基于 AI 的人像修复与编辑技术:CompleteMe 系统的研究与应用
概述
加利福尼亚大学默塞德分校与 Adobe 的新合作在人像补全领域取得了突破性进展——人像补全是一项备受关注的任务,旨在“揭示”人像中被遮挡或隐藏的部分,可用于虚拟试穿、动画制作和照片编辑等场景。

除了修复损坏的图像或根据用户意愿更改图像外,人像补全系统(如 CompleteMe)还可以将新服装(通过附加参考图像,如这两个示例中的中间列)引入现有图像。这些示例来自新论文的详细补充 PDF。
这种新方法名为 CompleteMe:基于参考的人像补全,利用辅助输入图像向系统“建议”应用人像中隐藏或缺失部分的内容(因此适用于基于时尚的试穿框架):

CompleteMe 系统可以将参考内容适配到人像的遮挡或隐藏部分。
该系统采用双重 U-Net 架构和一个__区域聚焦注意力__(Region-Focused Attention,RFA)模块,将资源集中到图像修复实例的相关区域。
研究人员还提供了一个新的且具有挑战性的基准系统,用于评估基于参考的补全任务(因为 CompleteMe 是计算机视觉中一个现有的且持续进行的研究方向,尽管直到现在还没有基准方案)。
在测试中以及一个规模良好的用户研究中,新方法在大多数指标上都领先,并且总体上也领先。在某些情况下,其他方法被基于参考的方法完全难住了:

来自补充材料:AnyDoor 方法在解释参考图像方面特别困难。
论文指出:
“在我们的基准上的广泛实验表明,CompleteMe 在定量指标、定性结果和用户研究方面均优于现有的基于参考和非基于参考的最先进方法。”
“特别是在涉及复杂姿势、复杂服装图案和独特配饰的具有挑战性的场景中,我们的模型始终在视觉保真度和语义连贯性方面表现出色。”
遗憾的是,该项目的 GitHub 页面 没有代码,也没有承诺提供任何代码,而且该项目也有一个简陋的 项目页面,似乎被当作一种专有架构。

新系统相对于先前方法的主观性能的进一步示例。稍后在文章中提供更多详细信息。
模型方法
CompleteMe 框架基于一个参考 U-Net,它处理将辅助材料整合到过程中的任务,以及一个整体 U-Net,它容纳更广泛的过程以获得最终结果,如下图的概念架构所示:
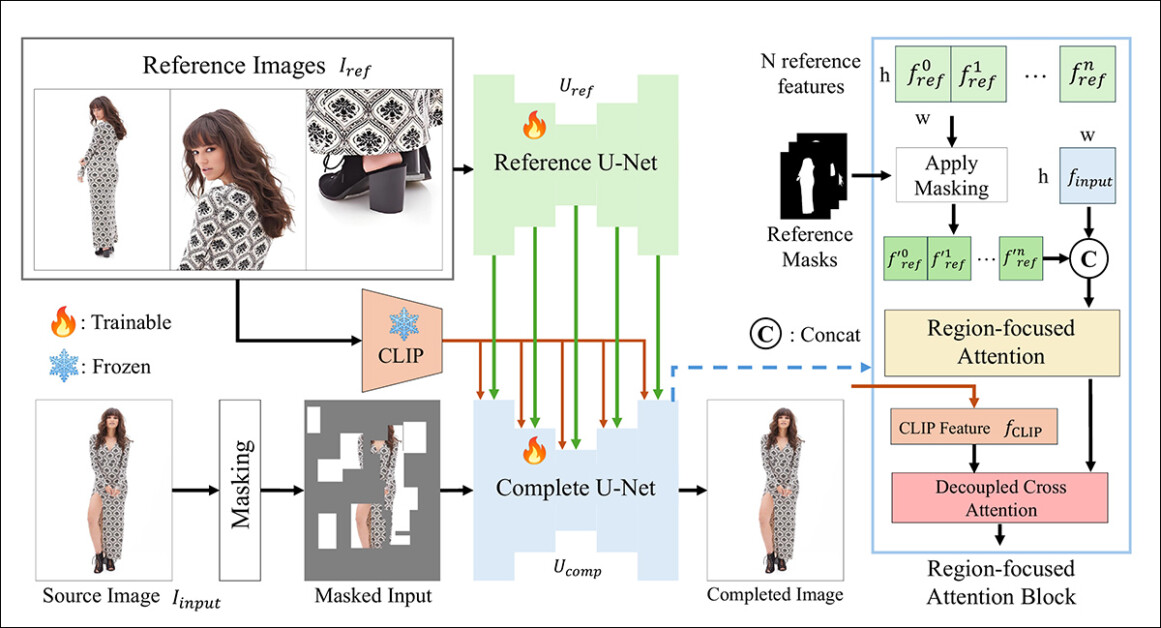
CompleteMe 的概念架构。
该系统首先将遮罩输入图像编码为潜在表示。同时,参考 U-Net 处理多个参考图像——每个图像显示不同的身体部位——以提取详细的空域 特征。
这些特征通过嵌入在“完整”U-Net 中的区域聚焦注意力模块传递,在这里,它们使用对应的区域掩码进行选择性遮罩,确保模型只关注参考图像中的相关区域。
然后,遮罩后的特征与全局 CLIP-派生的语义特征通过解耦的 交叉注意力 进行整合,使模型能够以精细细节和语义连贯性重建缺失内容。
为了增强真实感和鲁棒性,输入遮罩过程结合了随机网格遮罩与人体形状遮罩,每种遮罩以相等的概率应用,增加了模型必须补全的缺失区域的复杂性。
参考方法
先前基于参考的图像修复方法通常依赖于__语义级__编码器。这类项目包括 CLIP 本身和 DINOv2,它们都从参考图像中提取全局特征,但往往丢失了用于准确身份保留所需的精细空间细节。

