RAG技术完全指南(三):LlamaIndex架构解析与私有知识库搭建
RAG技术完全指南(三):LlamaIndex架构解析与私有知识库搭建
文章目录
- RAG技术完全指南(三):LlamaIndex架构解析与私有知识库搭建
- 1. LlamaIndex简介
- 2. 核心功能
- 3. 关键流程
- 3.1 索引阶段
- 3.2 查询阶段
- 4. 应用场景
- 5. 特点总结
- 6. 快速开始
1. LlamaIndex简介
RAG 在实际应用中,通常使用 LlamaIndex 作为数据索引与检索框架,通过智能索引和查询优化,帮助开发者快速构建基于定制数据的 AI 应用(如问答、知识库等)。
LlamaIndex(原 GPT Index)是一个专为 大语言模型(LLM) 设计的 数据索引与检索框架,旨在解决私有数据与 LLM 结合时的效率与准确性问题。通过智能索引和查询优化,帮助开发者快速构建基于定制数据的 AI 应用(如问答、知识库等)。
2. 核心功能
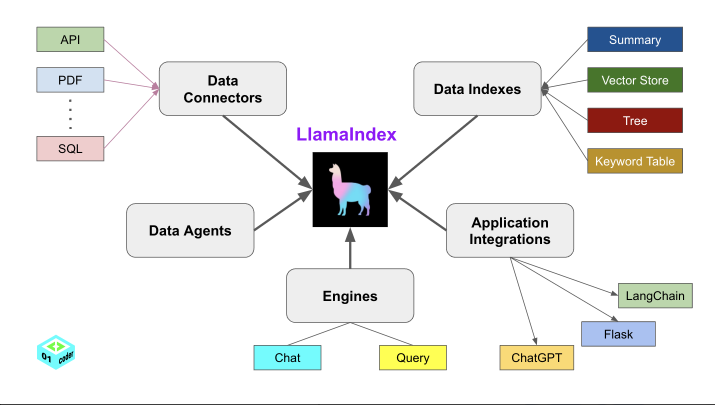
- Data Connectors(数据连接器)
支持从多种数据源加载和结构化数据:- 文档:PDF、Word、Markdown
- 数据库:SQL、PostgreSQL、MongoDB
- API/网页:REST API、爬虫抓取
- 云存储:S3、Google Drive
- Data Indexes(数据索引)
将原始数据转换为高效检索结构:- 向量索引:通过嵌入模型(如 OpenAI、HuggingFace)生成向量,支持相似性搜索。
- 关键词索引:传统全文检索,适合精确匹配。
- 混合索引:结合向量+关键词,平衡精度与速度。
- Engines(查询引擎)
- 自然语言交互:用户输入问题,引擎从索引中检索相关片段,生成精准回答。
- 避免上下文爆炸:仅向 LLM 输入相关数据片段,节省 token 并提升响应速度。
- Application Integrations(应用集成)
- LLM 兼容:OpenAI、Anthropic、本地模型(Llama 2)等。
- 框架扩展:与 LangChain、Flask、FastAPI 无缝集成。
- 部署工具:支持 Gradio、Streamlit 快速构建 Web 界面。
- Data Agents(数据代理)
- 动态数据更新:自动监控数据源变化(如数据库更新),实时同步索引。
- 多步骤推理:通过 Agent 调用工具(如计算、搜索)完成复杂任务。
3. 关键流程
3.1 索引阶段
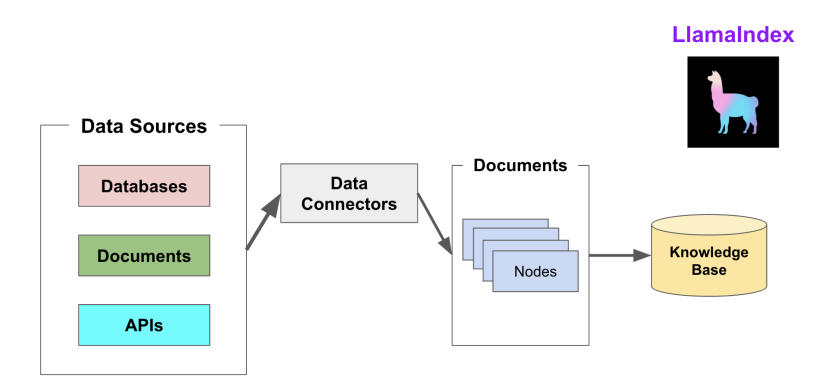
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
- Data Connectors(数据连接器):负责将来自不同数据源的不同格式的数据注入,并转换为 LlamaIndex 支持的文档(Document),其中包含了文本和元数据。
- Document: 是 LlamaIndex 中容器的概念,它可以包含任何数据源,包括:PDF文档、API响应或来自数据库的数据等。
