Jasper and Stella: distillation of SOTA embedding models
摘要
Dense检索是许多深度学习应用系统中(例如常见问题 (FAQ) 和检索增强生成 (RAG))关键组成部分。在此过程中,Embedding模型将原始文本转换为向量。然而,目前在文本Embedding基准测试中表现出色的Embedding模型,如海量文本嵌入基准测试 (MTEB),通常具有许多参数和高向量维度。这给它们在实际场景中的应用带来了挑战。为了解决这个问题,我们提出了一种新的多阶段蒸馏框架,使较小的学生嵌入模型能够通过三个精心设计的损失来提取多个较大的教师嵌入模型。同时,我们利用俄罗斯套娃表示学习 (MRL) 来有效地降低学生嵌入模型的向量维数。我们名为 Jasper 的学生模型拥有 20 亿个参数,基于 Stella 嵌入模型构建,在 MTEB 排行榜上排名第三(截至 2024 年 12 月 24 日),在 56 个数据集中取得了 71.54 的平均分。我们已经在 Hugging Face Hub 上发布了模型和数据 ,同时公布了训练代码。
https://huggingface.co/NovaSearch/jasper_en_vision_language_v1
https://huggingface.co/datasets/infgrad/jasper_text_distill_dataset
https://github.com/NovaSearch-Team/RAG-Retrieval
论文贡献
1、我们提出了一种新的多阶段蒸馏框架,它使较小的学生嵌入模型能够通过三个精心设计的损失函数有效地从多个较大的教师嵌入模型中提炼知识。
2、我们的 2B Jasper 模型在 MTEB 排行榜上获得了第 3 名(截至 2024 年 12 月 24 日),效果与其他排名靠前的 7B 嵌入模型相当,并且明显优于其他参数小于 2B 的模型。
模型结构
我们的学生模型架构遵循将语言模型与视觉编码器相结合的简单标准设计。如下图所示,它由四个组件组成:
1、一种基于编码器的语言模型,通过均值池化生成文本Embedding。
2、一个视觉编码器,可将图像独立映射到视觉Token Embedding中。
3、一个池化程序,它将视觉Token Embedding映射到与语言模型的输入文本Embedding相同的维度,同时减少视觉Token序列的长度。
4、多个全连接 (FC) 层,用于将嵌入投影到最终输出的特定维度。
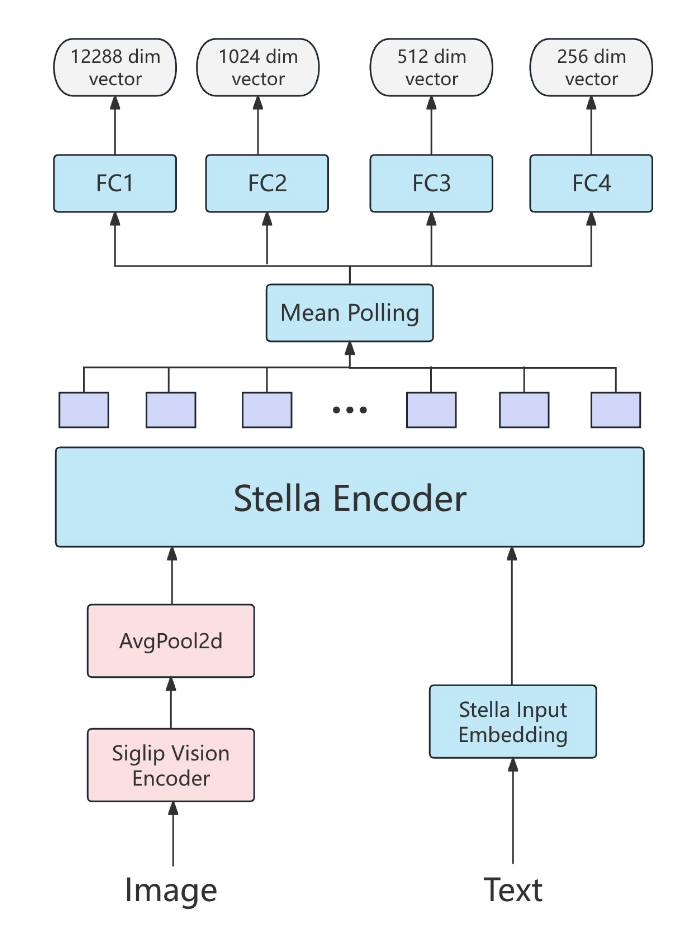
阶段 1&2: 基于多教师的蒸馏
具体来说,我们采用 NV-Embed-v25 和 stella_en_1.5B_v56 作为教师模型,它们的向量维度分别为 4096 和 8192。映射过程完成后,学生模型的向量维度被调整为 12288,等于两个教师模型的组合向量维度 (4096 + 8192)。
前两个阶段的目标是通过将其输出向量与相应的教师向量对齐,使学生模型能够有效地从多个教师模型中学习文本表示。为了实现这一目标,我们精心设计了三个损失函数,从具体的角度发展到更广泛的角度。第一个损失函数是余弦损失,其公式如下:
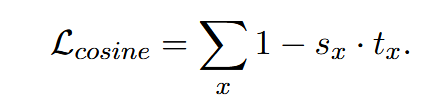
Lcosine 值通常不会收敛到零,这表明学生和教师之间存在持续的角度差异。同时,从单个文本得出的逐点信号具有有限的优化方向,这很容易导致训练数据过拟合。为了补充 Lcosine 的局限性,我们引入了第二个损失函数,它从文本对的角度模拟了学生和教师模型之间的语义匹配差异。这个损失函数确保了学生模型和教师模型之间相似性的相对一致的判断,而不强制学生模型和教师模型之间的绝对拟合。
