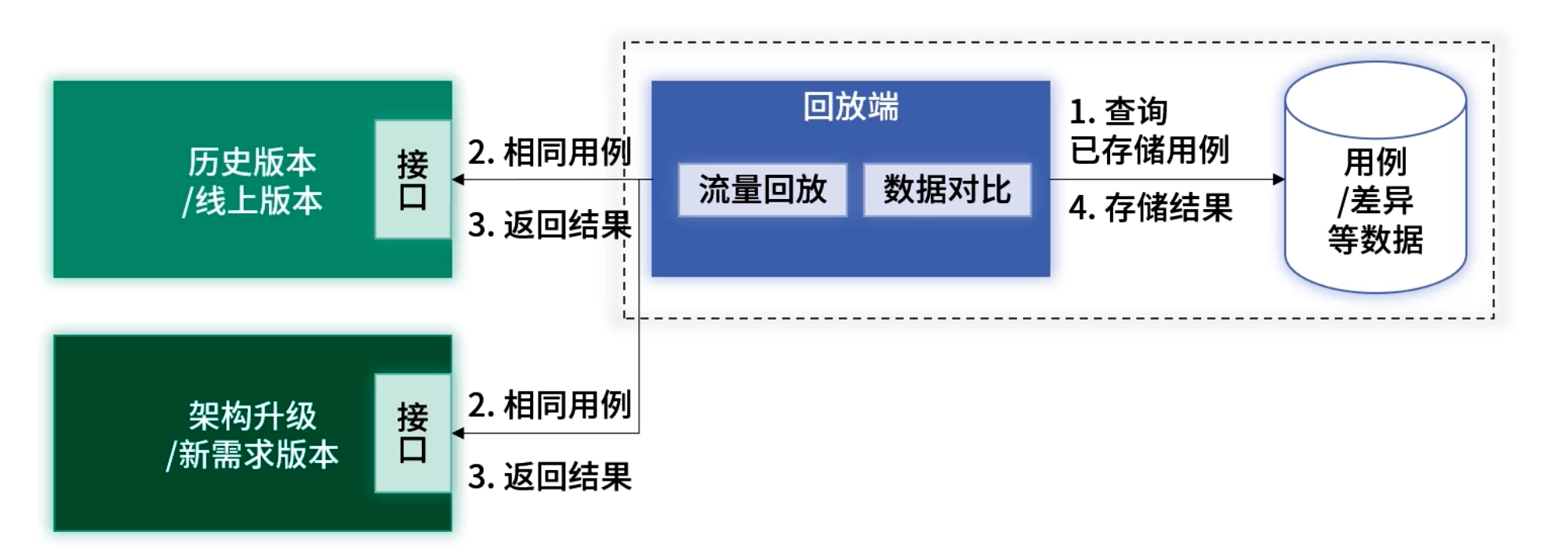
技术实现
- HTTP 接口:使用 RestTemplate、OkHttp、Apache HttpClient 等发起请求
- RPC 接口:基于 RPC 框架提供的泛化调用能力构造请求
关键能力
- 多线程并发执行,支持批量回放
- 回放任务可手动触发,也可通过策略定时运行
- 支持失败重试与限流策略,避免压垮被测服务
五、差异对比
对比模块将原始接口返回值与当前版本的回放结果进行对比,判断是否存在行为变更。
对比方式
- 文本对比(推荐):将返回结果转为 JSON 结构,逐字段比对
- 校验和对比(不推荐):判断整体一致性但缺乏定位能力
灵活配置
- 支持忽略字段配置(如 UUID、traceId)
- 支持字段级别容差设置(如时间戳误差容忍 3s)
六、三种回放模式详解
不同业务阶段与环境下,可以灵活选择回放模式:
1. 离线回放
仅调用新版本服务,使用历史日志作为“期望值”。
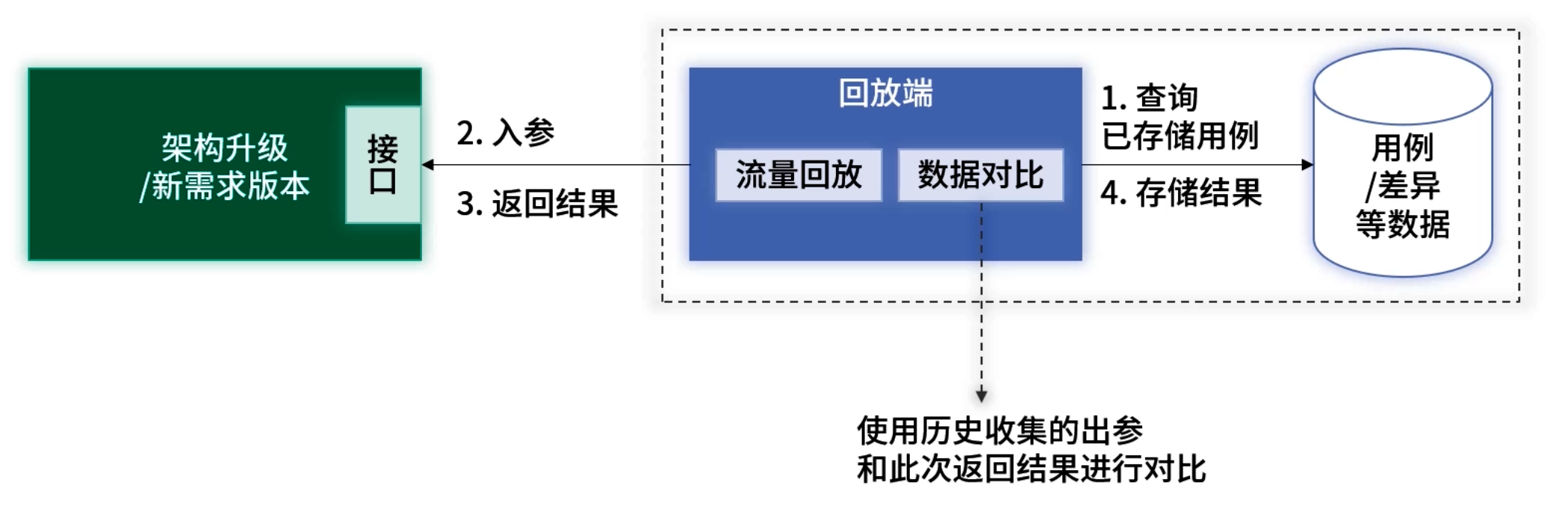
优点:不影响线上系统
缺点:若数据发生变化,对比结果失效
2. 实时回放(对比新旧服务)
手动触发后,分别调用新旧版本,实时比较返回数据。
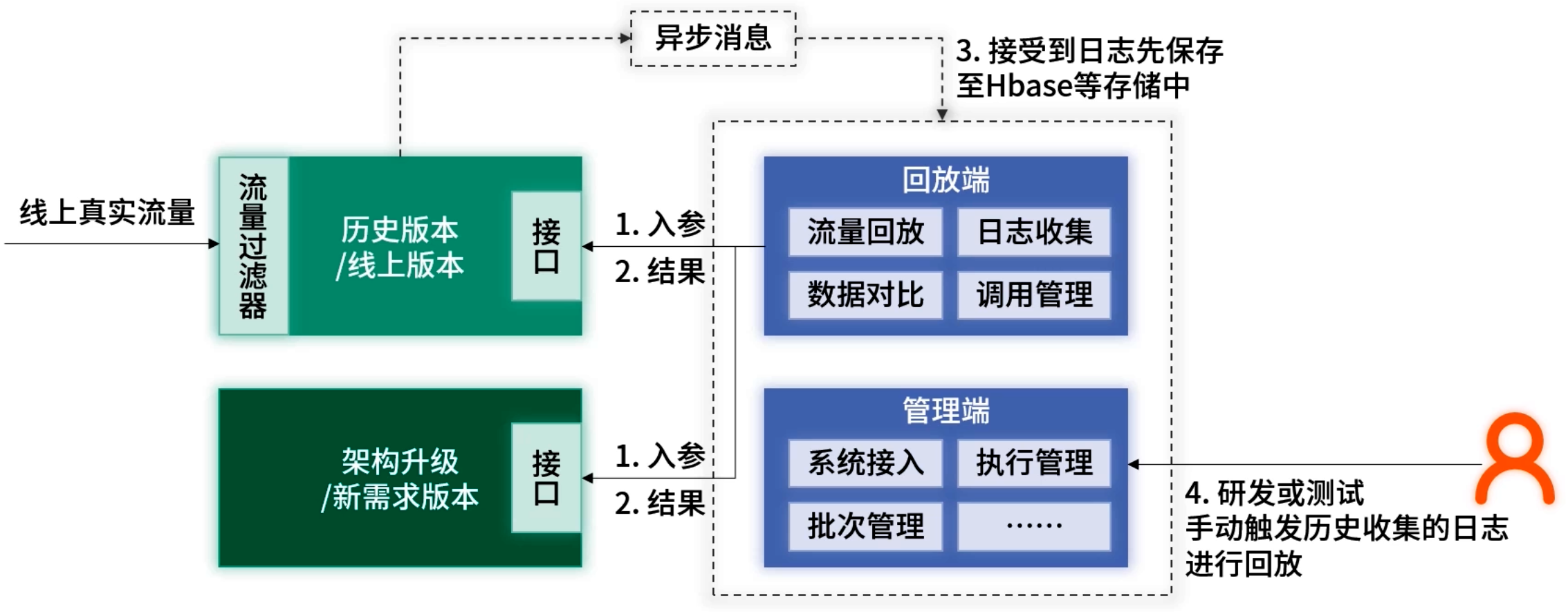
优点:规避数据变更问题,结果更真实
缺点:两次调用增加系统负载
3. 无录制实时回放
完全实时处理:日志一进入消费队列即触发双版本回放与对比。
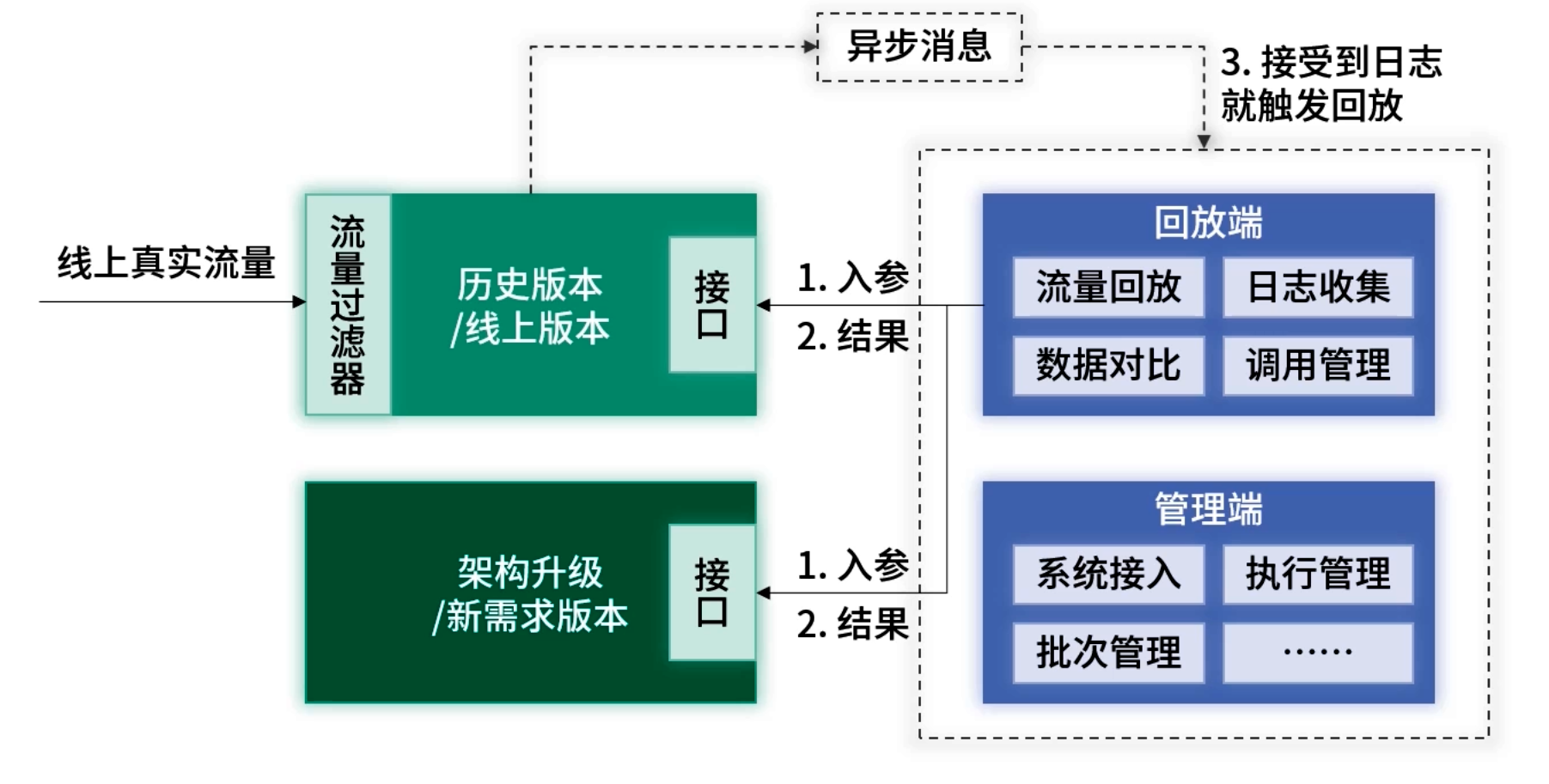
优点:最强覆盖率,避免重要场景被采样遗漏
缺点:性能压力较大,需在资源允许下谨慎使用
七、使用注意事项与最佳实践
- 屏蔽写接口:避免写接口等副作用操作回放引发业务混乱
- 合理限流:对线上环境回放要设限流阈值
- 数据存储生命周期:入参/出参数据定期清理,避免存储崩溃
- 差异字段管控:灵活配置忽略项,避免误报
- 自动告警机制:支持对比失败数据告警与可视化管理
八、模拟核心Code
package com.example.autotest;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class AutoTestApplication {public static void main(String[] args) {SpringApplication.run(AutoTestApplication.class, args);}
}// 1. 日志收集 - Spring Interceptor
