【深度学习|学习笔记】深度孪生神经网络Deep Siamese neural network(DSCN)的起源、发展、原理和应用场景(附代码)
【深度学习|学习笔记】深度孪生神经网络Deep Siamese neural network(DSCN)的起源、发展、原理和应用场景(附代码)
【深度学习|学习笔记】深度孪生神经网络Deep Siamese neural network(DSCN)的起源、发展、原理和应用场景(附代码)
文章目录
- 【深度学习|学习笔记】深度孪生神经网络Deep Siamese neural network(DSCN)的起源、发展、原理和应用场景(附代码)
- 前言
- 📜 起源
- 早期应用:签名验证
- 度量学习在视觉领域的引入
- DrLIM:对比损失的理论化
- 💡 原理
- 双分支共享权重
- 对比损失(Contrastive Loss)
- 三元组损失(Triplet Loss)
- 🚀 发展
- 一拍类学习(One-shot Learning)
- 人脸嵌入与验证
- 全卷积目标跟踪(SiamFC)
- 区域提议与强化跟踪
- 🔧 改进
- 在线三元组挖掘
- 注意力和多分支融合
- 轻量化与加速
- 自监督与对比学习
- 🌐 应用
- 🖥️ 代码示例(PyTorch)
- 说明:
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957339
前言
- 在深度学习领域,Siamese 网络通过“孪生”结构和度量学习,开创了基于相似度的模型训练方式,成为从手写签名验证到人脸识别、一拍类学习、目标跟踪等多种任务的重要基石。
- 其核心思想是两条共享参数的神经网络分别提取输入样本特征,再通过对比损失(contrastive loss)或三元组损失(triplet loss)学习一个距离度量,使相似样本在嵌入空间更靠近,不相似样本更远离。
- 早在1993年,它就用于笔迹签名验证;2005年被引入卷积架构;2015年在一拍类图像识别和人脸验证中大放异彩;随后在全卷积目标跟踪、深度度量学习等方向持续演进。
📜 起源
早期应用:签名验证
- 1993年,Bromley 等人提出基于“孪生时延神经网络(Siamese Time Delay Neural
Network)”的签名验证方法,即两条相同子网络分别处理两段签名轨迹,并在顶层计算特征距离以判定真伪。
度量学习在视觉领域的引入
- 2005年,Chopra、Hadsell 和 LeCun 将 Siamese 架构与卷积网络结合,用于人脸验证,提出了对比损失(contrastive loss),并在 AT&T、AR、FERET 等数据集上取得了优异性能。
DrLIM:对比损失的理论化
- 同期,Hadsell 等人在 CVPR 2006 上系统化了对比损失,提出 DrLI(Dimensionality Reduction by Learning an Invariant Mapping),使网络自动学习将相似样本映射到低维流形上的距离度量函数。
💡 原理
双分支共享权重
- Siamese 网络由两条(或多条)相同结构、共享参数的子网络组成,分别提取不同输入样本的高维特征向量,然后通过能量函数(如欧氏距离)评估特征相似度。
对比损失(Contrastive Loss)
- DrLIM 中的对比损失将“相似对”拉近、“不相似对”推远,定义为
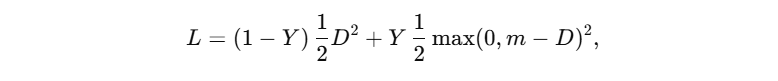
其中 D D D 为两向量欧氏距离, Y ∈ 0 , 1 Y∈{0,1} Y∈0,1 表示标签, m m m 为边界。
三元组损失(Triplet Loss)
- 为进一步提升学习效率,FaceNet 引入三元组损失,利用“锚点—正样本—负样本”三元组,优化
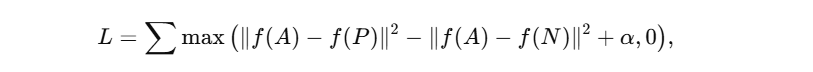
有效保障正负对之间的相对距离。
🚀 发展
一拍类学习(One-shot Learning)
- 2015年,Koch 等人应用 Deep Siamese Networks 实现一拍图像识别,仅需少量样本即可快速泛化,大幅推动小样本学习研究。
人脸嵌入与验证
- 同年,FaceNet 使用深度卷积网络+三元组损失,学习紧凑128维人脸嵌入空间,在 LFW、YouTube Faces 等数据集上刷新记录。
全卷积目标跟踪(SiamFC)
- 2016年,Bertinetto 等人提出 SiamFC,将 Siamese 架构与全卷积网络结合,实现 50–100 FPS
的实时目标跟踪。
区域提议与强化跟踪
- 随后出现 SiamRPN、DaSiamRPN、SiamMask 等系列,结合 RPN、注意力机制,进一步提升跟踪精度和鲁棒性。
🔧 改进
在线三元组挖掘
- FaceNet 基于在线挖掘“半难”负样本,显著加速收敛并避免退化。
注意力和多分支融合
- 在手势识别、医学图像分析等场景,结合注意力模块和多尺度特征融合,提升细节捕捉能力。
轻量化与加速
- 将 MobileNet、ShuffleNet 等轻量主干应用于 Siamese 分支,实现移动端高效部署。
自监督与对比学习
- 近年 SimCLR、MoCo 等框架沿用对比学习范式,借鉴 Siamese 结构进行无监督特征预训练。
🌐 应用
- ✍️ 笔迹/签名验证:基于 Siamese TDNN 的在线签名真伪鉴定。
- 🧑🤝🧑 人脸识别/验证:FaceNet、DeepID 系列,实现大规模人脸认证与聚类。
- 🎯 目标跟踪:SiamFC、SiamRPN、SiamMask 等,实时稳定跟踪移动目标。
