模型部署与提供服务
工具准备
FastApi (提供接口服务)
LLamafactory(模型测试)
AutoDL-SSH(隧道工具)
结构目录
app
├── api.sh
├── lawbot_infer.py
├── main.py
├── models.py
├── prompts
│ ├── chat.jinja2
│ ├── prediction.jinja2
│ └── summarization.jinja2
├── services
│ ├── conversation_manager.py
│ └── prompt_manager.py
└── structure.txt环境介绍
FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 并基于标准的 Python 类型提示。
安装脚本
#!/bin/bash
pip install fastapi
pip install "uvicorn[standard]"LLaMA-Factory项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。
安装脚本
#!/bin/bash
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'
llamafactory-cli --version
执行脚本后如果返回llamafactory-cli的版本号,那么代表校验成功。
注意llamafactory依赖(transformer 4.51.0 peft 0.15.1)
AutoDL SSH隧道穿越工具
 点击自定义服务下载安装包解压即可
点击自定义服务下载安装包解压即可
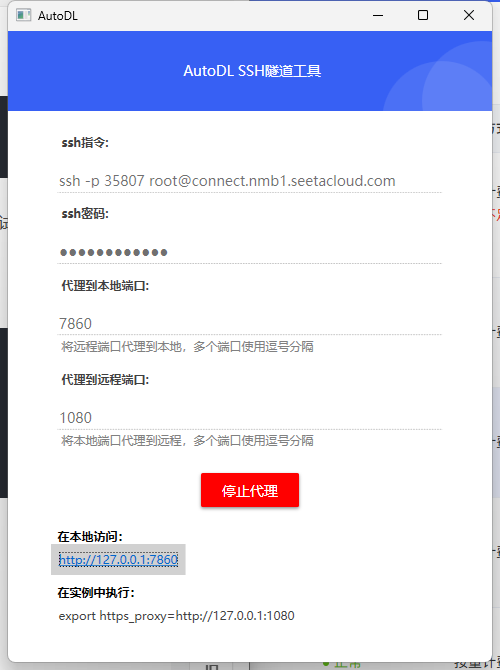
然后在对应页面输入对应的登录指令以及密码和你想要代理的端口。
LLamafactory
LLamafactory主页面
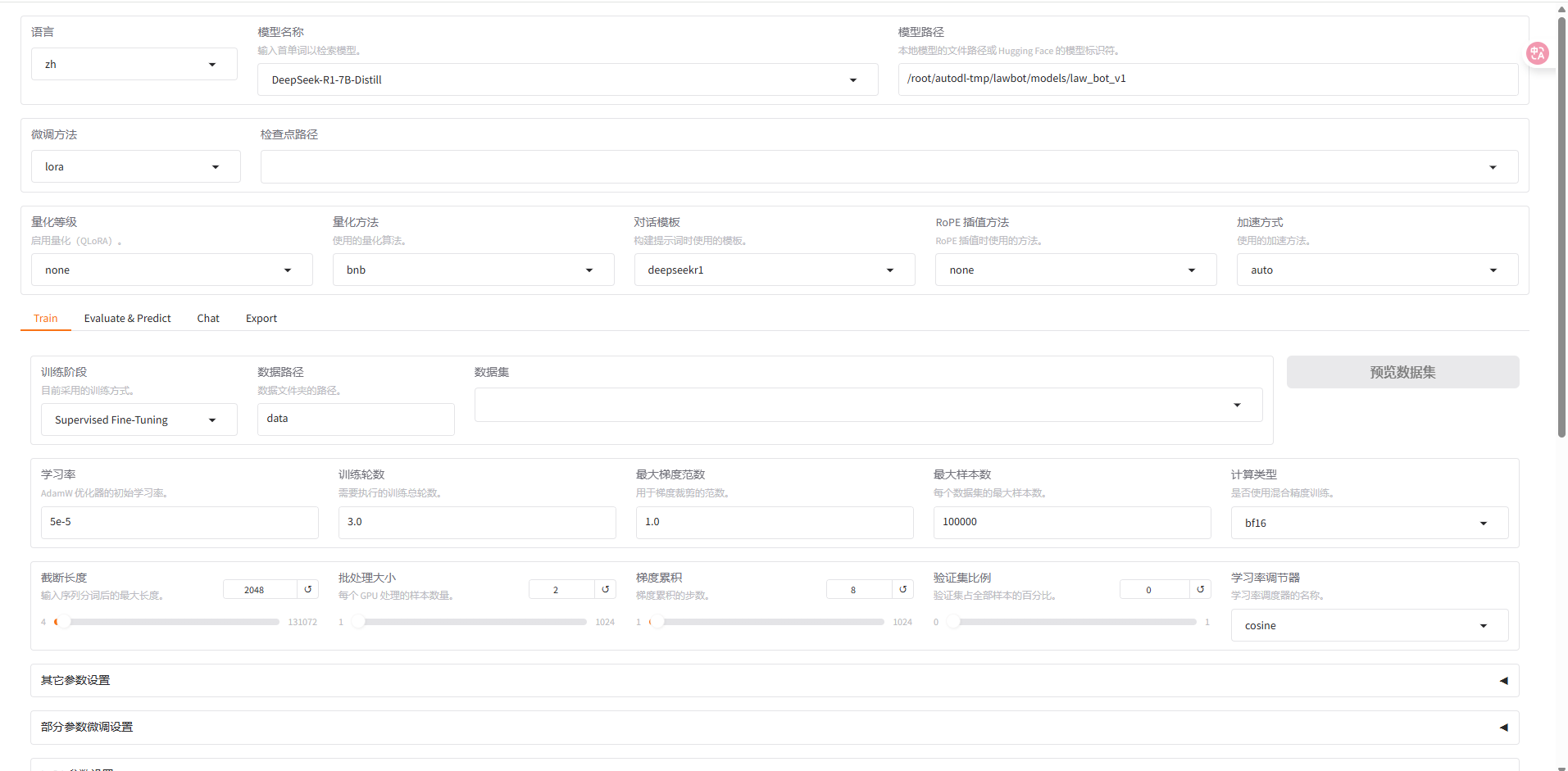
本项目使用脚本训练模型,因此使用llamafactory的主要目的为模型和prompt的测试。