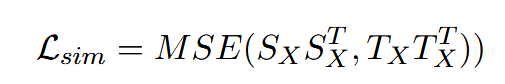
为了进一步利用相对比较信号,受 CoSENT loss 的启发,我们提出了第三个损失函数,相对相似性蒸馏损失。
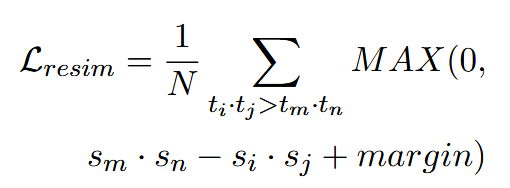
对于每批文本数据,我们采用教师模型为所有文本对自动生成软标签,从而识别潜在的正负样本。随后,对学生模型进行训练,以确保正对之间的相似性超过负对之间的相似性,margin超参数控制这种差异的程度。
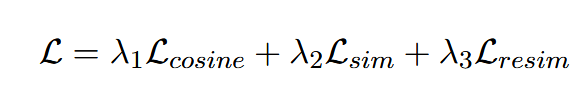
最终损失 L 是上述三个损失函数的加权和。其中 λ1、λ2 和 λ3 是超参数。蒸馏向量的最大优点是我们不需要任何监督数据。值得注意的是,阶段 1 和阶段 2 之间的主要区别在于训练的参数。在第 1 阶段,仅训练全连接层 (FC1),而在第 2 阶段,全连接层 (FC1) 和学生模型的最后三个编码器层都接受训练。
sx:学生模型生成的文本 x 的规范化向量表示。
tx:同一文本 x 的向量表示形式,首先规范化,然后连接,然后再次规范化,由多个教师模型生成。
SX :学生模型生成的一批文本 X 的归一化向量表示矩阵。
TX : 同一批文本 X 的相应向量表示矩阵,首先标准化,然后连接,随后再次标准化,由多个教师模型生成。
阶段 3:降维
受 MRL (Kusupati et al., 2024) 的启发,我们引入了三个额外的独立全连接层(FC2、FC3 和 FC4)来生成低维向量,每个向量都实现了不同程度的降维。例如,通过将全连接层 FC3 与 (15368, 512) 合并,我们获得了更易于管理的 512 维向量空间。
对于三个 FC 层,由于简化向量的维度与串联教师向量的维度不一致,因此省略了 Lcosine,只使用 Lsim 和 Lresim。为了确保从 FC1 层生成的向量(即 12288 维向量)的准确性,它们将继续使用所有三个损失函数进行训练。在此阶段,将训练 student 模型的所有参数。
第 4 阶段:训练多模态能力
在第 4 阶段,我们利用图像-描述对作为训练数据集,专注于训练视觉编码器,同时保持其他组件冻结。训练过程基于自蒸馏,其中描述的向量表示充当教师向量,图像的向量表示充当学生向量。前面阶段引入的所有全连接层都用于生成多对学生和教师向量。对于每对,我们计算 3 次亏损,然后将其平均以获得最终的亏损。
需要注意的是,此阶段仅实现了文本和图像模态之间的初步对齐,留下了很大的改进空间。在未来的工作中,我们的目标是进一步探索和完善模态对齐过程。
实验
具体设置
我们名为 Jasper 的模型是从 stella_en_1.5B_v5 和 google/siglip-so400mpatch14-384 初始化的(Zhai et al., 2023;Alabdulmohsin et al., 2024)。stella_en_1.5B_v5 和 NV-Embed-v2 是我们的教师模型。我们的 Jasper 模型中的参数总数为 1.9B(stella 1.5B 参数和 siglip 400M 参数)。对于超参数,我们设置 λ1 = 10,λ2 = 200,λ3 = 20,margin = 0.015。
在所有四个阶段中,模型都使用 8 × RTX A6000 GPU 进行训练,最大输入长度为 512 个Token、混合精度训练 (BF16)、DeepSpeed ZERO-stage-2 和 AdamW 优化器。在第 1 阶段(蒸馏训练)期间,批量大小设置为 128,学习率为每步 1e-4,并选择第 4000 步的模型检查点作为最终模型。在第 2 阶段(也是蒸馏训练)的情况下,批量大小保持为 128,学习率下降到每步 8e-5,最终模型是第 7000 步的检查点。对于第 3 阶段(降维训练),batch size 再次为 128,学习率调整为每步 7e5,第 2200 步的检查点作为最终模型。最后,在第 4 阶段(多模态训练)中,批量大小减少到 90,学习率恢复到每步 1e-4,最终模型从第 3500 步的检查点中选择。
