【Hive入门】Hive性能调优:小文件问题与动态分区合并策略详解
目录
引言
1 Hive小文件问题概述
1.1 什么是小文件问题
1.2 小文件产生的原因
2 Hive小文件合并机制
2.1 hive.merge.smallfiles参数详解
2.2 小文件合并流程
2.3 合并策略选择
3 动态分区与小文件问题
3.1 动态分区原理
3.2 动态分区合并策略
3.3 动态分区合并流程
4 高级调优技巧
4.1 基于存储格式的优化
4.2 定时合并策略
4.3 写入时优化
5 案例分析
5.1 日志分析案例
5.2 数据仓库ETL案例
6 监控与评估
6.1 小文件检测方法
6.2 性能评估指标
7 总结
7.1 Hive小文件处理
7.2 参数推荐配置
引言
在大数据领域,Apache Hive作为构建在Hadoop之上的数据仓库工具,被广泛应用于数据ETL、分析和报表生成等场景。然而,随着数据量的增长和业务复杂度的提升,Hive性能问题逐渐显现,其中小文件问题尤为突出。本文将深入探讨Hive中的小文件问题及其解决方案,特别是通过参数hive.merge.smallfiles进行小文件合并和动态分区合并的技术细节。
1 Hive小文件问题概述
1.1 什么是小文件问题
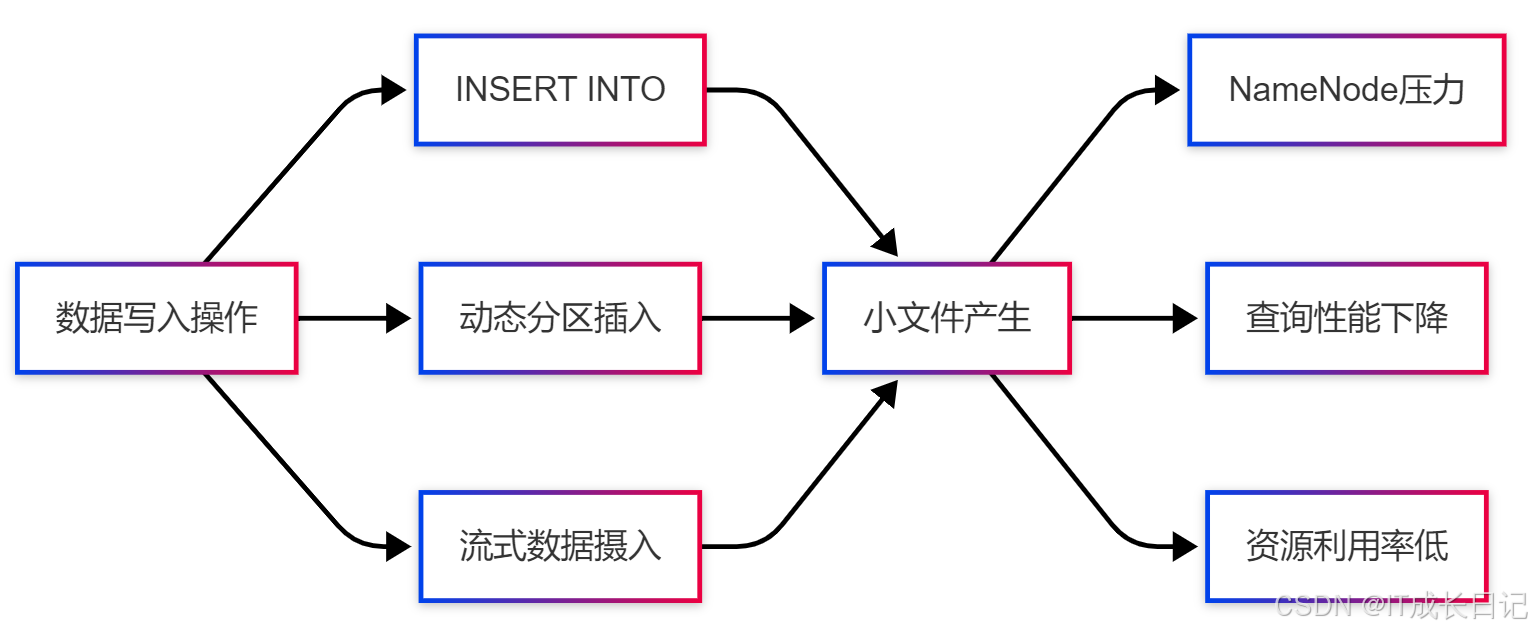
小文件问题指的是在Hadoop分布式文件系统(HDFS)中存储了大量远小于HDFS块大小(通常为128MB或256MB)的文件。这些小文件会导致:
- NameNode内存压力:HDFS中每个文件、目录和块都会在NameNode内存中占用约150字节的空间
- MapReduce效率低下:每个小文件都会启动一个Map任务,造成任务调度开销远大于实际数据处理时间
- 查询性能下降:Hive查询需要打开和处理大量文件,增加了I/O开销
1.2 小文件产生的原因
在Hive中,小文件通常由以下操作产生:
- 频繁执行INSERT语句:特别是INSERT INTO和动态分区插入
- 动态分区:当分区字段基数(cardinality)很高时,会产生大量小文件
- 流式数据摄入:如Flume、Kafka等实时写入小批量数据
- 过度分区:分区粒度过细导致每个分区数据量很小
2 Hive小文件合并机制
2.1 hive.merge.smallfiles参数详解
Hive提供了hive.merge.smallfiles参数来控制小文件合并行为:
-- 开启小文件合并
SET hive.merge.mapfiles = true; -- 合并Map-only作业输出的小文件
SET hive.merge.mapredfiles = true; -- 合并MapReduce作业输出的小文件
SET hive.merge.smallfiles.avgsize = 16000000; -- 平均文件大小小于该值会触发合并
SET hive.merge.size.per.task = 256000000; -- 合并后每个文件的目标大小参数解释:
- hive.merge.mapfiles:控制是否合并Map-only任务输出的文件,默认false
- hive.merge.mapredfiles:控制是否合并MapReduce任务输出的文件,默认false
- hive.merge.smallfiles.avgsize:当输出文件的平均大小小于此值时,启动合并流程,默认16MB
- hive.merge.size.per.task:合并操作后每个文件的目标大小,默认256MB
