湖仓一体架构解析:如何平衡数据灵活性与分析性能?
一、什么是湖仓一体架构?解决哪些核心问题?
在数据爆炸的时代,企业面临着如何高效处理和分析海量数据的挑战。传统架构难以同时满足灵活性和性能需求,湖仓一体架构应运而生。
传统数据架构的局限
数据湖(存储各类原始数据的大型存储库)和 数据仓库(存储结构化、经过处理的分析数据的系统)分别存在明显局限:
-
两套系统导致 数据重复存储,增加存储成本并易造成数据不一致
-
数据处理链路长(先入湖,再通过 ETL 入仓), 影响数据实时性
-
两个独立系统间的数据迁移容易出现 一致性问题
-
维护两套技术栈使 架构复杂,开发运维成本高
湖仓一体:融合创新
湖仓一体(Lakehouse)融合了数据湖与数据仓库优势,形成统一的数据处理平台。一言蔽之,湖仓一体将数据仓库的 结构化查询能力和 数据治理功能与数据湖的 灵活存储和 成本优势相结合。
这种架构让企业能够:
-
在同一平台处理所有数据类型
-
无缝调度和管理数据
-
通过统一接口进行访问和分析
典型应用场景
湖仓一体架构特别适合以下场景:
-
实时分析: 对流数据进行近实时处理和分析
-
机器学习应用:为 AI 模型提供多样化数据支持
-
混合负载处理:同时高效处理批处理、流处理和交互式查询
二、湖仓一体架构的关键技术组成
湖仓一体架构由多个关键层次组成,每一层都承担着特定的功能。

1. 统一存储层:灵活与成本平衡
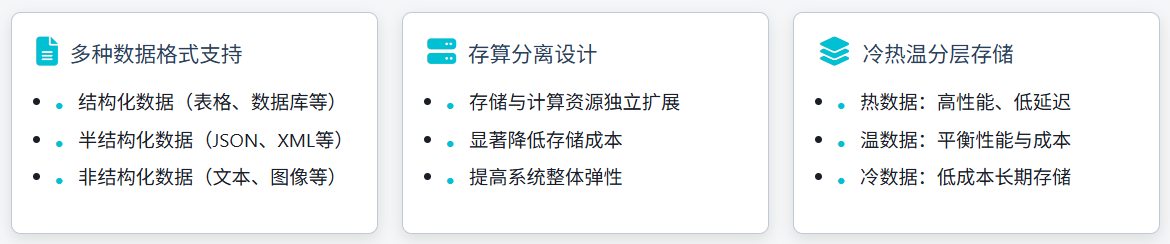
作为架构基础,统一存储层通常基于对象存储或 HDFS 实现,具备:
-
支持多种数据格式(结构化、半结构化、非结构化)
-
采用存算分离设计,大幅降低存储成本
-
实现冷热温分层存储,优化性能与成本平衡
2. 多元计算引擎:按需选择

湖仓一体整合了多种计算引擎,满足不同计算需求:
-
批处理引擎(如 Spark):高效处理大规模历史数据
-
流处理引擎(如 Flink):实时处理数据流
-
交互式查询引擎(如 StarRocks): 支持即席查询
-
AI 计算引擎:支持机器学习工作负载
3. 元数据统一管理:消除数据孤岛

元数据层是避免数据孤岛的核心保障,提供:
-
统一的元数据管理和权限管理
-
自动元数据发现能力,与数据入湖过程联动
-
跨引擎的一致权限控制,简化配置流程
4. 高性能查询解决方案
为了满足高性能查询需求,湖仓一体架构通常会集成 MPP(大规模并行处理)引擎:
-
支持复杂 SQL 查询和高并发访问
-
利用向量化执行引擎加速宽表查询
-
结合列式存储提升分析性能
三、企业如何落地湖仓一体?分阶段实施建议
1. 需求评估:了解你的数据特征
在实施前,全面评估数据特点和业务需求:
思考问题:贵公司的数据处理现状是否面临以下挑战?