测试模型之前首先要将训练好的模型与lora微调参数进行merge(事实上就是将模型的推理矩阵与lora微调的低秩矩阵合并)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModelbase_model_path = "../models/DeepSeek-R1-Distill-Qwen-7B"
lora_model_path = "../lora/output"
merged_model_path = "../models/lawbot_v1"# 1. 加载原始模型
base_model = AutoModelForCausalLM.from_pretrained(base_model_path,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True
)# 2. 加载 LoRA adapter
model = PeftModel.from_pretrained(base_model, lora_model_path)# 3. 合并权重(此时 LoRA 层会融合到原始模型中)
model = model.merge_and_unload()# 4. 保存合并后的模型
model.save_pretrained(merged_model_path)
tokenizer = AutoTokenizer.from_pretrained(base_model_path, trust_remote_code=True)
tokenizer.save_pretrained(merged_model_path)print("模型合并完成,已保存到:", merged_model_path)
然后将模型路径填入模型路径点击chat即可。
我的模型是通过huggingface-mirror下载的,因此推理引擎使用huggingface而数据类型填写auto,然后点击加载模型。
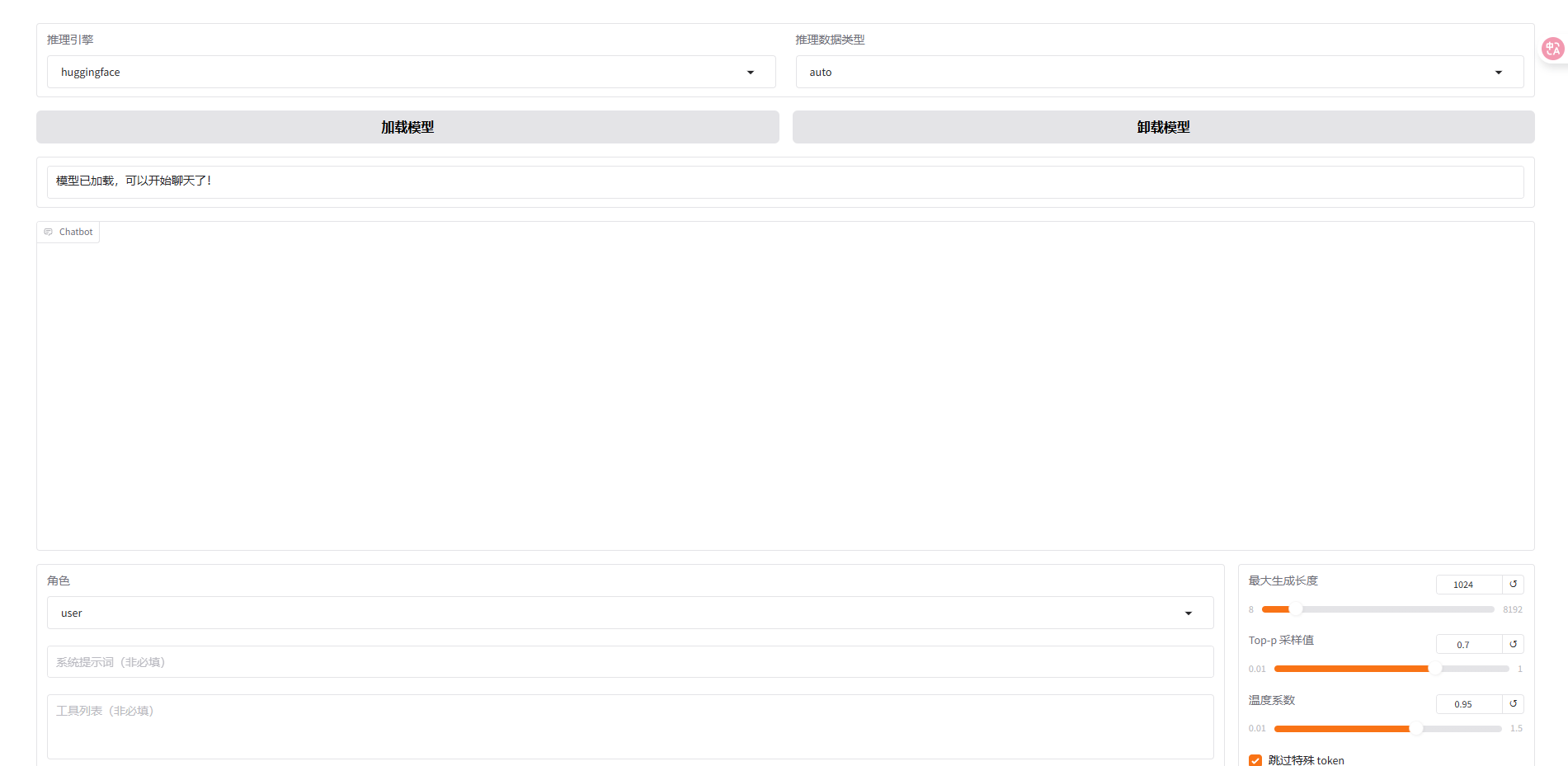
可以将prompt填入系统提示词行然后再输入页面输入即可。
