InnoDB索引的原理
在鹅厂后端开发一面,我遇到了如题这样一个比较宽泛的问题,当时可能只是背了相关概念,对于索引的了解不是很深刻。
最近,我花了很大的功夫去深入了解MySQL的索引。
下面是我的一些思考:
索引,对于InnoDB来说,索引通常是指一棵B+树(聚簇索引或二级索引)。
- 对于聚簇索引来说,只是叶子节点存放的列包括主键和其他列,索引存放的是每个页中最小主键值和页号
- 对于非聚簇索引来说,叶子节点存放的是 索引列 和主键值,非叶子节点存放的是最小主键值和页号+ 索引列的值(保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的)
原因是:InnoDB的B+树索引是有序的。对于复合索引(比如索引列a,b),如果有多条记录a,b值相同,InnoDB需要依靠主键值来唯一定位和排序。下面举一个具体的例子说明:
假设 数据库建表语句如下:
mysql> CREATE TABLE index_demo(-> c1 INT,-> c2 INT,-> c3 CHAR(1),-> PRIMARY KEY(c1)-> INDEX idx_c2 (c2)-> ) ROW_FORMAT = Compact;
主键是C1, 二级索引C2,假设表中的数据是
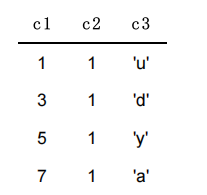
如果二级索引中目录项记录的内容只是 索引列 + 页号 的搭配的话,那么为 c2 列建立索引后的 B+ 树应该长这样
如果我们想新插入一行记录,其中 c1 、 c2 、 c3 的值分别是: 9 、 1 、 ‘c’ ,那么在修改这个为 c2 列建立的二级索引对应的 B+ 树时便碰到了个大问题:由于 页3 中存储的目录项记录是由 c2列 + 页号 的值构成的,页3 中的两条目录项记录对应的 c2 列的值都是 1 ,而我们新插入的这条记录的 c2 列的值也是 1 ,那我们这条新插入的记录到底应该放到 页4 中,还是应该放到 页5 中啊?答案是:无法判断。
为了让新插入记录能找到自己在那个页里,我们需要保证在B+树的同一层内节点的目录项记录除 页号 这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
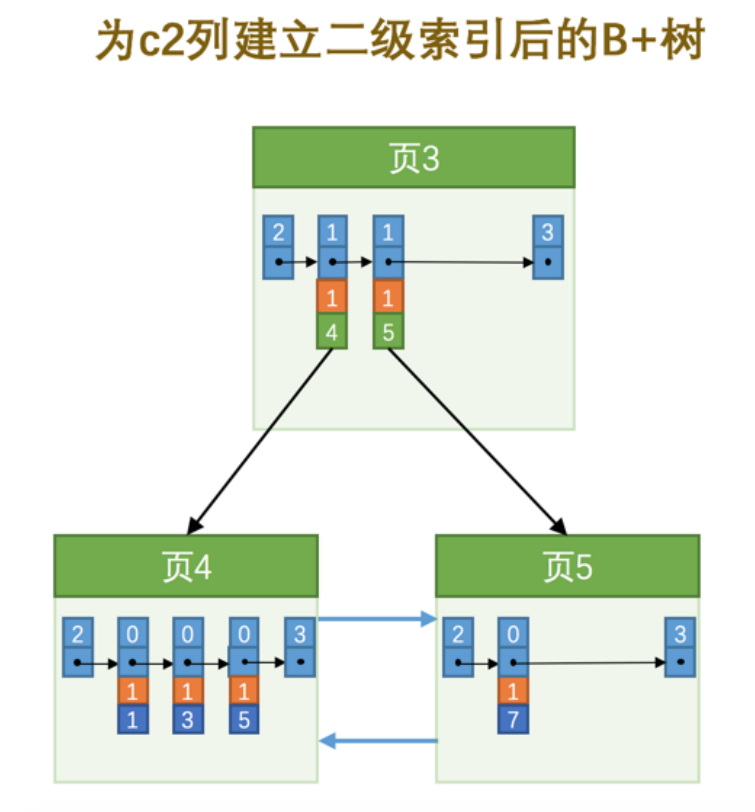
也就是我们把 主键值 也添加到二级索引内节点中的目录项记录了,这样就能保证 B+ 树每一层节点中各条目录项记录除 页号 这个字段外是唯一的,所以我们为 c2 列建立二级索引后的示意图实际上应该是这样子的
这样我们再插入记录 (9, 1, ‘c’) 时,由于 页3 中存储的目录项记录是由 c2列 + 主键 + 页号 的值构成的,可
以先把新记录的 c2 列的值和 页3 中各目录项记录的 c2 列的值作比较,如果 c2 列的值相同的话,可以接着比较
主键值,因为 B+ 树同一层中不同目录项记录的 c2列 + 主键 的值肯定是不一样的,所以最后肯定能定位唯一的
一条目录项记录,在本例中最后确定新记录应该被插入到 页5 中。
索引同层的非叶子结点间,是否也用双线链表维系呢?