-
数据类型多样化,难以统一管理
-
查询性能与数据灵活性难以兼顾
-
实时分析需求日益增长
评估内容:
-
数据类型分布:结构化、半结构化和非结构化数据的比例
-
查询模式:高并发点查询与复杂分析查询的比例
-
业务场景:实时性要求、数据量级和增长趋势
2. 架构设计:平衡兼容性与性能
基于评估结果,进行架构设计:
-
存储选型:优先考虑兼容性,确保与多种计算引擎协同工作
-
计算引擎组合:避免单一技术栈依赖,根据业务场景选择合适组合
-
数据分层规划:设计合理的数据分层策略,平衡性能和成本
3. 技术选型:开源与商业方案
湖仓一体架构可通过多种技术组合实现:
开源方案组合示例:
-
存储层:Apache Iceberg(表格式化存储框架)或 Apache Hudi(流式数据湖平台)+ 对象存储
-
计算层:Spark(批处理)+ Flink(流处理)+ StarRocks(OLAP 查询)
-
元数据层:Hive Metastore 或 Apache Atlas
商业方案选择考量:总体拥有成本(TCO)、运维复杂度、生态兼容性、技术支持服务质量。
四、湖仓一体与传统架构的对比实践
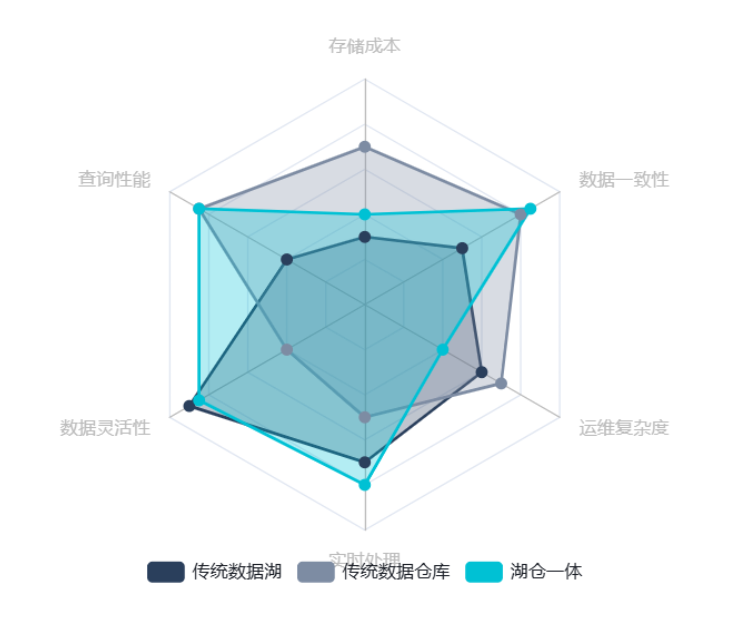
案例一:腾讯音乐——存算分离实现成本与运维优化
1、成本对比
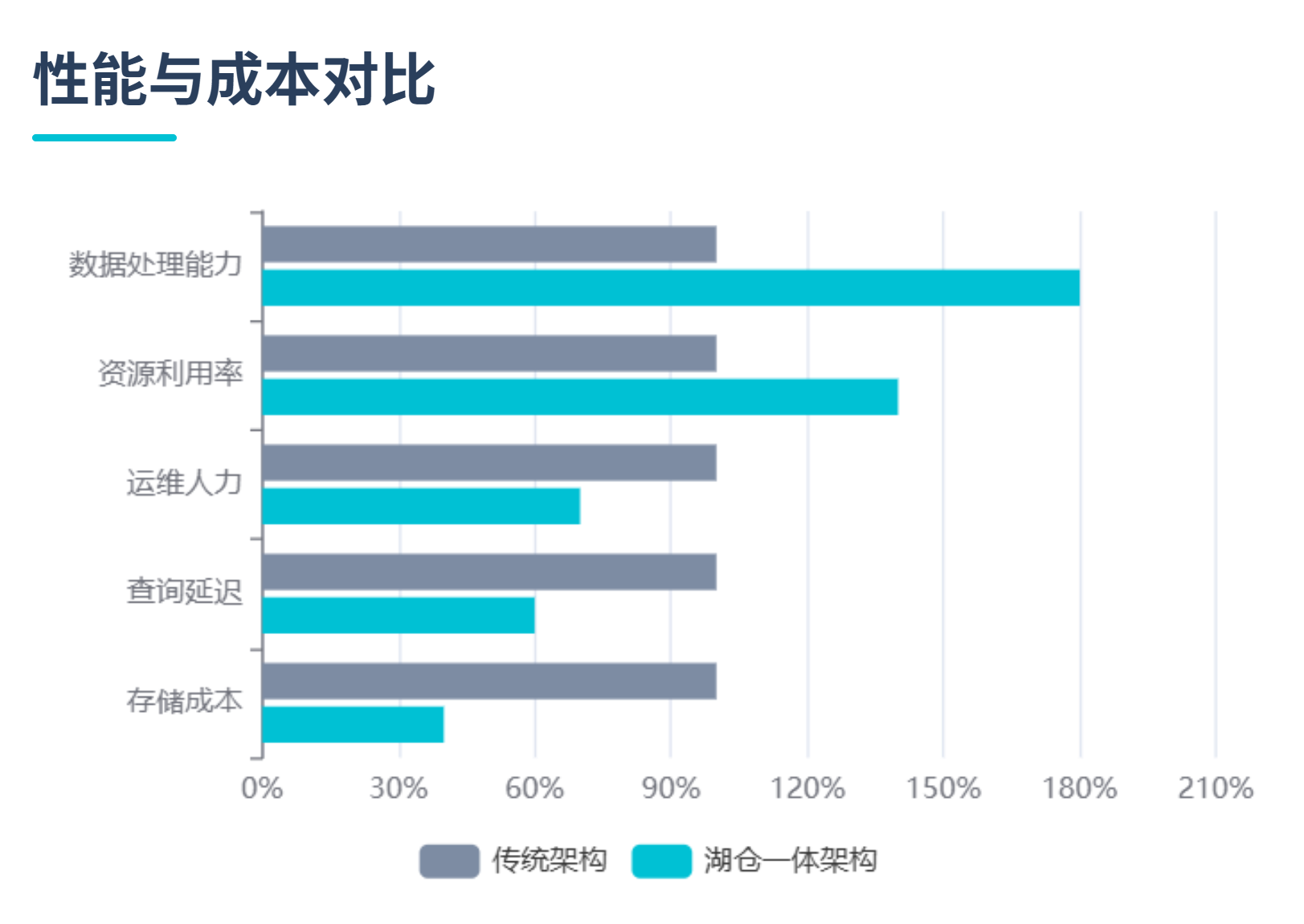
腾讯音乐原有架构使用 ClickHouse 和 Druid 集群,因存算一体需预留冗余资源,成本较高。迁移至 StarRocks 存算分离架构后,存储层采用对象存储(S3/HDFS),计算节点按需弹性扩缩,整体成本下降 50%。
2、性能对比
在保持查询效率不变的前提下,StarRocks 解决了元数据碎片化和数据一致性问题,支持湖上数据直接查询,性能与原有架构持平,但资源利用率显著提升。
3、运维对比