prompt
你是一位专业的法律专家,请根据以下法律文书内容撰写摘要:【摘要要求】
1. 摘要长度约为 {{ length|default(500) }} 字;
2. 准确提取案件的核心事实和关键数据(如时间、地点、当事人、涉案金额、判决结果等);
3. 使用简洁、客观、明了的语言撰写,避免主观评论和冗余;
4. 所有英文内容需翻译成中文;
5. 不得添加未在文书中出现的信息; 【请输出符合以上要求的中文摘要】
内容:
中华人民共和国某某人民法院
刑事判决书
(2025)某某刑初字第001号公诉机关:某某市人民检察院。被告人:张某某,男,1992年3月出生,身份证号码XXXXXXXXXXXXXX,汉族,初中文化,农民,户籍地某某省某某县某某村。因涉嫌盗窃罪于2024年12月5日被某某市公安局刑事拘留,同年12月15日被逮捕,现羁押于某某市看守所。某某市人民检察院以某检刑诉〔2025〕15号起诉书指控被告人张某某犯盗窃罪,于2025年2月28日向本院提起公诉。本院依法适用普通程序,公开开庭审理了本案。某某市人民检察院指派检察员李某出庭支持公诉,被告人张某某到庭参加诉讼。现已审理终结。经审理查明:2024年11月25日凌晨2时许,被告人张某某窜至某某市某某区某小区A栋3单元502室,撬开防盗门进入室内,盗走苹果笔记本电脑1台、iPhone手机1部及现金3000元,共计价值人民币21800元。得手后张某某迅速逃离现场,所盗赃物部分变卖用于个人消费。2024年12月3日,被告人张某某在其租住处被公安机关抓获归案。到案后,张某某如实供述了自己的犯罪事实。上述事实,有下列证据予以证实:被害人王某的报案材料;某某公安局出具的现场勘验笔录、物证照片;鉴定机构出具的财物价值鉴定意见;被告人张某某的供述和辩解;公安机关制作的抓获笔录及相关证人证言等。本院认为,被告人张某某以非法占有为目的,秘密窃取他人财物,数额较大,其行为已构成盗窃罪,依法应予惩处。被告人张某某到案后如实供述犯罪事实,系坦白,可以从轻处罚。综合考虑被告人的犯罪事实、认罪态度、社会危害性及其家庭背景,依法作出如下判决:判决如下:被告人张某某犯盗窃罪,判处有期徒刑一年六个月,并处罚金人民币三千元。对于违法所得依法予以追缴,随案移送扣押。如不服本判决,可在接到判决书之日起十日内,通过本院或者直接向某某市中级人民法院提出上诉。书面上诉的,应当提交上诉状副本一份以上。审判长:李某某