- Node: 是 LlamaIndex 中数据的最小单元,代表了一个 Document 的分块。它还包含了元数据,以及与其他 Node 的关系信息。这使得更精确的检索操作成为可能。
- Data Indexes(数据索引): 帮助开发者为注入的数据建立索引,使得未来的检索简单而高效(最常用的索引是向量存储索引 - VectorStoreIndex)。
最后将这些数据进行 embedding 操作,将数据转化为向量,存储到向量数据库中,以便后续的检索操作。
3.2 查询阶段
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与用户查询一起,传递给 LLM,以合成响应。这使得 LLM 能够获取到不在其原始训练数据中的知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
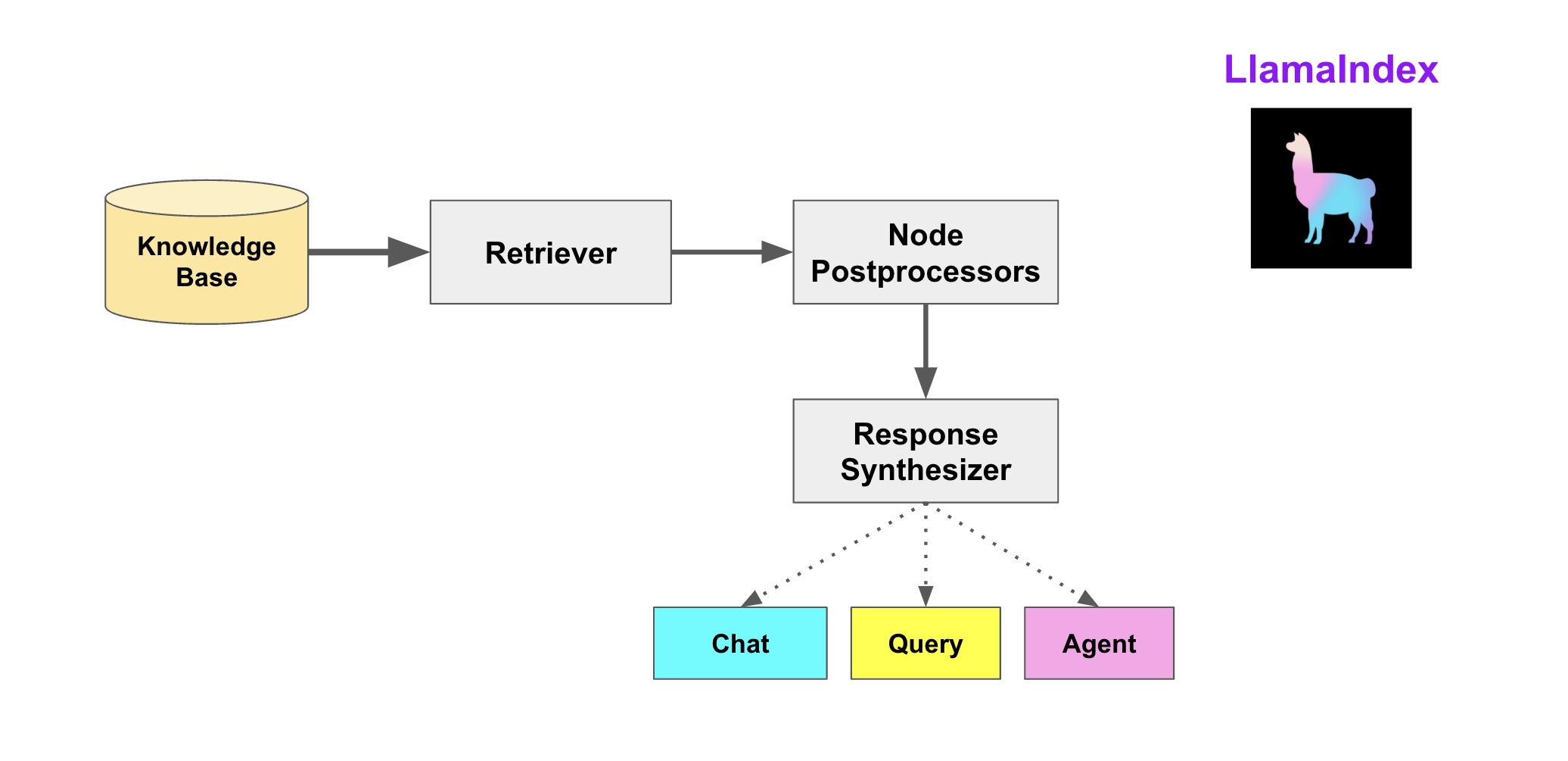
- Retrievers(检索器):定义如何高效地从知识库,基于查询,检索相关上下文信息。
- Node Postprocessors(Node后处理器):它对一系列文档节点(Node)实施转换、过滤或排名。
- Response Synthesizers(响应合成器):它基于用户的查询,和一组检索到的文本块(形成上下文),利用 LLM 生成响应。
RAG管道包括:
- Query Engines(查询引擎):端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下
文。 - Chat Engines(聊天引擎): 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
- Agents(代理):它是一种由 LLM 驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
4. 应用场景
- 企业知识库问答:内部文档的智能检索系统。
- 个人知识管理:链接笔记、论文、网页的个性化 AI 助手。
- RAG(检索增强生成):为 LLM 提供实时外部数据支持。
- 数据分析:从非结构化报告中提取结构化信息。
5. 特点总结
- 开发者友好:Python 优先,提供高级 API 和低阶自定义选项。
- 轻量高效:索引优化减少 LLM 调用成本。
- 模块化设计:可单独使用组件(如仅用数据连接器)。
6. 快速开始
安装 LlamaIndex(说明文档):
# 创建虚拟环境
conda create -n llamaindex python==3.12 -y && conda activate llamaindex
# 安装 LlamaIndex
pip install llama-index
# 安装 LlamaIndex 的 HuggingFace LLM 支持
pip install llama-index-llms-huggingface
实例代码:
from llama_index.core.llms import ChatMessage
