0.0973585?探究ts_rank的score为什么这么低
最近在使用postgres利用ts_rank进行排序找到最符合关键词要求得内容时发现: 即使是相似的内容,得分也是非常非常得低(其中一个case是0.0973585)。看起来很奇怪,非常不可行。于是我又做了一个简单测的测试:
SELECT ts_rank(to_tsvector('english', 'skirt'), to_tsquery('skirt'));讲道理,这已经是完全匹配得内容了,预期得分应该非常高(如果按匹配度来看应该有1了),但实际得rank分数却是非常得低:
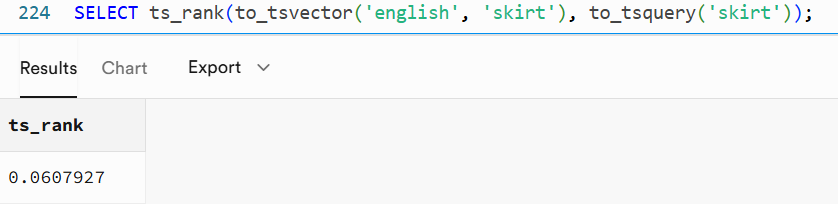
这就引出了一个问题:为什么分数这么低?这么低的分数是不是对的?ts_rank时得计算逻辑是怎样的?带着这个疑问,我们深入探究一下。
postgres全文搜索
ts_vector
ts_vector是postgres中用于全文检索的主要结构,在这个结构中,会将文本信息转换为词位 + 位置信息的格式。
SELECT to_tsvector('english', 'The quick brown fox jumps over the lazy dog'); -- 结果: 'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2ts_query
表示搜索的查询条件
SELECT to_tsquery('english', 'jumping & quick'); -- 结果: 'jump' & 'quick'全文搜索流程
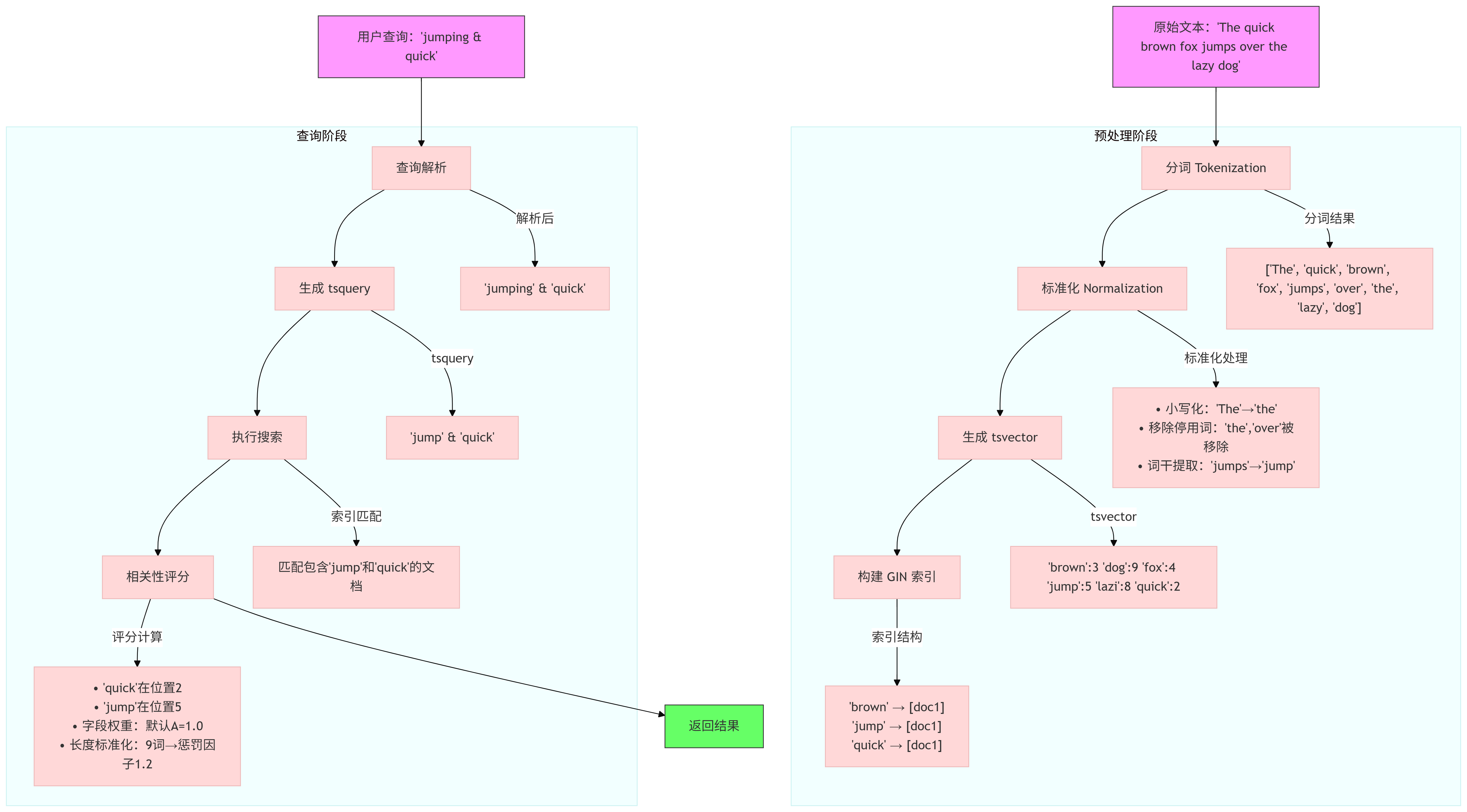
基于上面的示例,我们来看一下这里全文搜索的流程。整个处理过程如上图所示。
预处理阶段
预处理阶段首先会对文本内容进行分词,得到一个个token,然后会对这里的分词结果进行一系列标准化操作,比如转小写、移除一些停用词、词干提取等。再之后,就会生成包含词位和位置信息的ts_vector。之后,为了加速检索,还可以为这部分内容建立gin索引。
查询阶段
查询时会先对查询内容进行解析,然后生成对应的ts_query结构,最后执行索引匹配,获取相关相关性评分,最终得到一个最终的评分结果。前文提到的ts_rank发生在相关性评分处。
ts_rank
calc_rank是ts_rank的核心方法,它根据输入的权重 (weights)、文本向量 (TSVector)、查询 (TSQuery) 和指定的归一化方法 (method) 来计算相关性评分。顺着源码来看下
calc_rank(const float *w, TSVector t, TSQuery q, int32 method)
{QueryItem *item = GETQUERY(q);float res = 0.0;int len;if (!t->size || !q->size)return 0.0;/* XXX: What about NOT? */