- 📷 图像检索:基于学到的相似度,检索最相近的图像集合,应用于电商、内容推荐等领域。
- 🧪 生物医学:细胞/组织样本匹配、异常检测,通过度量学习提升诊断准确率。
- 📊 小样本分类:一拍/零拍学习、嵌入式分类器,快速适应新类别。
🖥️ 代码示例(PyTorch)
下面以 MNIST 手写数字为例,构建一个简易 Siamese 网络并使用对比损失训练:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import random# 1. Siamese 子网络定义
class SiameseBranch(nn.Module):def __init__(self):super().__init__()self.conv = nn.Sequential(nn.Conv2d(1, 16, 3, 1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(16, 32, 3, 1),nn.ReLU(),nn.MaxPool2d(2))self.fc = nn.Sequential(nn.Linear(32*5*5, 128),nn.ReLU())def forward(self, x):x = self.conv(x)x = x.view(x.size(0), -1)return self.fc(x)# 2. Siamese 网络(两分支共享参数)
class SiameseNet(nn.Module):def __init__(self):super().__init__()self.branch = SiameseBranch()def forward(self, x1, x2):f1 = self.branch(x1)f2 = self.branch(x2)return f1, f2# 3. 对比损失
class ContrastiveLoss(nn.Module):def __init__(self, margin=1.0):super().__init__()self.margin = margindef forward(self, f1, f2, label):dist = F.pairwise_distance(f1, f2)loss = (1-label) * dist**2 + label * F.relu(self.margin - dist)**2return loss.mean()# 4. 构造成对数据集
class PairMNIST(Dataset):def __init__(self, train=True):self.data = datasets.MNIST('.', train=train, download=True,transform=transforms.ToTensor())def __len__(self): return len(self.data)def __getitem__(self, idx):img1, label1 = self.data[idx]# 随机选取同/不同类样本same = random.random() < 0.5if same:idx2 = random.choice([i for i,(img,l) in enumerate(self.data) if l==label1])label = 0else:idx2 = random.choice([i for i,(img,l) in enumerate(self.data) if l!=label1])label = 1img2, _ = self.data[idx2]return img1, img2, torch.tensor(label, dtype=torch.float32)# 5. 训练流程
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dataset = PairMNIST(train=True)
loader = DataLoader(dataset, batch_size=128, shuffle=True)
model = SiameseNet().to(device)
criterion = ContrastiveLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)for epoch in range(5):total, running_loss = len(loader), 0.0for x1, x2, lbl in loader:x1,x2,lbl = x1.to(device), x2.to(device), lbl.to(device)f1,f2 = model(x1,x2)loss = criterion(f1,f2,lbl)optimizer.zero_grad(); loss.backward(); optimizer.step()running_loss += loss.item()print(f"Epoch {epoch+1} Loss: {running_loss/total:.4f}")说明:
SiameseBranch:两层卷积+全连接,用于特征提取。SiameseNet:共享同一分支实例,保证参数同步。ContrastiveLoss:对比损失,label=0 表示相似、label=1 表示不相似。PairMNIST:按 50% 概率构造同/异类样本对,用于训练度量模型。