来自旧的 DINOV2 方法的发布论文,该方法包含在新研究的对比测试中:彩色叠加显示应用于每列图像块的主成分分析(PCA)的前三个主成分,突出显示了 DINOv2 如何将不同图像中相似的物体部分分组在一起。尽管姿势、风格或渲染存在差异,但对应的区域(如翅膀、四肢或轮子)始终匹配,展示了该模型在无监督情况下学习基于部分的结构的能力。 来源:https://arxiv.org/pdf/2304.07193
CompleteMe 通过一个专门的参考 U-Net 解决了这一问题,该 U-Net 从 Stable Diffusion 1.5 初始化,但不执行 扩散噪声步骤。
每个覆盖不同身体部位的参考图像都通过这个 U-Net 编码为详细的潜在特征。同时,使用 CLIP 单独提取全局语义特征,并将这两组特征缓存起来,以便在基于注意力的整合过程中高效使用。因此,该系统可以灵活地容纳多个参考输入,同时保留精细的外观信息。
协调
整体 U-Net 管理补全过程的最后阶段。它改编自 修复变体 的 Stable Diffusion 1.5,其输入包括以潜在形式的遮罩源图像,以及从参考图像中提取的详细空间特征和由 CLIP 编码器提取的全局语义特征。
这些各种输入通过 RFA 模块整合在一起,该模块在引导模型关注参考材料中最重要的区域方面发挥着关键作用。
在进入注意力机制之前,参考特征被明确遮罩以移除不相关区域,然后与源图像的潜在表示连接起来,确保注意力尽可能精确地指向。
为了增强这种整合,CompleteMe 纳入了从 IP-Adapter 框架改编的解耦交叉注意力机制:

IP-Adapter 是过去三年潜在扩散模型架构发展的动荡时期中,最成功且经常被利用的项目之一,部分被纳入 CompleteMe。 来源:https://ip-adapter.github.io/
这使得模型能够通过独立的注意力流处理精细的视觉特征和更广泛的语义上下文,这些流稍后会被合并,从而产生一个连贯的重建,作者认为这既保留了身份,又保留了精细细节。
基准测试
由于缺乏适用于基于参考的人像补全的合适数据集,研究人员提出了自己的数据集。该(未命名的)基准是通过从 Adobe Research 2023 年 UniHuman 项目设计的 WPose 数据集中精心挑选图像对构建的。

Adobe Research 2023 年 UniHuman 项目的姿势示例。
研究人员手动绘制源遮罩以指示修复区域,最终获得了 417 组三元图像,包括源图像、遮罩和参考图像。