数据集
在第 1 阶段、第 2 阶段和第 3 阶段,我们使用 fineweb-edu (Lozhkov et al., 2024) 作为我们的主要文本训练数据集,它占全文数据的 80%。其余 20% 的文本数据来自 sentence-transformers/embedding-trainingdata9。我们选择 sentencetransformers/embedding-training-data 的原因是 fineweb-edu 的大部分数据由段落组成。但是,除了段落之外,我们还需要问题来增强训练数据的多样性。文本训练数据总量为 800 万。
对于数据集中的文档,我们执行以下作:
1. 我们随机选择 30% 的文档,将它们分成短文本,每个文本由 1 到 10 个句子组成。
2. 我们随机选择 0.08% 的文本并随机排列其中的单词。
在第 4 阶段,我们使用 BAAI/Infinity-MM 的图片-标题数据(Gu et al., 2024)作为我们的视觉训练数据。
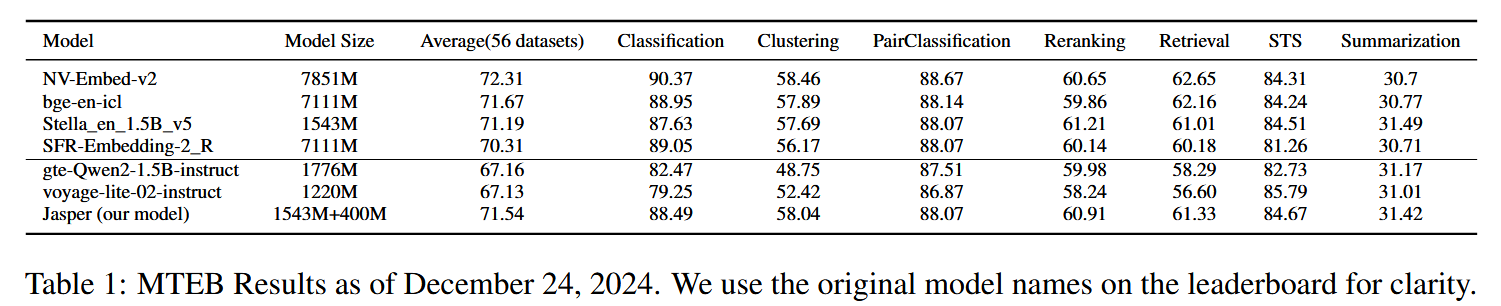
结果
我们在完整的 MTEB 基准上评估了所提出的 Jasper 和 Stella 模型,其中包括 15 个检索数据集、4 个重新排序数据集、12 个分类数据集、11 个聚类数据集、3 个对分类数据集、10 个语义文本相似性数据集和 1 个摘要数据集。
讨论
指令稳健性
基于指令的Embedding模型要求在文本编码期间将指令添加到查询或段落中。目前,许多最先进的文本Embedding模型使用指令来提示模型并获得更好的Embedding。与大型语言模型的使用类似 (Zhao et al., 2024b),不同的任务需要不同的指令,这既合乎逻辑又直观。因此,理解指令的能力对于这些文本Embedding模型至关重要。Jasper 也是一种基于指令的Embedding模型。为了证明不同提示对 Jasper 模型的影响,我们进行了一个简单的实验。具体来说,我们使用 GPT-4o 生成的类似指令在一些简短的评估任务中评估了 Jasper。表 2 列出了所有原始和修改后的指令。根据表 3 所示的结果,我们得出结论,我们的 Jasper 模型对指令是鲁棒的,可以准确地理解不同的指令。
Vision Encoding 的可能改进
由于时间和资源限制,我们只能为 Jasper 模型配备基本的图像编码功能。最初,第 4 阶段被设想为基本的视觉语言对齐训练阶段,潜在的第 5 阶段涉及使用视觉问答 (VQA) 数据集的对比学习。此外,我们在第 4 阶段观察到损失函数的振荡行为。总体而言,多模式培训还有相当大的改进空间。
结论
在本文中,我们介绍了 Jasper 模型的基于蒸馏的训练程序。我们设计了三个损失函数,从不同的角度将多个大型教师Embedding模型提炼到一个学生Embedding模型中。随后,我们利用基于 MRL 的训练方法来降低学生模型的向量维数。MTEB 上的实验结果表明,我们的 Jasper 模型在 2B 参数尺度上实现了最先进的性能,并显示出与其他具有 7B 参数的顶级Embedding模型相当的结果。未来的工作将进一步探索多种模式之间的一致性。
[2412.19048] Jasper and Stella: distillation of SOTA embedding models