走进AI的奇妙世界:探索历史、革命与未来机遇
2022年11月30日,ChatGPT的横空出世像一枚深水炸弹,掀起了全球范围的AI狂潮。但这场革命并非偶然——它背后是80年AI发展史的厚积薄发。从图灵的哲学思辨到深度学习的技术突破,再到生成式AI的“涌现”时刻,AI正以惊人的速度模糊人机边界。本文将带你穿越AI的过去、现在与未来,并拆解这场技术革命背后的产业链机遇。
一、AI的起源与发展史
1.1 萌芽期:神经元模型与图灵测试
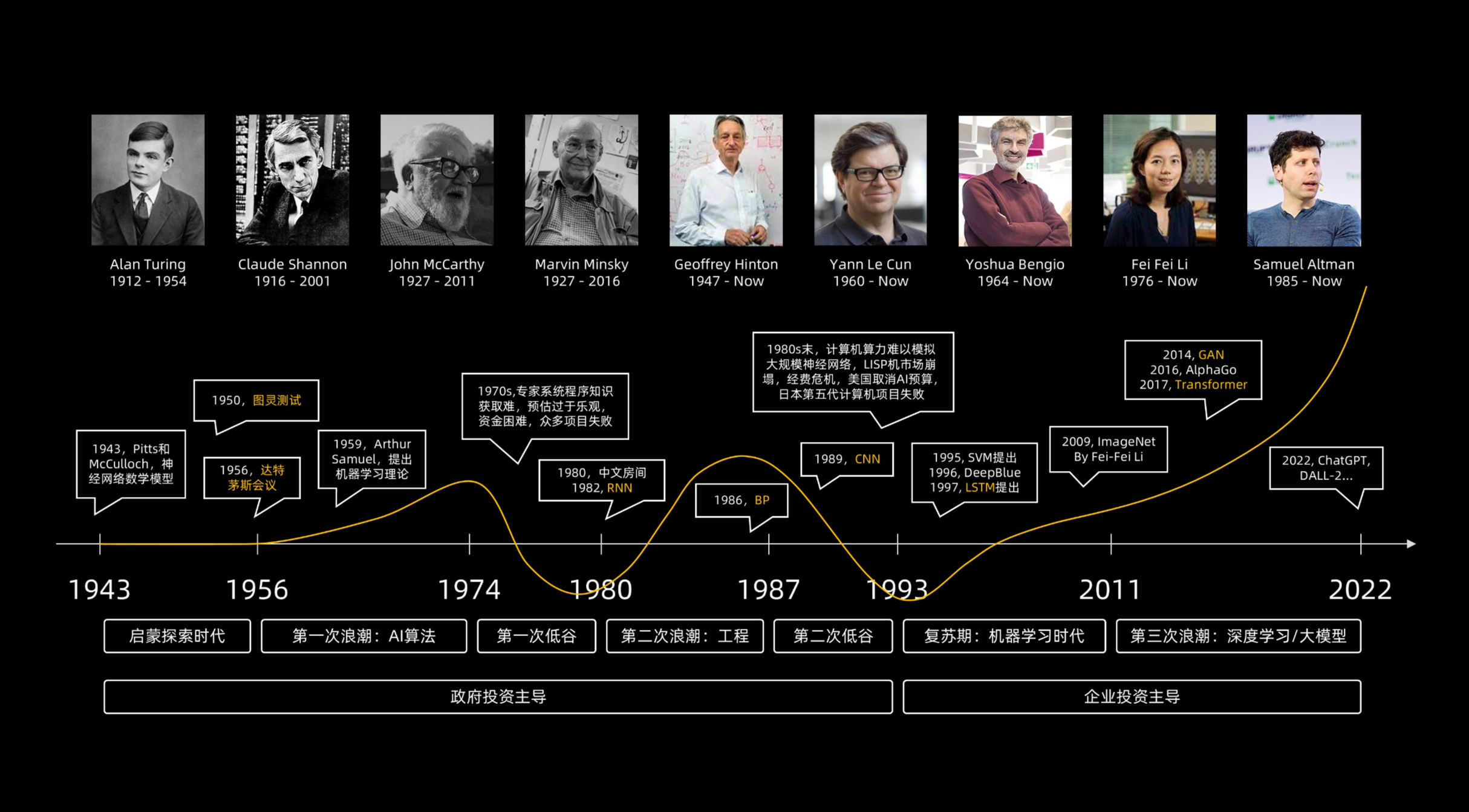
故事要从1943年说起,心理学家麦卡洛克和数学家皮特斯提出了机器的神经元模型,为后来的神经网络研究奠定了基础。这一模型模拟了人类大脑神经元的工作方式,为AI的发展打开了新的思路。而1950年,计算机先驱图灵提出了著名的图灵测试,成为判断机器是否具备智能的标准。图灵测试提出,如果一台机器能够与人类进行对话,且人类无法区分对方是机器还是真人,那么这台机器就具备了智能。