最初从参考 WPose 数据集衍生的两组图像,经过新论文的研究人员广泛整理。
作者使用 LLaVA 大型语言模型(LLM)生成描述源图像的文本提示。
使用的指标比通常更广泛;除了常用的 峰值信噪比(PSNR)、结构相似性指数(SSIM)和 学习感知图像块相似性(LPIPS,此处用于评估遮罩区域)外,研究人员还使用了 DINO 进行相似性评分;DreamSim 用于生成结果评估;以及 CLIP。
数据和测试
为了测试这项工作,作者使用了默认的 Stable Diffusion V1.5 模型和 1.5 修复模型。系统的图像编码器使用了 CLIP 视觉模型,以及投影层——小型神经网络,用于调整或对齐 CLIP 输出以匹配模型内部使用的特征维度。
训练在八个 NVIDIA A100† GPU 上进行了 30,000 次迭代,由 均方误差(MSE)损失监督,批量大小为 64,学习率为 2×10-5。在训练过程中,随机丢弃了各种元素,以防止系统在数据上过拟合。
数据集是从 Parts to Whole 数据集修改而来的,该数据集本身基于 DeepFashion-MultiModal 数据集。

来自 Parts to Whole 数据集的示例,用于开发 CompleteMe 的整理数据。
作者指出:
“为了满足我们的要求,我们[重建]了训练对,使用带有多个参考图像的遮挡图像,这些图像捕捉了人类外观的各个方面以及它们的简短文本标签。”
“我们训练数据中的每个样本包括六种外观类型:上身衣物、下身衣物、全身衣物、头发或头饰、面部和鞋子。对于遮罩策略,我们在 50% 的情况下应用 1 到 30 次的 50% 随机网格遮罩,而在另外 50% 的情况下,我们使用人体形状遮罩以增加遮罩复杂性。”
“在构建管道之后,我们获得了 40,000 对图像用于训练。”
测试的先前__非参考__方法包括 大规模遮挡人像图像补全(LOHC)和即插即用图像修复模型 BrushNet;测试的基于参考的模型包括 按示例绘画;AnyDoor;LeftRefill;和 MimicBrush。