人民陪审员:王某某、赵某某
书记员:陈某某某人民法院
2025年3月5日测试结果
本案涉及被告人张某某因涉嫌盗窃罪被判处有期徒刑一年六个月,并处罚金人民币三千元。案件发生在2024年11月25日凌晨,被告人张某某在某某市某某区某小区A栋3单元502室盗窃苹果笔记本电脑、iPhone手机及现金3000元,共计价值人民币21800元。得手后,张某某迅速逃离现场,部分赃物变卖用于个人消费。2024年12月3日,张某某在其租住处被公安机关抓获归案。经审理,张某某如实供述犯罪事实。法庭认为其行为构成盗窃罪,判处有期徒刑一年六个月,并处罚金人民币三千元。被告人及其家属对判决无异议,案件现已依法审理终结。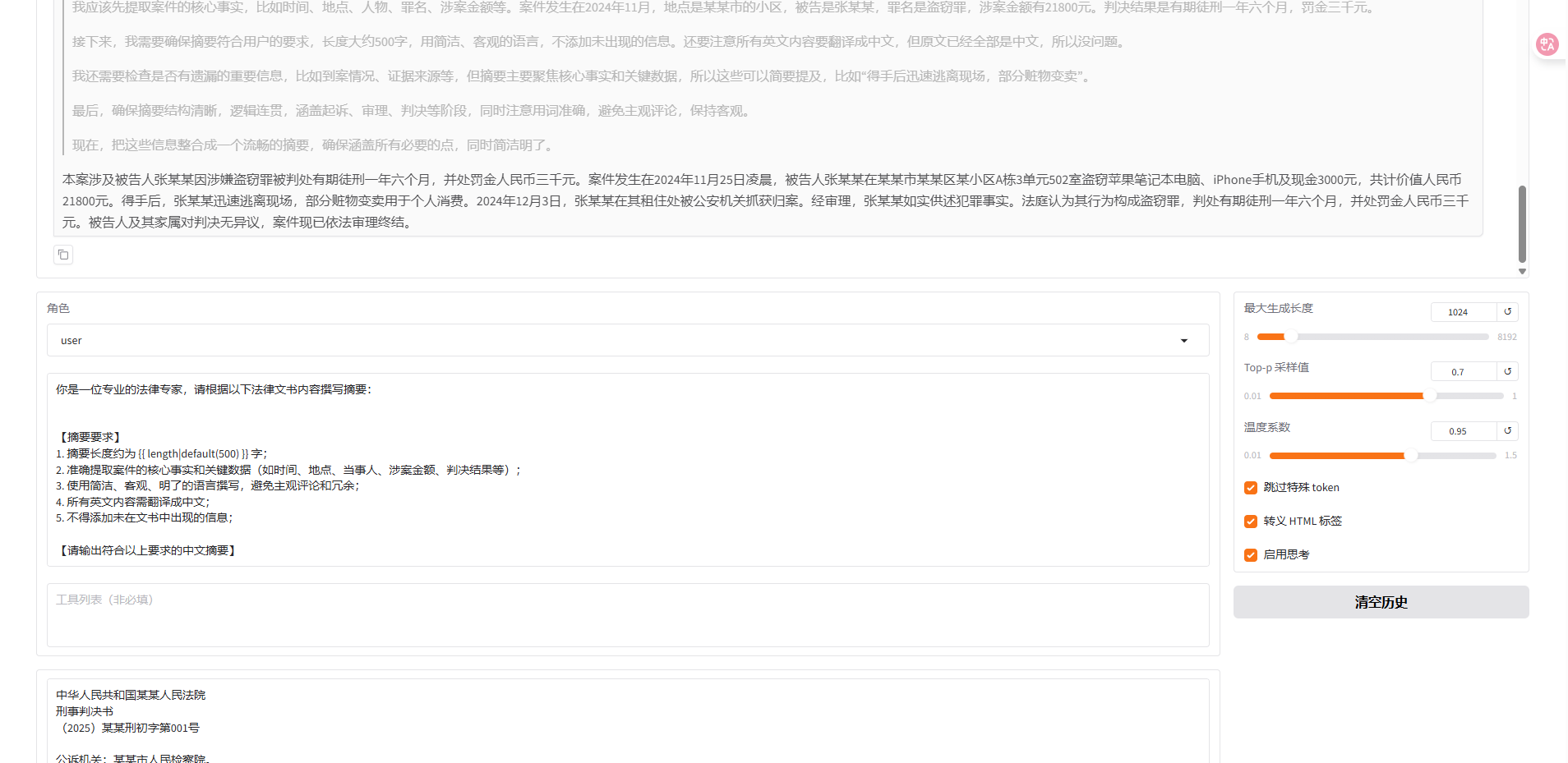
FastApi
FastApi的基础结构
#main.pyfrom fastapi import FastAPI, Request
from pydantic import BaseModel
from fastapi.middleware.cors import CORSMiddlewareapp.add_middleware(CORSMiddleware,allow_origins=["*"], # 可以指定前端地址,或使用 * 表示全部允许allow_credentials=True,allow_methods=["*"], # 允许所有方法allow_headers=["*"], # 允许所有头部字段
)class RequestJson document:str@app.post("/Function")
