【AI论文】Phi-4-reasoning技术报告
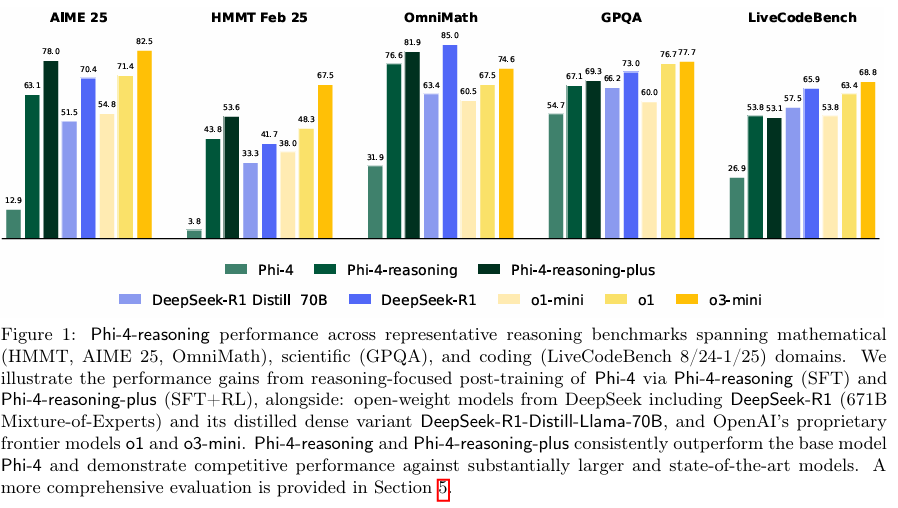
摘要:我们引入了Phi-4-reasoning,这是一种拥有140亿参数的推理模型,在复杂的推理任务中表现出了强大的性能。 通过监督式微调Phi-4,在精心策划的“可教”提示集上进行训练,这些提示集是根据复杂性和多样性的适当水平选择的,并且使用o3-mini生成的推理演示,Phi-4推理生成详细的推理链,有效地利用推理时的计算。 我们进一步开发了Phi-4-reasoning-plus,这是一种通过短期的基于结果的强化学习而增强的变体,通过生成更长的推理轨迹来提供更高的性能。 在广泛的推理任务中,这两个模型都优于更大的开放权重模型,如DeepSeek-R1-Distill-Llama-70B模型,并接近完整的DeepSeek-R1模型的性能水平。 我们的综合评估涵盖了数学和科学推理、编码、算法问题解决、规划和空间理解等基准。 有趣的是,我们也观察到通用基准测试的改进并非微不足道。 在本报告中,我们提供了有关我们的训练数据、训练方法和评估的见解。 我们证明,对监督式微调(SFT)进行仔细的数据管理的好处可以扩展到推理语言模型,并且可以通过强化学习(RL)进一步放大。 最后,我们的评估指出了改进我们评估推理模型的性能和鲁棒性的机会。Huggingface链接:Paper page,论文链接:2504.21318
研究背景和目的
研究背景
近年来,以大型语言模型(LLMs)为代表的人工智能技术在自然语言处理领域取得了显著进展。特别是针对复杂推理任务的语言模型,如OpenAI的o1、o3-mini,Anthropic的Claude-3.7-Sonnet-Thinking,Google的Gemini-2-Thinking和Gemini-2.5-Flash,以及DeepSeek-AI的DeepSeek-R1等,这些模型通过多步分解、内部反思和多种问题解决策略的探索,展示了在复杂任务上的强大能力。然而,这些模型往往参数规模巨大,训练成本高昂,限制了其广泛应用。
与此同时,随着数据驱动方法的兴起,研究者们开始探索如何通过精心策划的数据集和高效的训练策略,在较小规模的模型上实现接近甚至超越大型模型的推理性能。DeepSeek-R1通过监督微调(SFT)将大型语言模型的先进推理能力蒸馏到较小模型中,展示了数据驱动方法的潜力。进一步的研究表明,通过强化学习(RL)可以进一步提升这些小型模型的性能。
研究目的
本研究旨在开发一种名为Phi-4-reasoning的140亿参数推理模型,通过监督微调(SFT)和强化学习(RL)技术,在复杂推理任务上实现高性能,同时保持较小的模型规模。具体研究目的包括:
- 开发高效推理模型:通过精心策划的训练数据和高效的训练策略,开发出在复杂推理任务上表现优异的Phi-4-reasoning模型。
- 探索数据驱动方法:研究数据策划和监督微调对推理语言模型性能的影响,特别是通过高质量、多样化的训练数据集提升模型推理能力。
- 结合强化学习:在Phi-4-reasoning基础上,通过短期的基于结果的强化学习,开发出性能更优的Phi-4-reasoning-plus模型,验证强化学习在提升模型推理能力方面的有效性。
- 全面评估模型性能:在多个推理基准测试上评估Phi-4-reasoning和Phi-4-reasoning-plus的性能,包括数学和科学推理、编码、算法问题解决、规划和空间理解等领域,并探讨模型在通用基准测试上的表现。
研究方法
数据策划与预处理
- 种子数据库构建:从各种网络来源收集多样化的问题集,并补充通过高质量、过滤后的网络内容生成的合成问题。种子数据库涵盖了STEM(科学、技术、工程和数学)领域、编码以及一般性问答风格的提示。
- 筛选“可教”样本:针对Phi-4模型的当前能力边界,筛选出具有适当复杂性和多样性的提示。通过LLM评估和过滤管道,优先选择需要复杂多步推理的提示,而非主要测试事实回忆的提示。
- 合成推理轨迹:使用o3-mini模型生成高质量的推理轨迹和最终答案,形成结构化的“思考”和“答案”块,作为监督微调的训练数据。
监督微调(SFT)
- 模型架构调整:在Phi-4模型的基础上,通过重新利用两个占位符令牌作为“思考”和“结束思考”标记,增加最大令牌长度至32K,以适应更长的推理轨迹。
- 训练数据:使用超过140万个提示-响应对,总计83亿个唯一令牌,涵盖数学、编码和安全对齐数据。
- 训练过程:通过大约16K步的训练,全局批量大小为32,上下文长度为32K令牌,使用AdamW优化器,学习率为10^-5。^[19]^
强化学习(RL)
- 奖励函数设计:采用基于规则的奖励模型,激励正确性,惩罚不良行为(如重复、过长),并鼓励适当的响应格式。主要奖励组件是长度感知的准确率得分,根据答案的正确性和生成长度调整奖励。