作者首先对先前提到的指标进行了定量比较:
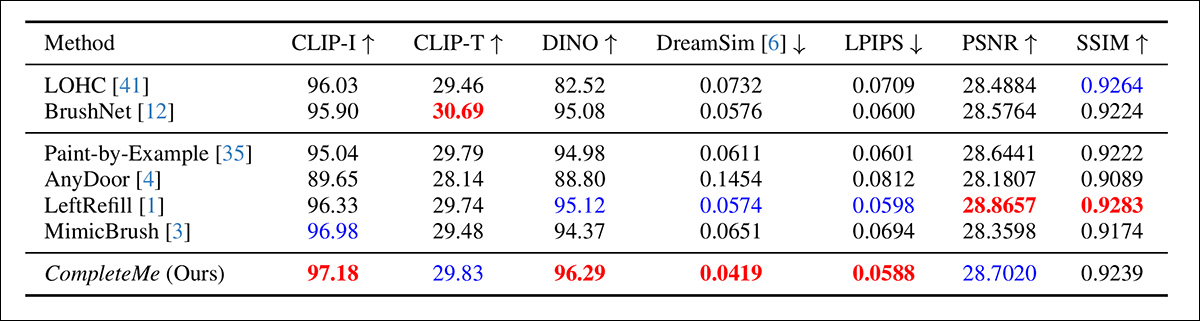
初始定量比较的结果。
关于定量评估,作者指出,CompleteMe 在大多数感知指标上得分最高,包括 CLIP-I、DINO、DreamSim 和 LPIPS,这些指标旨在捕捉输出与参考图像之间的语义对齐和外观保真度。
然而,该模型并非在所有基线上都表现出色。值得注意的是,BrushNet 在 CLIP-T 上得分最高,LeftRefill 在 SSIM 和 PSNR 上领先,MimicBrush 在 CLIP-I 上略微领先。
尽管 CompleteMe 总体上表现出色,但在某些情况下,性能差异较小,某些指标仍由竞争的先前方法领先。或许并非不公平,作者将这些结果视为 CompleteMe 在结构和感知维度上平衡优势的证据。
定性测试的插图数量过多,无法在此处复制,我们建议读者不仅参考原文,还参考前面提到的详细的 补充 PDF,其中包含许多额外的定性示例。
我们突出显示了主论文中呈现的主要定性示例,以及从前面文章中引入的补充图像池中选取的一些额外案例:
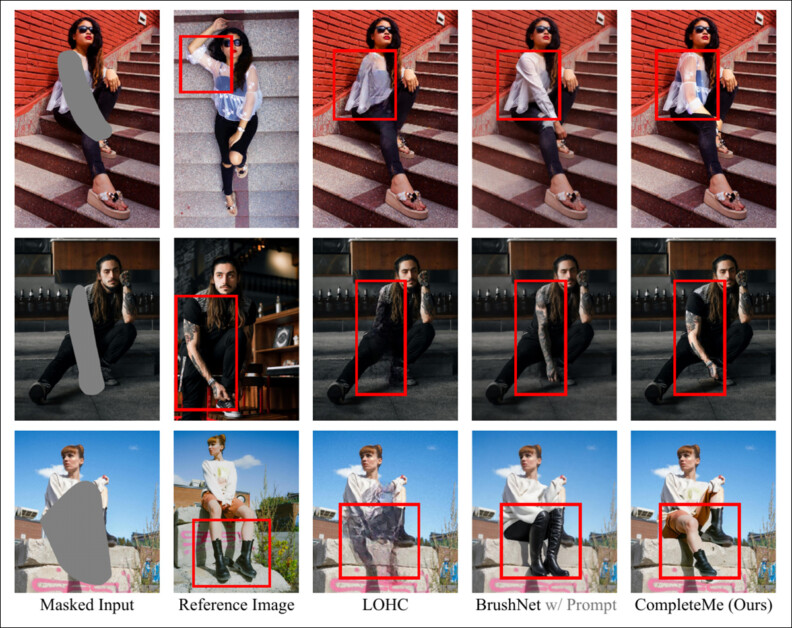
主论文中呈现的初始定性结果。请参考原文以获得更高分辨率的版本。
在上述定性结果中,作者评论道:
“这些非参考方法利用图像先验或文本提示为遮罩区域生成合理的内容。”
“然而,如红色框所示,它们无法重现特定细节,如纹身或独特的服装图案,因为它们缺乏参考图像来指导相同信息的重建。”
第二个比较的一部分如下图所示,重点关注四种基于参考的方法:按示例绘画、AnyDoor、LeftRefill 和 MimicBrush。这里仅提供了一个参考图像和一个文本提示。
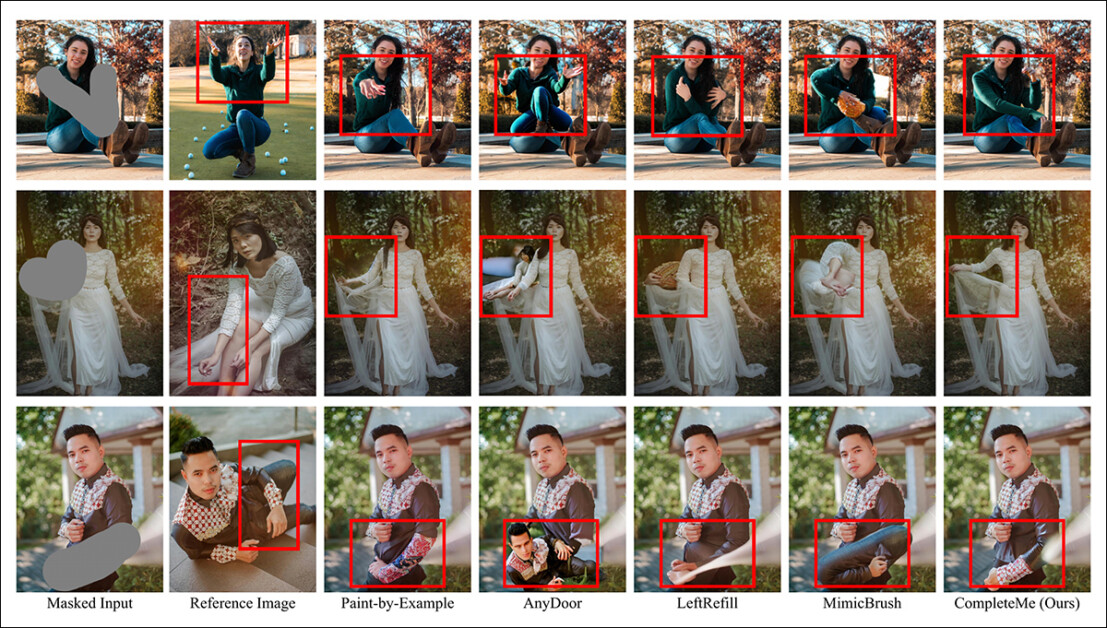