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, SimpleDirectoryReader, VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLMdef load_local_llm():# 初始化一个HuggingFace LLM对象,用于生成回复model_path = "/your/llm/model/path"return HuggingFaceLLM(model_name=model_path,tokenizer_name=model_path,model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True},)def load_local_embedding():# 初始化一个HuggingFace Embedding对象,用于将文本转换为向量表示return HuggingFaceEmbedding(# 指定了一个预训练的sentence-transformer模型的路径model_name="/your/embedding/model/path")def chat_without_rag(llm, query):# 调用模型chat引擎得到回复return llm.chat(messages=[ChatMessage(content=query)])def chat_with_rag(embed_model, llm, query):# 设置全局的embed_model属性,在索引构建时会使用这个模型。Settings.embed_model = embed_model# 设置全局的llm属性,在索引查询时会使用这个模型。Settings.llm = llm# 从指定目录读取文档,将数据加载到内存documents = SimpleDirectoryReader("your/documents/path").load_data()print(f"documents: {documents}\n")# 创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引# 此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索index = VectorStoreIndex.from_documents(documents)# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。query_engine = index.as_query_engine()return query_engine.query(query)if __name__ == "__main__":llm = load_local_llm()embed_model = load_local_embedding()question = "什么是RAG?"print(f"Q: {question}")print("=" * 20)print(f"Answer without RAG:\n{chat_without_rag(llm, question)}")print("=" * 20)print(f"Answer with RAG:\n{chat_with_rag(embed_model, llm, question)}")