package com.example.autotest.interceptor;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import com.alibaba.fastjson.JSON;
import org.springframework.beans.factory.annotation.Autowired;
import com.example.autotest.mq.LogProducer;@Component
public class LoggingInterceptor implements HandlerInterceptor {@Autowiredprivate LogProducer logProducer;@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {// 记录请求时间、请求体等RequestContextHolder.start();return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {LogRecord record = new LogRecord();record.setAppName("order-service");record.setApi(request.getRequestURI());record.setRequestBody(RequestContextHolder.getRequestBody());record.setResponseBody(RequestContextHolder.getResponseBody());// 推送到 MQlogProducer.send(JSON.toJSONString(record));}
}// 2. MQ 生产者
package com.example.autotest.mq;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;@Component
public class LogProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void send(String message) {kafkaTemplate.send("auto-test-logs", message);}
}// 3. 日志消费 & 回放触发
package com.example.autotest.consumer;import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import com.alibaba.fastjson.JSON;
import com.example.autotest.model.LogRecord;
import com.example.autotest.replay.ReplayService;@Service
public class LogConsumer {private final ReplayService replayService;public LogConsumer(ReplayService replayService) {this.replayService = replayService;}@KafkaListener(topics = "auto-test-logs")public void listen(String message) {LogRecord record = JSON.parseObject(message, LogRecord.class);// 异步触发回放replayService.submit(record);}
}// 4. 回放服务
package com.example.autotest.replay;import com.example.autotest.model.LogRecord;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import com.alibaba.fastjson.JSON;@Service
public class ReplayService {private final ExecutorService executor = Executors.newFixedThreadPool(20);private final RestTemplate restTemplate = new RestTemplate();public void submit(LogRecord record) {executor.submit(() -> {// 调用旧版接口String oldRes = restTemplate.postForObject(record.getApi(), record.getRequestBody(), String.class);// 调用新版接口(假设前缀不同)String newApi = record.getApi().replace("/v1/", "/v2/");String newRes = restTemplate.postForObject(newApi, record.getRequestBody(), String.class);// 对比结果DiffResult diff = JsonDiffComparator.compare(record.getResponseBody(), newRes);if (!diff.isEqual()) {// 记录差异或报警System.err.println("Data mismatch on API " + record.getApi() + ": " + diff.getDetails());}});}
}// 5. 差异对比工具
package com.example.autotest.replay;import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.flipkart.zjsonpatch.JsonDiff;public class JsonDiffComparator {private static final ObjectMapper mapper = new ObjectMapper();public static DiffResult compare(String expectedJson, String actualJson) {try {JsonNode e = mapper.readTree(expectedJson);JsonNode a = mapper.readTree(actualJson);JsonNode patch = JsonDiff.asJson(e, a);if (patch.size() == 0) {return new DiffResult(true, null);}return new DiffResult(false, patch.toString());} catch (Exception ex) {throw new RuntimeException(ex);}}
}// 6. 差异结果模型
package com.example.autotest.replay;public class DiffResult {private final boolean equal;private final String details;public DiffResult(boolean equal, String details) {this.equal = equal;this.details = details;}public boolean isEqual() { return equal; }public String getDetails() { return details; }
}九、小结
通过日志收集、数据回放和差异对比三大模块的组合,读服务的测试回归过程实现了自动化、精细化、可视化,彻底摆脱“人工全量测试回归”的低效流程,极大地提升了系统重构与业务迭代的安全性与效率。