async def summarize(request: Requestion):text = request.document#编码输入input = tokenizer(...)# 模型思考outputs = model.generate(...)value = tokenizer.decode(outputs[0], skip_special_tokens=True).split("【请输出符合以上要求的中文摘要】:")[-1].strip() return {"key",value}启动脚本
#!/bin/bashuvicorn main:app --host 0.0.0.0 --port 7860 --reload使用脚本后你就再7860端口提供了一个Fuction接口,传入的Json格式为{"document":Json}
由于AutoDL没有提供公网ip就需要使用上面的AutoDL SSH将7860端口映射到本地。成功映射后访问http://127.0.0.1:7860/docs就可以看到你之前提供的api格式。
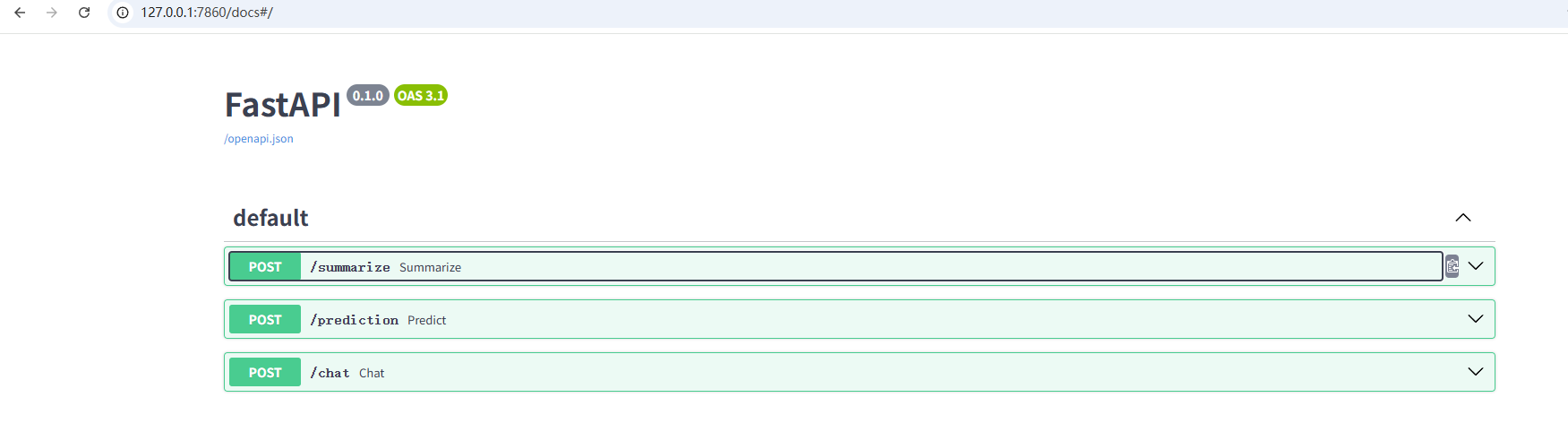
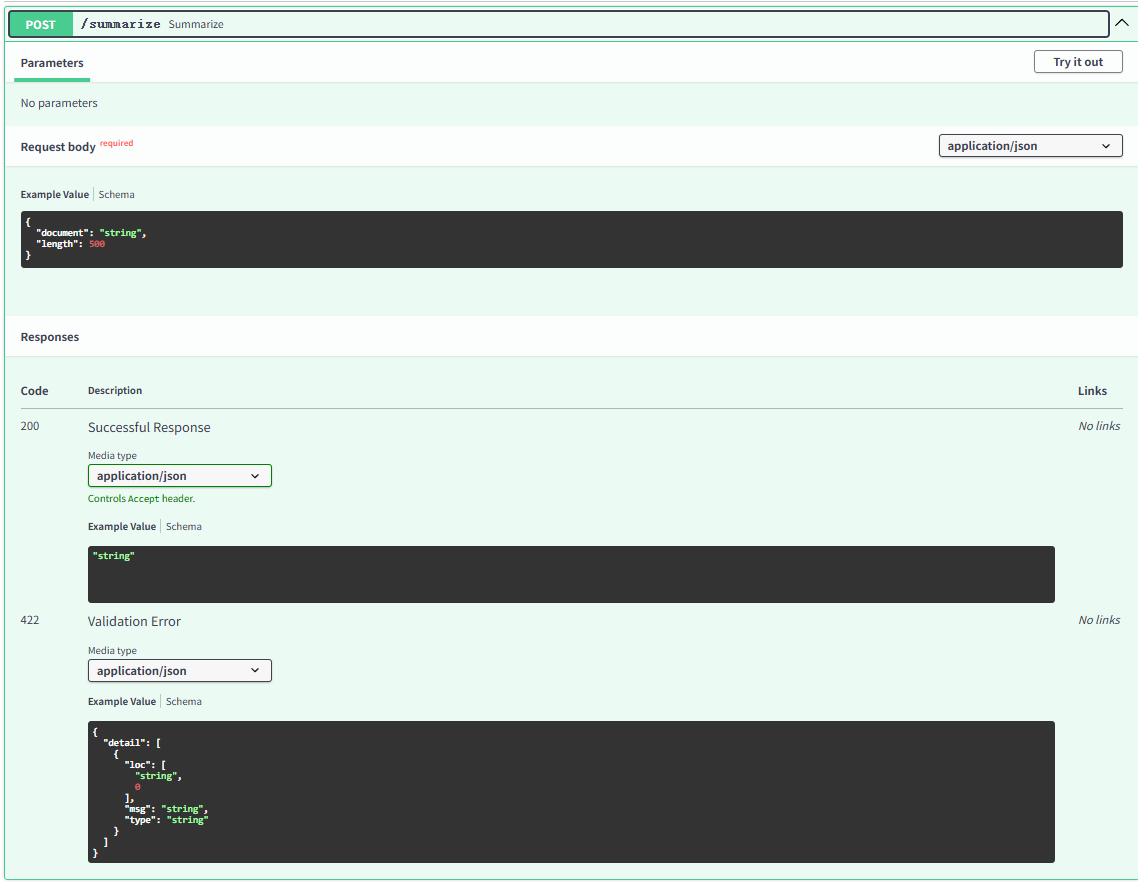
这里围绕功能表述总共开发了三个端口分别对应摘要生成、刑期预测、法律咨询。
model.generation和tokenizer
tokenizer 是 Hugging Face Transformers 中的一个组件,它的作用是把自然语言的字符串转换为模型可处理的 token 序列(数字化表示),并在生成后将 token 还原为可读文本。
inputs = tokenizer(text,return_tensors,truncation,padding,max_length,return_token_type_ids,return_attention_mask,add_special_tokens
)
| 参数名 | 类型 | 说明 |
|---|---|---|
text | str / list | 输入文本(可为字符串或多个字符串列表) |
return_tensors | str | 返回哪种框架的张量:如 'pt'(PyTorch)、'tf'、'np' |
padding | bool / str | 是否 padding:如 'max_length', 'longest' |
