具身系列——比较3种vpg算法方式玩CartPole游戏(强化学习)
文档1方式参考:https://gitee.com/chencib/ailib/blob/master/rl/vpg_baseline_cartpole.py
文档2方式参考:https://gitee.com/chencib/ailib/blob/master/rl/vpg_batchupdate_cartpole.py
文档3方式参考:https://gitee.com/chencib/ailib/blob/master/rl/vpg_standard_cartpole.py
三个文档算法的异同分析及可取之处
一、共同点
-
算法基础
均基于策略梯度方法(Policy Gradient),核心是REINFORCE算法或其改进版本,通过优化策略网络直接输出动作概率分布。 -
环境处理
• 均针对CartPole-v1环境,适配不同版本的Gym API(处理terminated和truncated返回值差异)。• 状态和动作空间的定义方式一致(如
env.observation_space.shape[0])。 -
折扣回报计算
均使用折扣因子(Gamma) 对轨迹的未来奖励进行衰减,计算累积回报。 -
框架与优化器
• 使用PyTorch实现神经网络,优化器均为Adam。• 策略网络结构均为全连接网络,输出Softmax动作概率。
二、差异点
| 特征 | 文档1(带基线REINFORCE) | 文档2(批量REINFORCE) | 文档3(标准策略梯度) |
|---|---|---|---|
| 基线网络 | ✅ 使用Critic网络计算基线值,优势值减少方差 | ❌ 无基线,直接使用折扣回报 | ❌ 无基线,但回报标准化(减均值/标准差) |
| 更新方式 | 单episode更新(蒙特卡洛) | 批量更新(收集多episode后更新) | 单episode更新,结合滑动平均奖励监控 |
| 网络结构 | 简单网络(128隐藏层) | 深层网络(4层ReLU) | 中等网络(30隐藏层,tanh激活) |
| 回报处理 | 优势值 = 回报 - 基线值 | 折扣回报标准化(减均值) | 折扣回报标准化(减均值/标准差) |
| 兼容性处理 | 动态修补NumPy兼容旧版Gym | 适配不同Gym版本step返回值 | 适配新版Gym的reset/step返回值 |
| 额外功能 | 动态渲染测试 | 训练/测试结果可视化 | 模型保存/加载、训练时动态开启渲染 |
