支持向量机(SVM)详解
引言
支持向量机(Support Vector Machine, SVM)是一种强大的监督学习算法,主要用于分类和回归任务。其核心思想是找到一个最优的决策边界(超平面),最大化不同类别之间的间隔(Margin)。SVM 在小样本、高维数据和非线性问题中表现优异,广泛应用于图像识别、文本分类、生物信息学等领域。
1. SVM 核心思想
(1) 线性可分情况
- 目标:找到一个超平面 ( \mathbf{w}^T \mathbf{x} + b = 0 ),将两类数据分开。
- 间隔(Margin):离超平面最近的样本点到超平面的距离。SVM 的目标是最大化间隔。
- 支持向量:距离超平面最近的样本点,决定了超平面的位置。
数学形式:
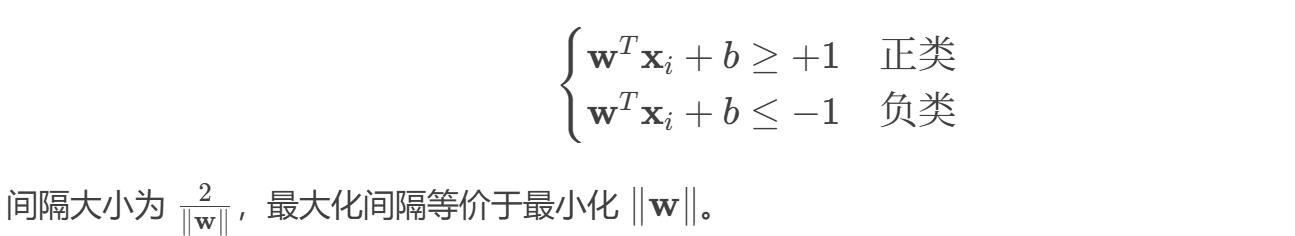
(2) 非线性可分情况
- 当数据线性不可分时,SVM 通过**核技巧(Kernel Trick)**将数据映射到高维空间,使其线性可分。
- 常用核函数:
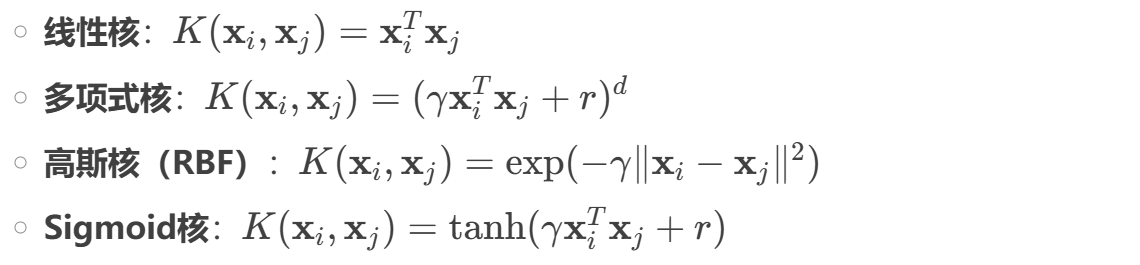
2. SVM 的优化问题

3. SVM 的分类与回归
(1) 分类(SVC)
- 二分类:直接使用超平面划分两类。
- 多分类:通过“一对多”(One-vs-Rest)或“一对一”(One-vs-One)策略扩展。
(2) 回归(SVR)
- 目标:拟合一个“间隔带”(( \epsilon )-insensitive tube),最大化间隔的同时容忍一定误差。
- 优化问题类似分类,但约束条件不同:
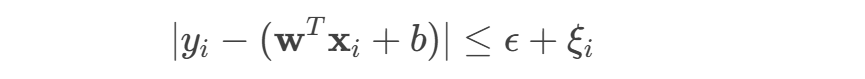
4. SVM 的优缺点
优点
- 在高维空间中表现优秀(适合文本、图像数据)。
- 核技巧可处理非线性问题。
- 泛化能力强,尤其适合小样本数据。
缺点
- 计算复杂度高,训练时间随数据量增长(适合小到中等数据集)。
- 对参数(如 ( C )、核函数)敏感,需调参。
- 难以直接解释模型(黑盒性较强)。
5. 代码示例(Scikit-Learn)
(1) 线性 SVM 分类
from sklearn.svm import SVC
from sklearn.datasets import make_classification# 生成数据
X, y = make_classification(n_samples=100, n_features=2, n_classes=2, random_state=42)# 训练模型
model = SVC(kernel='linear', C=1.0)
model.fit(X, y)# 预测
print(model.predict([[0.5, -0.5]])) # 输出类别
(2) 非线性 SVM(RBF 核)
from sklearn.svm import SVC# 使用高斯核(RBF)
model = SVC(kernel='rbf', gamma=0.1, C=1.0)
model.fit(X, y)
(3) SVM 回归(SVR)
from sklearn.svm import SVR# 训练回归模型
model = SVR(kernel='rbf', C=1.0, epsilon=0.1)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)
6. 关键参数调优
| 参数 | 作用 | 推荐调整范围 |
|---|---|---|
C | 控制分类错误的惩罚(越大越严格) | ( 10^{-3} ) 到 ( 10^3 ) |
kernel | 核函数类型(linear, rbf, poly, sigmoid) | 根据数据非线性程度选择 |
gamma | RBF/多项式核的系数(越大模型越复杂) | ( 10^{-3} ) 到 ( 10^3 ) |
epsilon | SVR 的间隔带宽度(允许的误差范围) | 0.1 到 1.0 |
7. 应用场景
- 文本分类:垃圾邮件检测(高维稀疏数据)。
- 图像识别:手写数字分类(MNIST)。
- 生物信息学:基因序列分类。
- 金融风控:信用评分(小样本高维数据)。
8. 总结
- SVM 的核心:最大化间隔,利用核函数处理非线性问题。
- 适用场景:小到中等数据集、高维特征、需强泛化能力的任务。
- 调参关键:选择核函数、调整 ( C ) 和
gamma。 - 扩展阅读:
- 对偶问题(Lagrange 乘子法)。
- 序列最小优化(SMO)算法。
- 支持向量回归(SVR)。