truncation | bool / str | 是否截断:如 True,或者 'longest_first' |
max_length | int | 限定最大长度(配合 truncation) |
return_token_type_ids | bool | 是否返回 token_type_ids(用于区分句子对) |
return_attention_mask | bool | 是否返回 attention_mask |
add_special_tokens | bool | 是否添加 BOS/EOS 特殊 token(默认 True) |
text就是提交的文本,这里的提交文本可以是纯文本也可以是经过prompt工程加工后的文本,return_tensors由于我使用的是Pytorch框架,因此填写pt,padding=True如果输入是一个 batch(多个 prompt),则会将短的 prompt 补齐到与最长的对齐,这个参数可避免因不同长度而出错。truncation=True防止输入太长导致模型报错,max_length我在模型中设置的是2048(考虑到法律文书较长),剩余两个参数使用默认设置即可。
model.generation 是 Hugging Face Transformers 中用于 文本生成 的核心方法,通常用于 语言模型 的推理阶段。它会根据你输入,自动生成一段后续文本。
outputs = model.generate(input_ids,max_new_tokens,do_sample,top_k,top_p,temperature,repetition_penalty=,num_beams,eos_token_id=tokenizer.eos_token_id,
)
| 参数名 | 类型 | 说明 |
|---|---|---|
| input_ids | tensor | 输入 token id 序列(模型编码后的输入) |
| max_new_tokens | int | 生成的最大新 token 数(不包括输入的长度) |