- 训练数据与过程:从较大的训练语料库中筛选出72,401个数学问题作为种子数据集,每次RL迭代中抽取64个问题种子。^[22]^使用Group Relative Policy Optimization(GRPO)算法进行训练,全局批量大小为64,Adam优化器学习率为5×10^-8。^[23]^
研究结果
推理性能提升
- 数学和科学推理:Phi-4-reasoning和Phi-4-reasoning-plus在数学基准测试(如AIME、OmniMath)上表现出色,准确率相比基础模型Phi-4提升了超过50个百分点。在科学推理基准测试(如GPQA)上,也展示了接近或超越更大规模模型(如DeepSeek-R1)的性能。
- 编码与算法问题解决:在编码基准测试(如LiveCodeBench)上,Phi-4-reasoning和Phi-4-reasoning-plus的准确率相比Phi-4提升了超过25个百分点。在算法问题解决和规划任务(如3SAT、TSP、BA-Calendar Planning)上,也展示了显著的泛化能力,准确率提升了30至60个百分点。
通用基准测试表现
- 指令遵循与长上下文问答:Phi-4-reasoning-plus在指令遵循(IFEval)和长上下文问答与推理(FlenQA)等通用基准测试上表现出色,准确率相比Phi-4分别提升了22和16个百分点。
- 聊天交互偏好:在ArenaHard基准测试上,Phi-4-reasoning-plus的准确率提升了10个百分点,展示了在聊天式交互中的人类偏好。
安全性评估
- 毒性语言检测:在Toxigen基准测试上,Phi-4-reasoning在检测有毒和中性文本方面表现出色,平衡了有毒与中性内容检测的准确性,有助于内容审核和过滤应用。
- 安全性指南遵循:通过详细的安全性指南,模型在响应中隐含地学习了预期行为,尽管在回答块中不透露指南或思考轨迹,但仍展示了良好的安全性表现。
研究局限
- 模型规模与参数限制:Phi-4-reasoning模型虽然实现了高性能,但其140亿参数的规模相比一些更大规模的模型(如DeepSeek-R1的6710亿参数)仍然较小,可能在某些复杂任务上存在性能瓶颈。
- 训练数据多样性:尽管通过精心策划的数据集提升了模型的推理能力,但训练数据仍主要集中在STEM领域和编码任务上,对于其他领域的推理任务可能表现有限。
- 推理过程可解释性:尽管模型能够生成详细的推理轨迹,但这些轨迹的可解释性仍然有限,特别是在处理复杂问题时,模型可能产生与自身推理链相矛盾的响应。
- 上下文长度限制:模型的上下文长度限制为32K令牌,对于需要更广泛上下文的任务可能不够用,导致信息截断和丢失。
未来研究方向
-
扩大模型规模与优化训练策略:未来研究可以探索扩大模型规模,同时优化训练策略,以进一步提升模型的推理能力和泛化性能。通过引入更多的训练数据和更高效的训练算法,可能在小规模模型上实现接近甚至超越更大规模模型的性能。
-
增强推理过程可解释性:开发新的技术和方法,以提高模型推理过程的可解释性。通过可视化工具、注意力机制分析等手段,帮助用户更好地理解模型的推理过程,提高模型的透明度和可信度。
-
拓展训练数据领域:将训练数据拓展到更多领域,包括社会科学、人文科学等,以提升模型在更广泛任务上的推理能力。通过跨领域数据的学习,模型可能获得更全面的知识和推理能力,从而在更多复杂任务上表现出色。
-
探索更长的上下文处理能力:研究如何提升模型的上下文处理能力,以适应更广泛的任务需求。通过改进模型架构、优化训练算法等手段,可能实现更长的上下文处理,从而在需要广泛上下文的任务上表现更佳。
-
强化安全性和伦理考量:在模型开发和应用过程中,进一步强化安全性和伦理考量。通过引入更多的安全机制和伦理准则,确保模型在各种应用场景下的安全性和可靠性。同时,研究模型在处理敏感信息时的表现,确保模型不会泄露用户隐私或产生不当内容。
-
多模态推理能力:探索将语言模型与视觉、听觉等多模态信息相结合,开发具有多模态推理能力的模型。通过处理和理解多模态信息,模型可能在更复杂的任务上表现出色,如图像描述、视频理解等。
-
持续学习与自适应能力:研究模型的持续学习和自适应能力,使其能够在不断变化的环境中保持高性能。通过引入在线学习、增量学习等技术,模型可能不断吸收新知识,适应新任务,从而在更广泛的应用场景中发挥作用。
综上所述,本研究通过开发Phi-4-reasoning和Phi-4-reasoning-plus模型,展示了在小规模模型上实现高性能推理能力的潜力。未来研究将进一步探索扩大模型规模、增强推理过程可解释性、拓展训练数据领域、探索更长的上下文处理能力、强化安全性和伦理考量、开发多模态推理能力以及提升持续学习与自适应能力等方面,以推动推理语言模型技术的进一步发展。