1.2 正式诞生:达特茅斯会议
1956年,在美国达特茅斯学院,一群科学家正式提出了“人工智能”这一术语,并将其确立为一门学科。这次会议被誉为AI的诞生地,从此,AI的研究正式拉开序幕。科学家们开始探索如何让机器具备类似于人类的智能,包括学习、推理、感知、理解语言等能力。
1.3 起伏发展:两次AI寒冬
然而,AI的发展并非一帆风顺。在随后的几十年里,AI经历了两次“寒冬”。初期,人们对AI的期望过高,但当时的技术水平有限,无法实现这些期望,导致研究资金减少,研究进入低谷。然而,每一次低谷之后,都是更加强劲的反弹。随着技术的进步和研究的深入,AI逐渐走出了低谷,迎来了新的发展机遇。
1.4 生成式AI的崛起:革命性突破

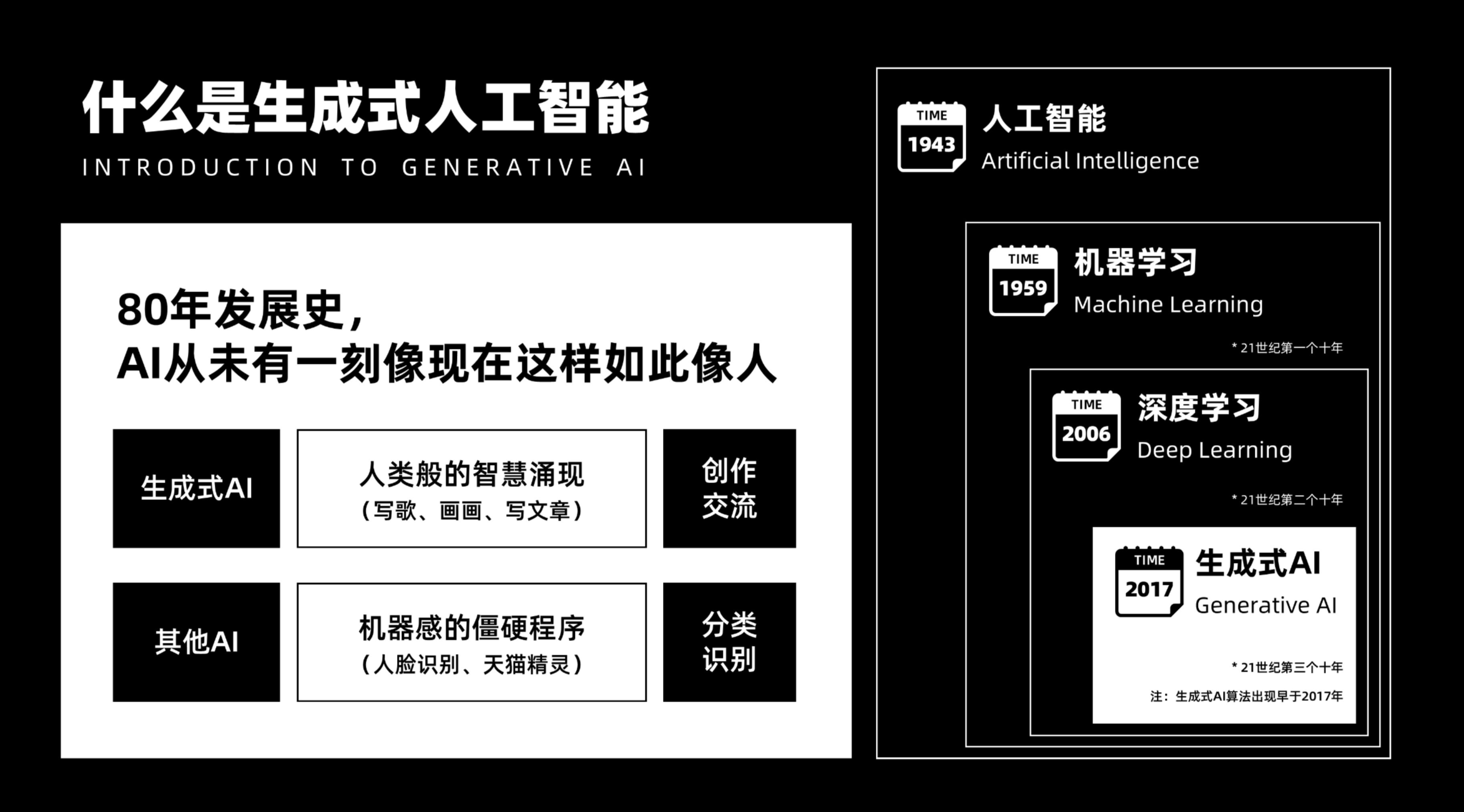
时间来到2022年,OpenAI发布的ChatGPT引发了全球范围内的AI热潮。ChatGPT是一款基于生成式AI技术的大语言模型,它能够理解人类的语言,并生成连贯、有意义的回答。