是的,如果询问AI 大模型,大部分都是回答没有,这显然是错误的,为此我查阅了相关Mysql 源码的实现storage/innobase/include/fil0fil.h 的第461 行
#define FIL_PAGE_PREV 8 /*!< 如果页面存在一个“自然”的前驱页面,则记录其偏移量。否则,该字段为FIL_NULL。对于BLOB页面,此字段未设置,因为BLOB页面是以单链表形式存储的。另请参见FIL_PAGE_NEXT。 */#define FIL_PAGE_NEXT 12 /*!< 如果存在页面的“自然”后继节点,则记录其偏移量。否则为FIL_NULL。相同PAGE_LEVEL的B树索引页(FIL_PAGE_TYPE包含FIL_PAGE_INDEX)通过FIL_PAGE_PREV和FIL_PAGE_NEXT按照每页上最小用户记录的排序顺序维护为双向链表。 */
相同PAGE_LEVEL的B树索引页,(FIL_PAGE_TYPE包含FIL_PAGE_INDEX),通过FIL_PAGE_PREV和FIL_PAGE_NEXT,按照每页上最小用户记录的排序顺序,维护为双向链表。
非叶子结点各层的双向链表,连起来起了什么作用呢?
深入了解 源码后,在storage/innobase/btr/btr0btr.cc 中找到了相关的代码实现
- 支持范围扫描操作
// 在进行范围扫描时会使用这些链接:
if (left_page_no != FIL_NULL) {prev_block = btr_block_get(page_id_t(space, left_page_no), block->page.size,RW_X_LATCH, index, mtr);
}if (next_page_no != FIL_NULL) {next_block = btr_block_get(page_id_t(space, next_page_no), block->page.size,RW_X_LATCH, index, mtr);
}
- 维护B树结构的完整性
// 在页面分裂时需要维护这些链接关系:
btr_page_set_next(lower_page, lower_page_zip, upper_page_no, mtr);
btr_page_set_prev(upper_page, upper_page_zip, lower_page_no, mtr);if (direction != FSP_DOWN) {btr_page_set_next(upper_page, upper_page_zip, next_page_no, mtr);
}
- 优化查询性能
// 在查询时可以快速定位到相邻页面:
static
void
btr_cur_prefetch_siblings(buf_block_t* block)
{page_t* page = buf_block_get_frame(block);ulint left_page_no = fil_page_get_prev(page);ulint right_page_no = fil_page_get_next(page);// 预读相邻页面以提高性能if (left_page_no != FIL_NULL) {buf_read_page_background(...);}if (right_page_no != FIL_NULL) {buf_read_page_background(...);}
}
- 支持页面合并操作
// 在删除操作导致页面需要合并时:
void
btr_discard_page(btr_cur_t* cursor,mtr_t* mtr)
{// 获取相邻页面号left_page_no = btr_page_get_prev(buf_block_get_frame(block), mtr);right_page_no = btr_page_get_next(buf_block_get_frame(block), mtr);if (left_page_no != FIL_NULL) {// 与左侧页面合并merge_block = btr_block_get(...);}
}
- 数据一致性检查
// 在验证索引时会检查相邻页面的记录顺序:
if (!dict_index_is_spatial(index)&& cmp_rec_rec(rec, right_rec,offsets, offsets2, index, false) >= 0) {// 如果相邻页面的记录顺序不正确,报错btr_validate_report2(index, level, block, right_block);
}
每个页对应一个目录项,每个目录项包括下边两个部分:
聚簇索引
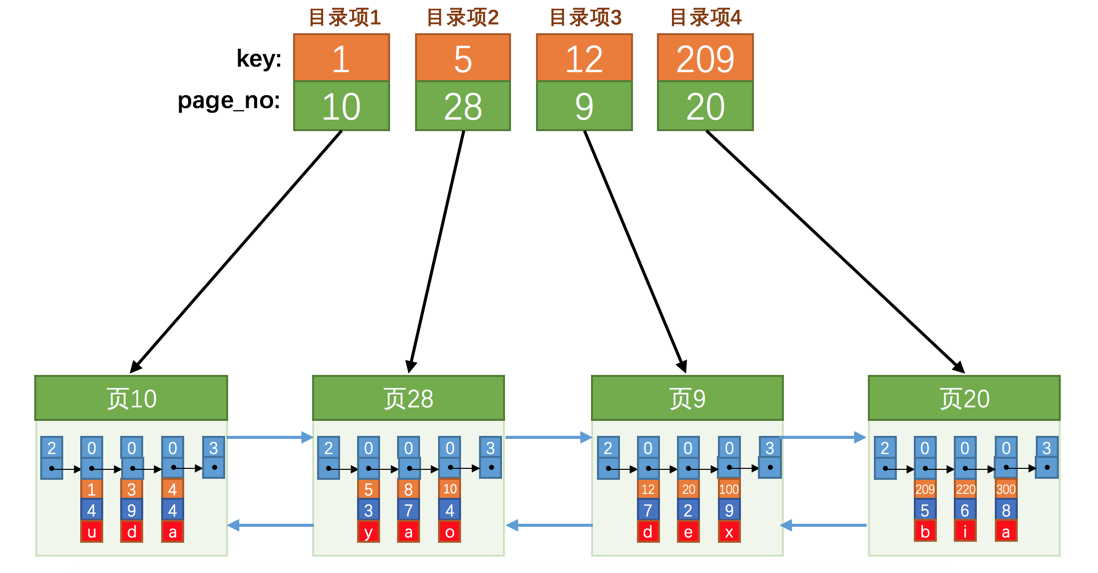
- 页的用户记录中最小的主键值,我们用 key 来表示。
- 页号,我们用page_no 表示。
聚簇索引是一种特殊的B+ 树
满足以下 两个特点:
- 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义
- 页内的记录是按照主键的大小顺序排成一个单向链表。
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
- B+ 树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)
之前我们说过索引的构造和用户记录页 很相似,那么InnoDB 怎么区分一条记录是普通的用户记录还是目录项记录呢?别忘了记录头信息里的record_type 属性,它的各个取值代表的意思如下:
- 0 :普通的用户记录
- 1 :目录项记录
- 2 :最小记录
- 3 :最大记录
参考:《从根上理解MySQL》