| do_sample | bool | 是否使用采样(启用 Top-k, Top-p 和 Temperature) |
| top_k | int | |
| top_p | float | Top-p (nucleus sampling),保留累计概率前 p 的 token 进行采样 |
| temperature | float | 温度参数,控制生成随机性,越小越确定,越大越随机 |
| repetition_penalty | float | |
| num_beams | int | Beam Search 的宽度,>1 启用 Beam Search(提升质量) |
| eos_token_id | int | 结束符的 token id,如果模型没有自动结束需要指定 |
| pad_token_id | int | 用于 padding 的 token id(非必需,但有时会警告 |
| return_dict_in_generate | bool | 是否返回完整的字典结构(含 logit、token 等) |
input_id直接使用tokenizer生成的input即可,max_new_token用于控制生成内容的长度。
top_k:指定了在每个时间步生成时,模型从概率最高的 k 个词汇中进行选择。top_k越大,生成的文本多样性越高,但也可能失去一些连贯性。
top_p:基于累积概率的方式来选择生成词汇。它会动态计算一个词汇集合,这个集合中的所有词汇加起来的概率超过 p,然后从这个集合中选择词汇。较小的 top_p可以有效控制生成的文本质量和多样性,使得文本更连贯且不至于生成一些不常见的词汇。
temperature同样用于控制随机性,repetition_penalty是用来控制是否出现重复内容的(模型调试过程中曾经出现过400多个连续“哈”字,因此我认为这个参数还是很重要的。)
总结:
在模型经过微调之后,我利用llamafactory测试了模型的效果,经过测试之后,利用FastApi提供的框架将其部署在AutoDL的平台上,在7860端口提供chat(法律咨询)、Prediction(刑期预测)、Summrization(摘要生成)三个功能。