原有架构存在弹性能力弱、分层存储缺失等问题。StarRocks 通过统一元数据目录、动态扩缩容能力,简化了运维流程,同时支持冷热数据分层管理,降低人工干预成本。
案例二:微信——湖仓一体提升数据时效性与性能
1、成本对比
微信原有架构依赖 Hive 和 Spark,存储与计算耦合度高。通过 StarRocks+Iceberg 湖仓一体方案,冷数据存储成本降低 65%,同时减少 ETL 任务资源消耗。
2、性能对比
数据时效性从小时/天级提升至分钟级,80%的大查询通过 StarRocks 实现秒级响应,性能较 Presto 提升 3-6 倍。结合物化视图和 Data Cache,复杂查询效率提升数十倍。
3、运维对比
StarRocks 统一了湖仓元数据管理,支持跨源联邦查询,用户无需区分数据位置。通过异步物化视图自动更新数据,简化了建模链路,数据开发任务数减少 50%。
湖仓一体架构正在与其他数据技术趋势深度融合:
-
湖仓一体与流批一体的协同演进,统一 API 和开发范式,实现大数据的流式计算和批量计算,保证处理过程和结果数据的一致性;
-
AI 与数据平台的深度集成,支持大规模机器学习和深度学习工作负载;
企业在实施湖仓一体架构时,仍面临一些挑战:
-
跨团队协作:需要数据团队、业务团队和 IT 团队的紧密配合;
-
技能升级:需要培养具备湖仓一体架构知识的技术人才;
-
数据治理:需要建立完善的数据治理体系,确保数据质量和安全;
企业可以思考是否已准备好应对这些挑战?现有团队结构和技能是否需要调整?再推进下一步计划。
结语
湖仓一体架构代表了数据处理平台的新方向,它不仅技术上融合了数据湖的灵活性和数据仓库的分析能力,更为企业创造了实际业务价值:降低成本、提升性能、简化管理、加速创新。
随着技术成熟和生态完善,湖仓一体架构将帮助更多企业释放数据价值,支持数据驱动的业务决策,最终提升企业竞争力。
对于正在数字化转型的企业,现在正是评估和规划湖仓一体架构的最佳时机。