【计算机视觉】3d人脸重建:3DDFA_V2:实时高精度3D人脸重建与密集对齐技术指南

3d人脸重建:3DDFA_V2:实时高精度3D人脸重建与密集对齐技术指南
- 一、项目概述与技术背景
- 1.1 3DDFA_V2核心价值
- 1.2 技术演进路线
- 1.3 核心技术指标
- 二、环境配置与模型部署
- 2.1 硬件要求
- 2.2 软件安装
- 基础环境搭建
- 关键组件安装
- 2.3 模型下载
- 三、核心算法原理
- 3.1 多任务联合学习框架
- 3.2 改进的损失函数
- 3.3 动态权重调整策略
- 四、基础功能实战
- 4.1 单张图像重建
- 4.2 实时视频流处理
- 4.3 结果可视化
- 五、高级应用开发
- 5.1 表情迁移
- 5.2 人脸属性编辑
- 5.3 AR虚拟试妆
- 六、常见问题与解决方案
- 6.1 人脸检测失败
- 6.2 重建结果抖动
- 6.3 CUDA内存不足
- 七、模型训练与微调
- 7.1 数据集准备
- 7.2 训练命令
- 7.3 迁移学习
- 八、性能优化技巧
- 8.1 模型量化
- 8.2 多线程处理
- 8.3 TensorRT加速
- 九、学术背景与参考文献
- 9.1 核心论文
- 9.2 相关研究
- 十、应用场景与展望
- 10.1 典型应用
- 10.2 未来方向
一、项目概述与技术背景
1.1 3DDFA_V2核心价值
3DDFA_V2(3D Dense Face Alignment Version 2)是由中国科学院计算技术研究所团队开发的实时3D人脸重建框架,其核心创新在于将传统3D形变模型(3DMM)与深度学习相结合,实现了单张RGB图像到高精度3D人脸网格的端到端映射。该项目在保持实时性的前提下(>30FPS),达到了毫米级的面部细节重建精度。
1.2 技术演进路线
- 3DDFA(2016):首次将级联回归引入3D人脸对齐
- 3DDFA_V1(2018):引入UV位置图与轻量级网络
- 3DDFA_V2(2020):多任务联合学习框架,支持表情与姿态解耦
1.3 核心技术指标
| 指标 | 性能 |
|---|---|
| 输入分辨率 | 120x120 |
| 模型大小 | 9.8MB |
| 推理速度(RTX 3080) | 45 FPS |
| 关键点精度(NME) | 3.21% |
| 顶点数量 | 53,215 |
二、环境配置与模型部署
2.1 硬件要求
- GPU:NVIDIA显卡(支持CUDA 10.2+)
- 内存:4GB+(处理高清视频需8GB+)
- 摄像头:支持OpenCV的视频输入设备
2.2 软件安装
基础环境搭建
conda create -n 3ddfa_v2 python=3.7
conda activate 3ddfa_v2
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
关键组件安装
# 安装FaceBoxes检测器
cd utils/face_parsing/faceboxes/
python setup.py build_ext --inplace# 编译加速模块
cd ../../FaceBoxesV2/
python setup.py build_ext --inplace
2.3 模型下载
sh scripts/download_models.sh
模型文件结构:
models/
├── phase1_wpdc_vdc.pth.tar # 主重建模型
├── faceboxes.pth # 人脸检测器
└── segmentation_resnet18_epoch.pth # 人脸解析模型
三、核心算法原理
3.1 多任务联合学习框架
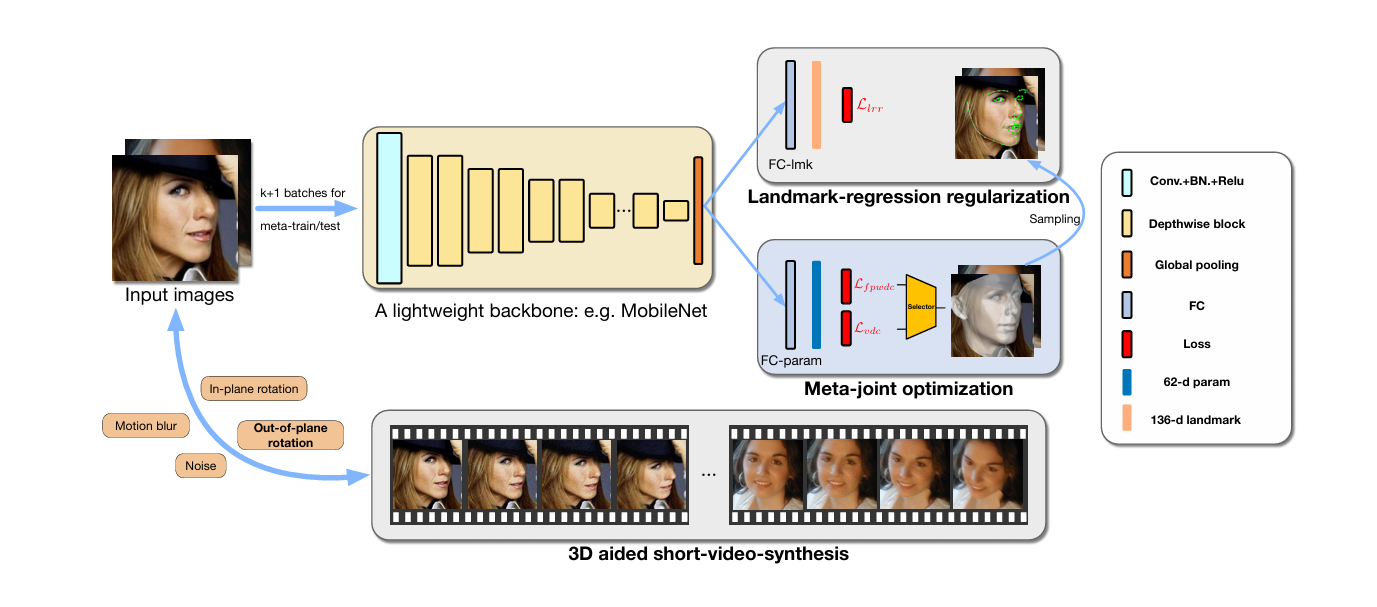
网络同时优化以下目标:
- 3DMM参数回归:62维形状参数+40维表情参数
- 顶点稠密对齐:通过UV位置图编码三维坐标
- 人脸属性解析:皮肤、眉毛等区域的语义分割
3.2 改进的损失函数
L = λ w p d c L w p d c + λ v d c L v d c + λ l m k L l m k + λ s e g L s e g \mathcal{L} = \lambda_{wpdc}\mathcal{L}_{wpdc} + \lambda_{vdc}\mathcal{L}_{vdc} + \lambda_{lmk}\mathcal{L}_{lmk} + \lambda_{seg}\mathcal{L}_{seg} L=λwpdcLwpdc+λvdcLvdc+λlmkLlmk+λsegLseg
其中:
- L w p d c \mathcal{L}_{wpdc} Lwpdc:加权参数距离损失