三、各自的可取之处
1. 文档1:带基线的REINFORCE
• 优势值计算
引入Critic网络预测状态价值作为基线,通过优势值=回报-基线减少策略更新的方差,显著提升训练效率。
• 网络分离设计
策略网络(Actor)和基线网络(Critic)分离,结构清晰,便于单独优化。
• 兼容性修复
动态修补np.bool8兼容旧版Gym,避免AttributeError。
2. 文档2:批量更新的REINFORCE
• 批量训练机制
收集多个episode的轨迹后统一更新参数,提升硬件利用率,适合复杂环境。
• 深度网络结构
使用4层ReLU网络,增强状态表征能力,适合高维状态空间。
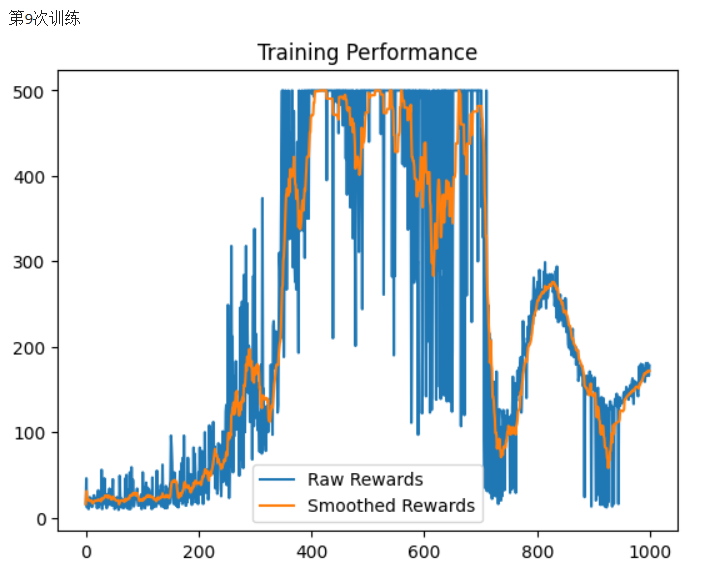
• 完整可视化
绘制训练/测试奖励曲线,直观展示算法性能,便于调试和分析。
3. 文档3:标准策略梯度
• 回报标准化
对折扣回报进行均值中心化和标准差缩放,避免梯度爆炸/消失,提升稳定性。
• 实用功能完善
支持模型保存/加载、训练时动态渲染控制,适合实际部署和演示。
• 权重初始化
对网络参数显式初始化(正态分布+偏置),加速收敛。
四、总结与建议
• 选择建议
• 需快速收敛:选文档1(带基线)+ 文档3(回报标准化)。
• 需处理复杂状态:选文档2(深层网络)+ 文档1(基线)。
• 需部署和稳定性:选文档3(模型保存+标准化)。
• 改进方向
结合三者的优点:带基线的网络 + 批量更新 + 回报标准化 + 可视化与模型保存。
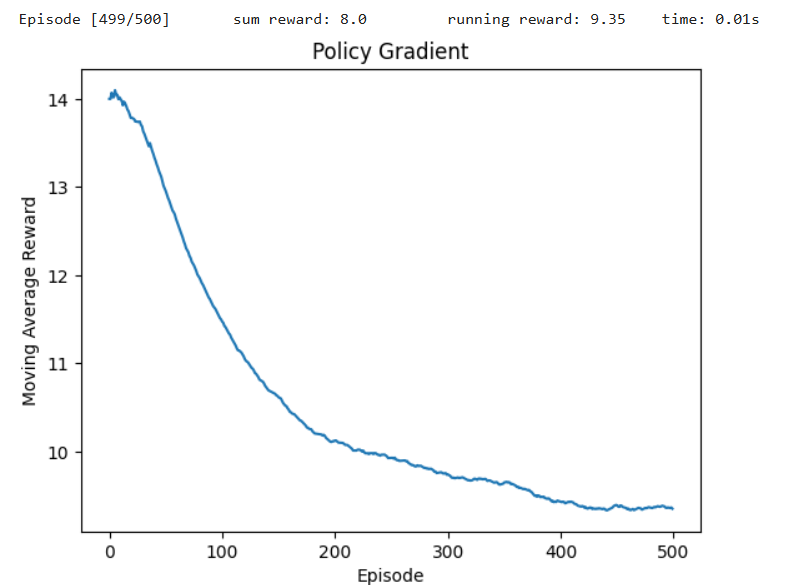
附文档1算法执行:
Episode 0, Total Reward: 37.0
Episode 50, Total Reward: 31.0
Episode 100, Total Reward: 29.0
Episode 150, Total Reward: 28.0
Episode 200, Total Reward: 26.0
Episode 250, Total Reward: 70.0
Episode 300, Total Reward: 218.0
Episode 350, Total Reward: 346.0
Episode 400, Total Reward: 202.0
Episode 450, Total Reward: 500.0
附文档2算法执行:
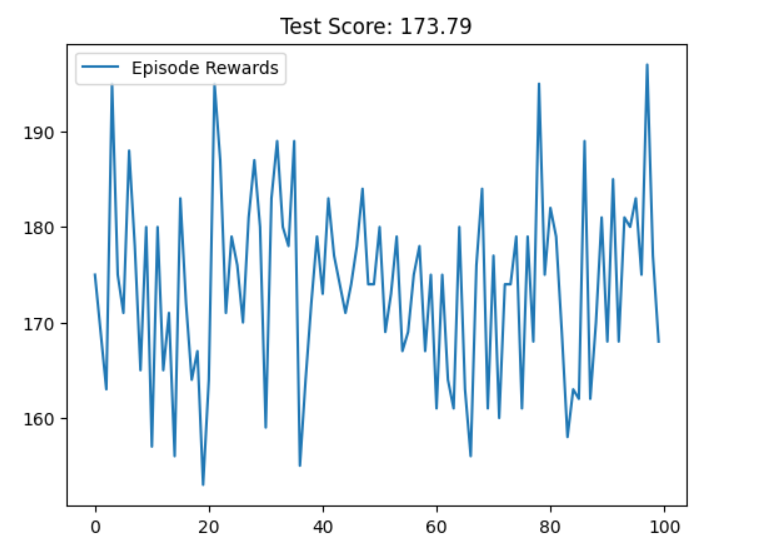
附文档3算法执行: