Prompt compress 技术探究-LLMLingua
Prompt summary:是通过精心设计的提示词(prompt)引导大型语言模型(如 GPT-4)生成特定风格或结构的摘要。其目标不仅是压缩信息,还包括满足特定的格式要求、风格偏好或任务需求,所以和一般的文本摘要还是有些差异的。下面展示了prompt compress技术路线分类总结图。
1. 基于信息熵压缩的 LLMLingua
1.1 摘要
这里以微软的一篇发表在2023 EMNLP 顶级期刊研究论文,介绍下prompt compress技术。LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models https://arxiv.org/pdf/2310.05736。
就信息熵角度来说,困惑度 (PPL) 较低的标记对语言模型的整体熵增益贡献较小,删除困惑度较低的词条,对LLM理解上下文的影响相对较小, 基于这个理论指导,这篇论文进行了尝试。
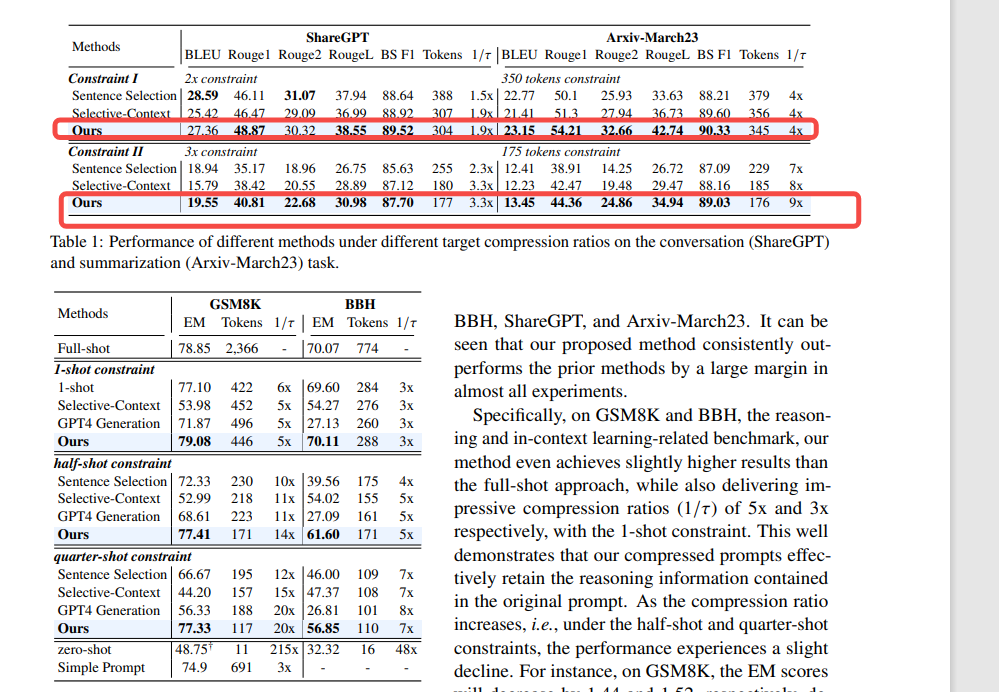
大型语言模型 (LLM) 因其强大的性能而被广泛应用于各种领域。随着思路链 (CoT) 提示和语境学习 (ICL) 等技术的进步,输入到 LLM 的提示越来越长,甚至超过数万个 token。为了加速模型推理并降低成本,本文提出了一种由粗到精的提示压缩方法 LLMLingua,该方法包含一个预算控制器以在高压缩率下保持语义完整性,一个 token 级迭代压缩算法以更好地模拟压缩内容之间的相互依赖关系,以及一种基于指令调优的语言模型间分布对齐方法。我们在四个不同场景的数据集上进行了实验和分析,分别是 GSM8K、BBH、ShareGPT 和 Arxiv-March23;结果表明,所提出的方法达到了最先进的性能,并且允许高达 20 倍的压缩,而性能损失却很小。
1.2 实现步骤
先看下论文的框架图:
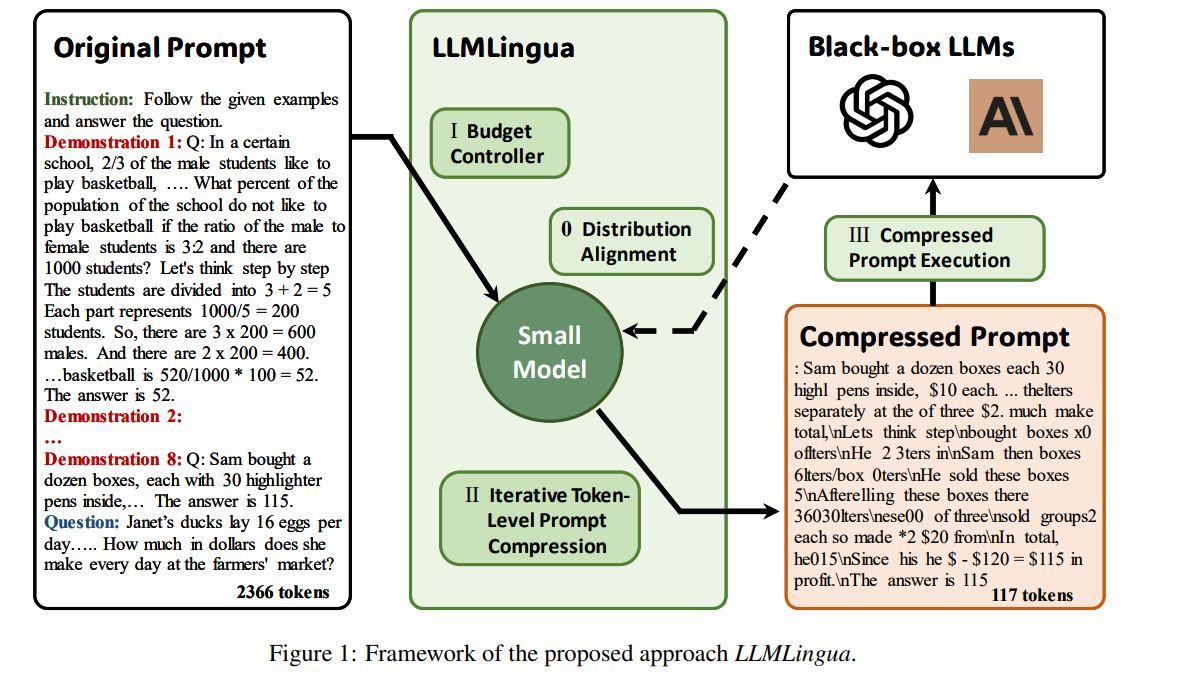
要点总结:
-
为了保证小模型和大模型的数据分布尽可能的一致,使用大模型的输出指令对小模型(gpt2, llma)进行微调。
-
原始的prompt 通常包含三个部分,一个是指令,一个示例,一个问题,那么根据三部分,我们知道,指令和问题,对于llm回答正确的问题是更加的重要的,demonstration 显然没有那么的重要,所以基于此,设计了budget controller, 这个的作用就是在对是三个部分设置不同的压缩比例。
-
针对一个prompt,首先输入小模型,然后对小模型输出的demonstration进行困惑度计算,并按照从高到低进行排序,根据设定的压缩长度的阈值计算公式,选择出来满足这个要求的demonstration, 进行保留,不满足的demonstration进行舍弃。
-
将选择出来的demonstration和之前prompt 中的instruction, question 再组合起来,将这个文本分割成几个文本块,然后对每一个文本块逐个字进行判断是不是大于某个困惑度阈值,然后选择出大于的token作为最终的输出。