与基于参考的方法的定性比较。CompleteMe 生成更逼真的补全内容,并更好地保留参考图像中的特定细节。红色框突出了特别感兴趣的区域。
作者指出:
“给定一个遮罩的人像和一个参考图像,其他方法可以生成合理的内容,但往往无法准确地保留参考中的上下文信息。”
“在某些情况下,它们会生成不相关的内容或错误地从参考图像中映射对应的部位。相比之下,CompleteMe 通过准确地保留相同信息并正确地从参考图像中映射人体的对应部位,有效地完成了遮罩区域。”
为了评估模型与人类感知的契合度,作者进行了一项用户研究,涉及 15 名标注者和 2,895 对样本。每对样本比较 CompleteMe 的输出与四种基于参考的基线之一:按示例绘画、AnyDoor、LeftRefill 或 MimicBrush。
标注者根据补全区域的视觉质量和保留参考中的身份特征的程度来评估每个结果——在这里,评估整体质量和身份时,CompleteMe 获得了一个更明确的结果:
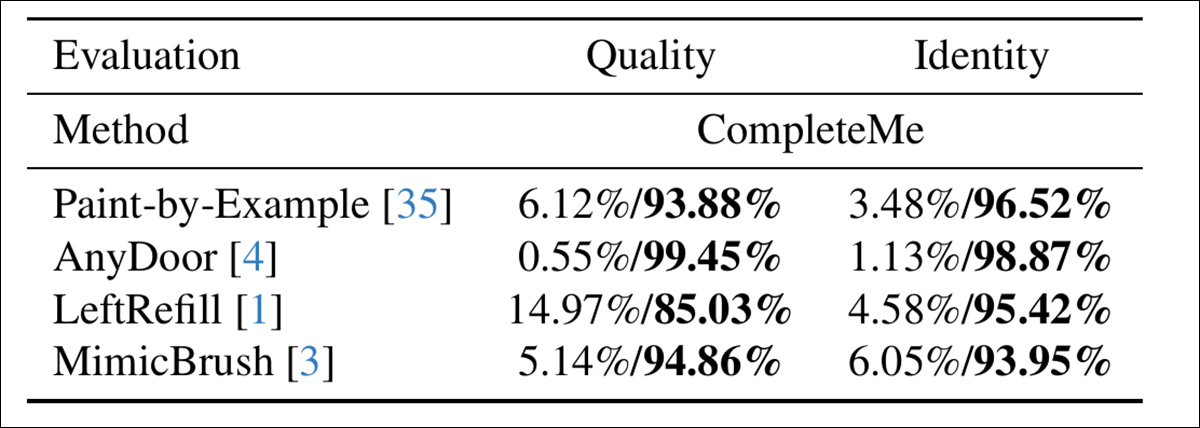
用户研究的结果。
结论
如果有什么不足的话,那就是这项研究中的定性结果数量过多,因为仔细检查表明,这个新系统是在神经图像编辑这一相对较窄但备受关注的领域中一个非常有效的成果。
然而,需要仔细查看并放大原始 PDF,才能欣赏到该系统在比较中如何将参考材料适配到遮挡区域(在几乎所有情况下)优于先前的方法。

我们强烈建议读者仔细检查最初可能令人困惑甚至不知所措的大量结果,这些结果呈现在补充材料中。
有趣的是,现在严重过时的 V1.5 版本仍然是研究人员的最爱——部分原因是出于类似测试的考虑,部分原因是它是所有 Stable Diffusion 迭代中限制最少且可能最容易训练的版本,并且没有 FOSS Flux 发行版的审查限制。
原文地址:https://www.unite.ai/restoring-and-editing-human-images-with-ai/