这一次,AI不再是简单地完成分类判断任务,而是展现出了前所未有的创造力——写文章、画画、写歌……生成式AI(GenAI)的诞生,让AI真正开始像人一样思考和创作。
相比过去的AI,生成式AI在质量上有了根本性的提升。过去的AI主要完成一些预设的任务,如人脸识别、语音识别等,但它们的回答往往比较机械,缺乏创造性。而生成式AI则能够根据上下文生成连贯、有意义的文本或图像,甚至能够创作出具有独特风格的作品。这种跨时代的进步,让AI在某些细分场景中甚至通过了图灵测试,让人惊叹不已。
二、AI产业上下游图谱及机会分析
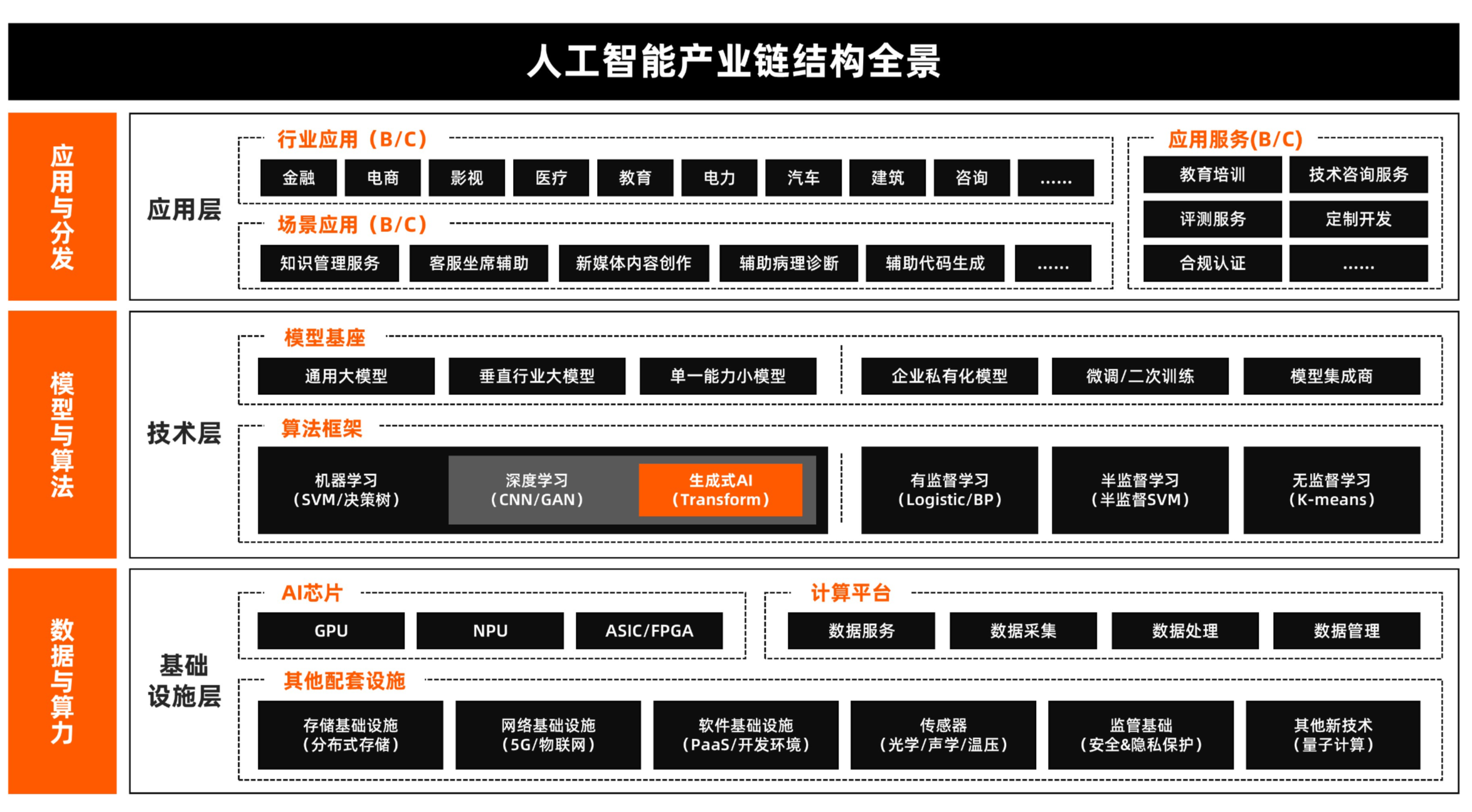
2.1 产业链结构
AI产业大致可分为上游的基础设施层(数据与算力)、中游的技术层(模型与算法)和下游的应用层(应用与分发)。每一层都蕴含着巨大的商机,同时也面临着不同的挑战和机遇。
2.2 机会分析
-
基础设施层:这是AI产业的基础,包括数据存储、处理、传输等基础设施,以及算力支持。随着AI应用的不断扩展,算力缺口巨大,但资金投入和资源门槛较高。未来,这一领域可能更多由“国家队”或大型企业主导。普通人可以通过合作生态的方式切入,如与云服务商合作,提供行业数据集等。
-
技术层:这是AI产业的核心,包括各种AI模型、算法的研发和优化。技术迭代迅速,新的模型和算法不断涌现,风险与机遇并存。对于小团队或个人而言,需谨慎考虑技术迭代风险,避免投入大量资源却因技术更新而失去竞争力。基础大模型研发烧钱且竞争激烈,非巨无霸公司需谨慎入局。
-
应用层:这是AI产业与用户直接接触的层面,包括各种AI应用和服务。尽管从业者众多,但成熟的应用产品仍不多见,尤其是针对特定行业或领域的垂直应用。对于普通个体和小团队而言,应用层拥有超级机会和巨大发展空间。通过深入挖掘用户需求,开发出具有创新性和实用性的AI应用,有望在市场中脱颖而出。
三、必须理解的核心概念和底层原理
3.1 核心概念
-
LLM(大语言模型):如ChatGPT等,是当前AI领域的热点。大语言模型通过海量数据的训练,能够理解人类的语言,并生成连贯、有意义的回答。
-
Prompt(提示词):输入给大模型的文本内容,质量好坏直接影响回答质量。一个好的提示词能够引导大模型生成更加准确、有用的回答。
-
Token:大模型语言体系中的最小单元,类似于人类语言中的字词。大模型在处理文本时,会将文本分割成一个个Token进行处理。
-
上下文:对话聊天内容前后的信息,影响AI回答的质量。大模型在生成回答时,会考虑上下文的信息,以确保回答的连贯性和准确性。
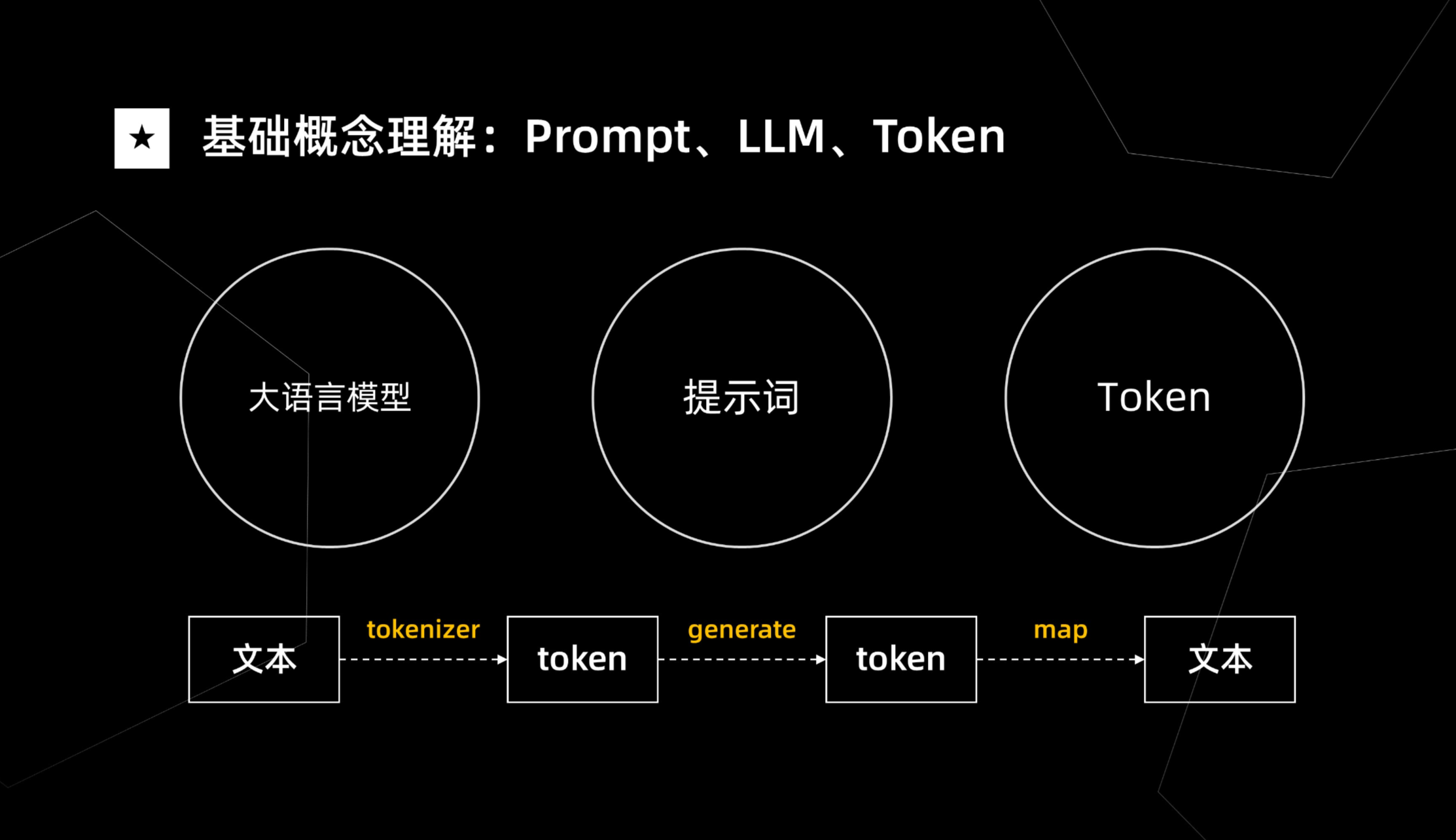
-
泛化能力:模型在未曾见过的数据上表现良好的能力。一个具有良好泛化能力的模型,能够在新场景下依然保持较好的性能。
-
多模态:多数据类型交互,提供更接近人类感知的场景。多模态AI能够同时处理文本、图像、音频等多种类型的数据,提供更加丰富、多样的服务。
-
对齐能力:与人类价值观与利益目标保持一致的能力。AI在发展过程中,需要确保其行为符合人类的价值观和利益目标,避免产生不良后果。
3.2 底层原理
AI大模型的底层原理可以概括为“仿生”,即科学家们模仿人类大脑的结构和工作方式,利用人工神经网络在计算机上实现了对智能的模拟。下面,我们将通过生动的比喻和详细的解释,带您领略AI大模型的神奇之处。
3.2.1 神经网络:模仿人类大脑的“黑盒模型”
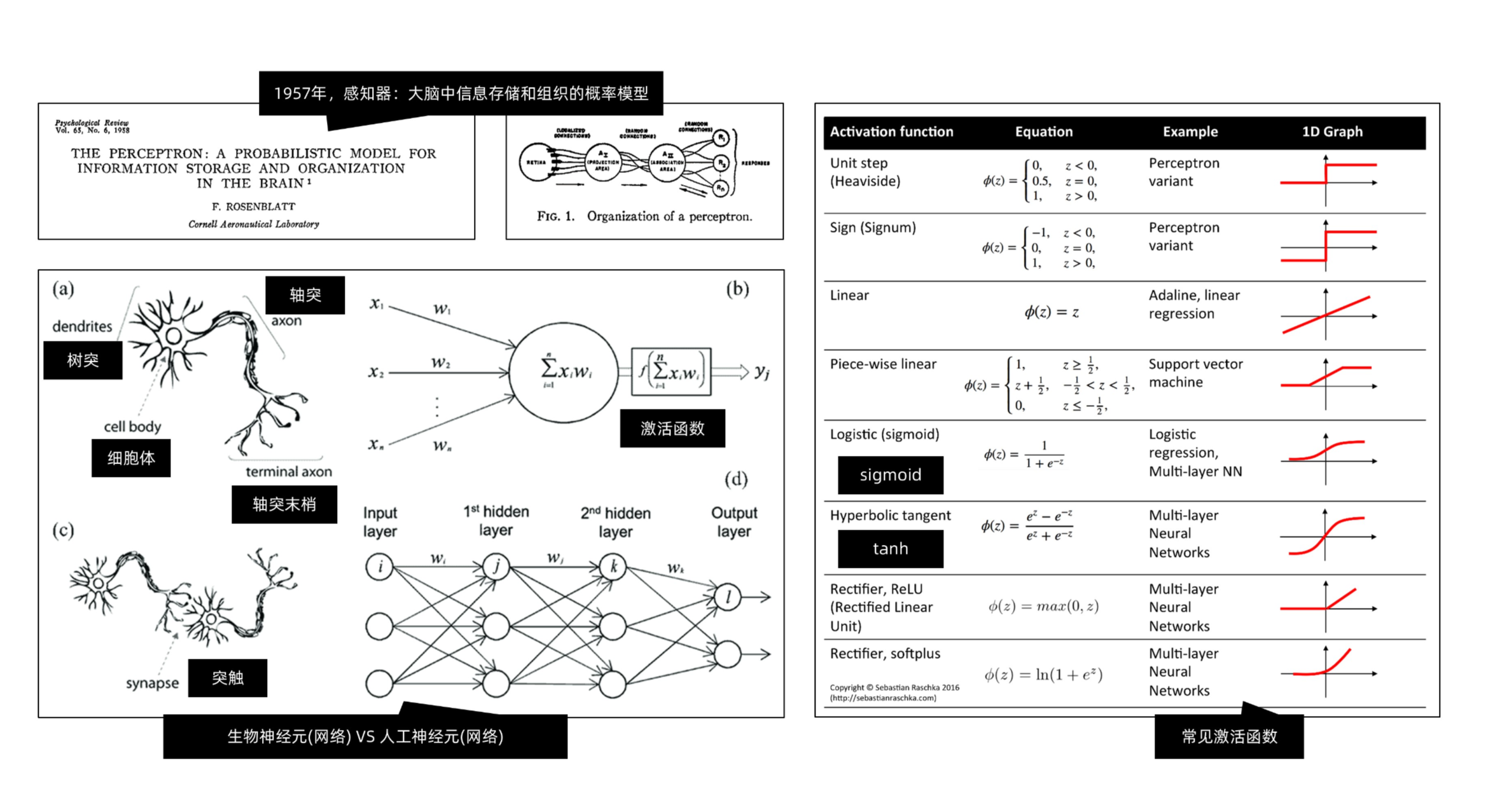
想象一下,人类的大脑是由数十亿个神经元相互连接而成的复杂网络。这些神经元通过传递电信号来处理信息,使我们能够感知世界、思考问题和做出决策。AI大模型中的神经网络,正是模仿了这种结构和工作方式。
神经网络由输入层、隐藏层和输出层组成。输入层负责接收外部数据,比如文本、图像或声音;隐藏层则像大脑中的“思考区域”,对数据进行复杂的处理和转换;输出层则产生最终的预测或决策结果。
在神经网络中,最基本的单位是“神经元”。每个神经元都像一个“小处理器”,它接收来自其他神经元的输入信号,通过加权和激活函数的处理,产生一个输出信号,并传递给下一个神经元。这个过程就像大脑中的神经元通过突触传递电信号一样。
3.2.2 预训练:让AI模型“博览群书”
预训练是AI大模型学习的第一步,也是最关键的一步。在这个阶段,模型会“博览群书”,接触海量的无标注数据,比如互联网上的文章、书籍、新闻报道等。通过自监督学习的方式,模型能够掌握语言的基本规律和知识,就像一个孩子读遍图书馆里的所有书,虽然还不知道这些知识具体有什么用,但他已经掌握了大量的背景信息。
预训练的过程可以比喻为“填鸭式教育”,但这里的“填鸭”并不是机械地灌输知识,而是让模型通过大量的数据学习到语言的内在逻辑和模式。经过预训练后,模型已经具备了强大的语言理解和生成能力。

3.2.3 微调:让AI模型“术业有专攻”
预训练后的AI模型虽然具备了强大的语言能力,但就像一个博览群书却缺乏实践经验的人一样,它可能无法直接胜任具体的工作任务。这时,就需要通过微调来让模型“术业有专攻”。
微调是在预训练模型的基础上,使用少量标注数据进行训练的过程。这些标注数据通常与具体任务相关,比如情感分析、机器翻译或问答系统等。通过微调,模型能够适应新的、具体的任务需求,就像让一个博览群书的人通过实践经验的积累,成为某个领域的专家。
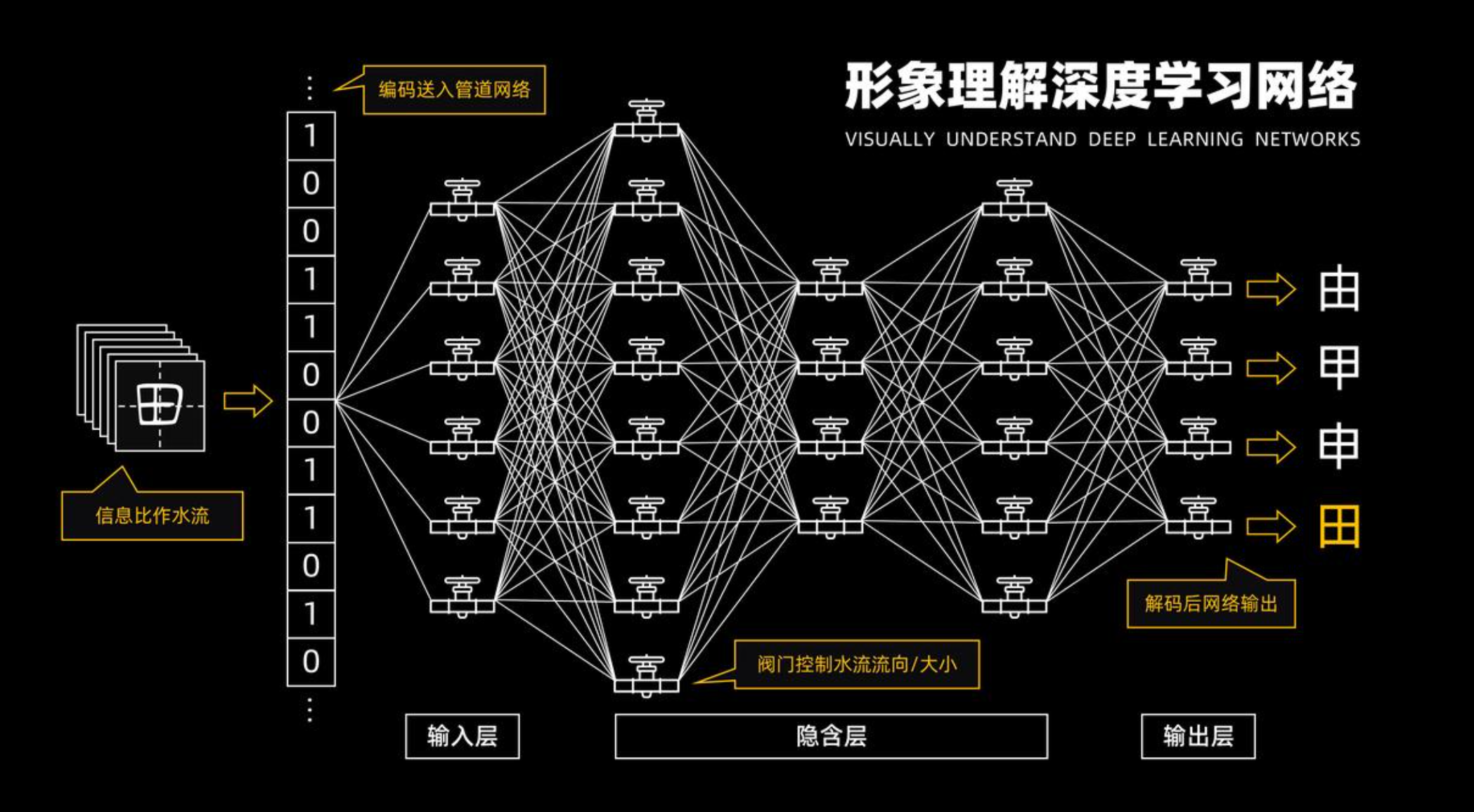
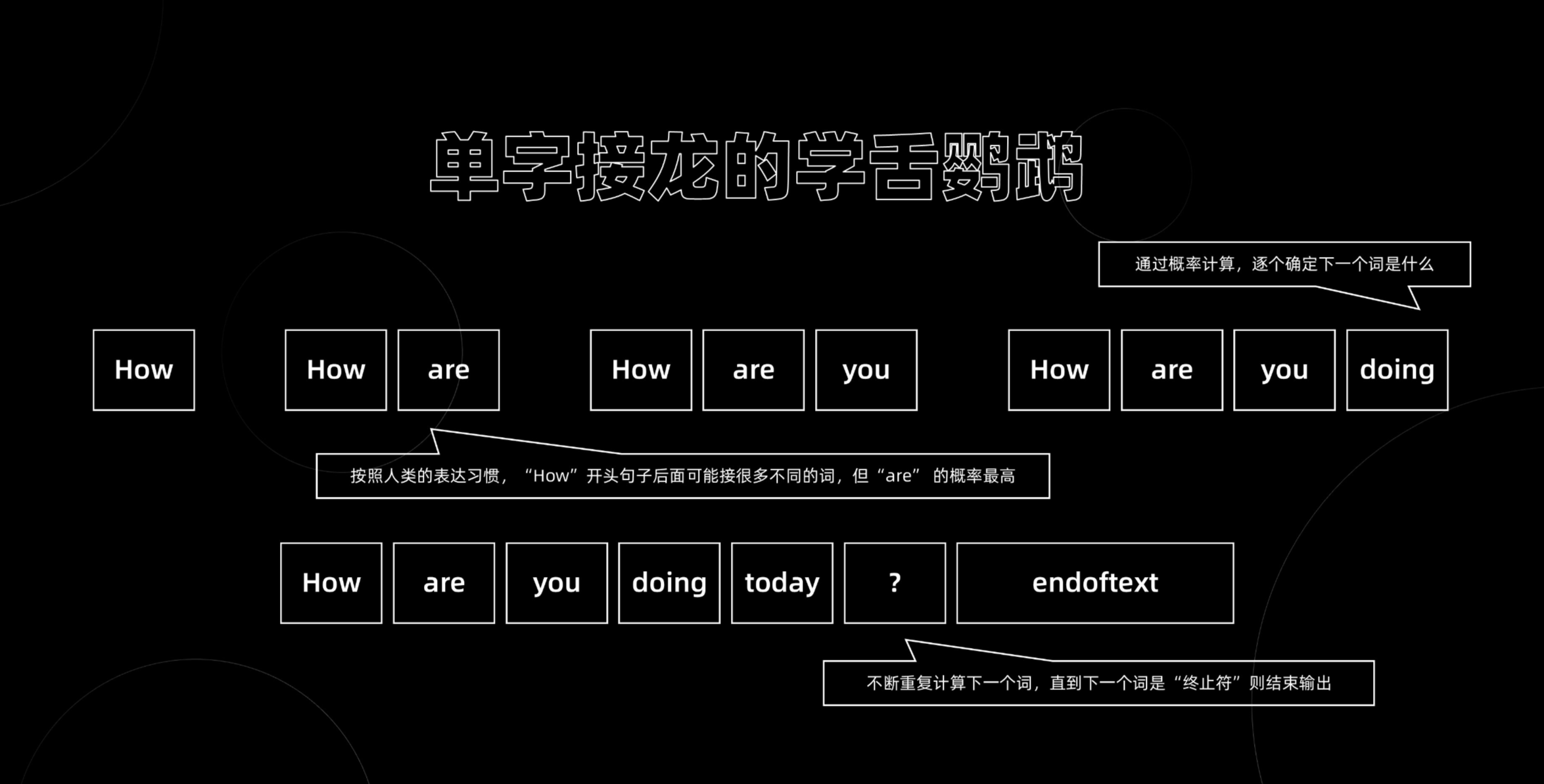
3.2.4 生成式AI:逐字生成回答的“单字接龙”游戏
生成式AI在生成回答时,采用了一种类似于“单字接龙”的游戏方式。它从输入的提示词开始,逐字生成回答。每次生成一个字词时,模型都会考虑上下文的信息,以及已经生成的字词,从而确保回答的连贯性和准确性。
这个过程可以比喻为“写作接力赛”,每个字词都是接力棒,模型需要不断地将接力棒传递给下一个字词,直到生成完整的回答。通过这种方式,生成式AI能够创作出连贯、有意义的文本或图像,甚至能够模仿特定风格的文字或图像。