- L v d c \mathcal{L}_{vdc} Lvdc:顶点稠密约束损失
- L l m k \mathcal{L}_{lmk} Llmk:68个关键点监督
- L s e g \mathcal{L}_{seg} Lseg:人脸解析分割损失
3.3 动态权重调整策略
不同训练阶段自动调整损失权重:
λ ( t ) = λ b a s e ⋅ γ t / T \lambda^{(t)} = \lambda_{base} \cdot \gamma^{t/T} λ(t)=λbase⋅γt/T
γ = 0.9 \gamma=0.9 γ=0.9控制权重衰减速率
四、基础功能实战
4.1 单张图像重建
from TDDFA import TDDFA
from utils.functions import get_suffix# 初始化模型
cfg = Config(gpu_mode=True,model_path='models/phase1_wpdc_vdc.pth.tar'
)
tddfa = TDDFA(**cfg)# 输入处理
img = cv2.imread('examples/inputs/emma.jpg')
boxes = face_detector(img, 1) # 人脸检测# 三维重建
param_lst, roi_box_lst = tddfa(img, boxes)
ver_lst = tddfa.recon_vers(param_lst, roi_box_lst) # 获取顶点坐标
4.2 实时视频流处理
from utils.visualization import Visualization# 创建可视化对象
vis = Visualization(tddfa=tddfa,dense_flag=True,video_writer=cv2.VideoWriter('output.mp4', ...)
)# 开启摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break# 处理帧param_lst, roi_box_lst = tddfa(frame, [detect_face(frame)])vis.draw(frame, param_lst, roi_box_lst)cap.release()
4.3 结果可视化
导出OBJ格式三维模型:
from utils.serialization import ser_to_objser_to_obj(ver_lst[0], # 顶点坐标tddfa.tri, # 三角面片'output.obj', texture=img # 纹理贴图
)
五、高级应用开发
5.1 表情迁移
def expression_transfer(source_params, target_params):# 提取表情参数(第62-102维)exp_params = source_params[62:102]# 保持目标形状参数trans_params = np.concatenate([target_params[:62],exp_params,target_params[102:]])return trans_params# 应用迁移
new_ver = tddfa.recon_vers([trans_params], [roi_box])[0]
5.2 人脸属性编辑
# 修改3DMM参数
def adjust_age(params, delta=0.3):# 年龄对应第3个形状参数params[3] += deltareturn params# 更新模型
aged_ver = tddfa.recon_vers([adjusted_params], [roi_box])[0]
5.3 AR虚拟试妆
# 加载口红纹理
lip_texture = cv2.imread('lip_sticker.png', cv2.IMREAD_UNCHANGED)# 获取唇部区域顶点
lip_verts = ver_lst[0][tddfa.lip_idx]# 投影到2D平面
lip_proj = tddfa.project(ver=lip_verts)
lip_roi = cv2.boundingRect(lip_proj)# 融合纹理
alpha = lip_texture[:, :, 3] / 255.0
for c in range(3):frame[lip_roi[1]:lip_roi[3], lip_roi[0]:lip_roi[2], c] = \alpha * lip_texture[:, :, c] + (1 - alpha) * frame[...]
六、常见问题与解决方案
6.1 人脸检测失败
现象:boxes列表为空
解决方法:
- 调整检测阈值:
boxes = face_detector(img, conf_th=0.8) # 降低阈值 - 使用备用检测器:
from utils.detector import SCRFDDetector detector = SCRFDDetector(model_path='models/scrfd_500m.pth') boxes = detector.detect(img)
6.2 重建结果抖动
优化策略:
- 启用时序平滑:
tddfa = TDDFA(..., smooth=True, smooth_window=5) - 卡尔曼滤波:
from utils.kalman_filter import KalmanFilter kf = KalmanFilter(dim_x=62+40+3) params = kf.update(current_params)
6.3 CUDA内存不足
错误信息:CUDA out of memory
解决方案:
- 减小输入分辨率:
cfg = Config(bfm_size=120) # 默认120x120 - 释放缓存:
torch.cuda.empty_cache() - 使用CPU模式:
cfg = Config(gpu_mode=False)
七、模型训练与微调
7.1 数据集准备
推荐数据集:
- 300W-LP:合成的大姿态人脸数据集
- AFLW2000-3D:真实世界多姿态数据
- CelebA:人脸属性标注数据
目录结构:
data/
├── images/
│ ├── 0001.jpg
│ └── ...
├── params/
│ ├── 0001.npy
│ └── ...
└── seg_maps/├── 0001.png└── ...
7.2 训练命令
python training/train.py \--config configs/mb0.3_phase1.yaml \--training_data data/train.list \--val_data data/val.list \--checkpath checkpoints/
关键参数:
--net_stride:网络下采样率--loss_weights:各损失项权重--warmup_epochs:学习率预热
7.3 迁移学习
微调特定属性:
# 冻结基础层
for param in model.backbone.parameters():param.requires_grad = False# 仅训练表情相关层
optimizer = torch.optim.Adam(model.exp_layer.parameters(), lr=1e-4)
八、性能优化技巧
8.1 模型量化
from torch.quantization import quantize_dynamic# 动态量化
quantized_model = quantize_dynamic(model,{torch.nn.Linear},dtype=torch.qint8
)
torch.save(quantized_model.state_dict(), 'model_quant.pth')
8.2 多线程处理
from concurrent.futures import ThreadPoolExecutordef process_frame(frame):return tddfa(frame)with ThreadPoolExecutor(max_workers=4) as executor:futures = [executor.submit(process_frame, f) for f in frame_batch]results = [f.result() for f in futures]
8.3 TensorRT加速
python utils/trt_converter.py \--onnx models/phase1_wpdc_vdc.onnx \--engine models/phase1.engine \--fp16
九、学术背景与参考文献
9.1 核心论文
-
3DDFA_V2:
“Towards Fast, Accurate and Stable 3D Dense Face Alignment” (ECCV 2020)
创新点:多任务联合学习框架、动态权重调整策略 -
3DMM模型:
“A 3D Face Model for Pose and Illumination Invariant Face Recognition” (AVSS 2009) -
UV位置图:
“Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network” (CVPR 2017)
9.2 相关研究
-
Face Alignment:
“How Far are We from Solving the 2D & 3D Face Alignment Problem?” (ICCV 2019) -
Neural Rendering:
“HeadNeRF: A Real-time NeRF-based Parametric Head Model” (CVPR 2022)
十、应用场景与展望
10.1 典型应用
- 虚拟形象生成:游戏角色实时驱动
- 人脸属性分析:年龄/性别/表情识别
- AR/VR交互:虚拟试戴与实时换脸
- 医疗美容:整形手术效果模拟
10.2 未来方向
- 高分辨率重建:支持4K级面部细节
- 动态表情建模:微表情捕捉与再现
- 跨模态生成:文本/语音驱动人脸动画
- 轻量化部署:移动端实时推理优化
通过掌握3DDFA_V2的技术细节与实践方法,开发者能够在人脸相关AI应用中快速构建高精度、实时的三维视觉解决方案,推动虚拟现实、智能交互等领域的技术创新。