2.2 小文件合并流程

合并过程详细说明:
- 评估阶段:作业完成后,Hive计算输出文件的平均大小
- 决策阶段:如果平均大小小于阈值,则触发合并流程
- 执行阶段:启动一个额外的MapReduce任务读取所有小文件
- 写入阶段:按照目标大小将数据重新写入新文件
- 清理阶段:合并完成后删除原始小文件
2.3 合并策略选择
Hive支持两种合并策略:
- 合并为更大的文件:
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=16000000;- 合并为ORC/Parquet的块(针对列式存储):
SET hive.exec.orc.default.block.size=256000000;
SET parquet.block.size=256000000;3 动态分区与小文件问题
3.1 动态分区原理
动态分区允许Hive根据查询结果自动创建分区
- 语法
INSERT INTO TABLE employee_partitioned
PARTITION(dept, country)
SELECT name, salary, dept, country
FROM employee;动态分区优势:
- 简化了多分区写入操作
- 避免了手动指定每个分区
动态分区问题:
- 容易产生大量小文件
- 当分区字段基数高时问题更严重
3.2 动态分区合并策略
针对动态分区的小文件问题,Hive提供了专门的优化参数:
-- 开启动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;-- 动态分区优化
SET hive.merge.tezfiles=true; -- 在Tez引擎上合并文件
SET hive.merge.sparkfiles=true; -- 在Spark引擎上合并文件
SET hive.exec.insert.into.multilevel.dirs=true; -- 支持多级目录插入3.3 动态分区合并流程

优化技巧:
- 限制最大动态分区数:
SET hive.exec.max.dynamic.partitions=1000;
SET hive.exec.max.dynamic.partitions.pernode=100;- 分区裁剪:在查询前过滤不必要分区
SET hive.optimize.dynamic.partition.prune=true;- 合并层级控制:对于多级分区,可以控制合并粒度
SET hive.merge.level=partition; -- 按分区合并4 高级调优技巧
4.1 基于存储格式的优化
不同存储格式对小文件处理有不同影响:
| 存储格式 | 小文件处理能力 | 合并效率 | 适用场景 |
| TEXT | 差 | 高 | 原始数据 |
| ORC | 中 | 中 | 分析查询 |
| Parquet | 中 | 中 | 分析查询 |
| AVRO | 好 | 低 | 序列化 |
- ORC格式优化示例:
CREATE TABLE optimized_table (...
) STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","orc.create.index"="true","orc.stripe.size"="268435456", -- 256MB"orc.block.size"="268435456" -- 256MB
);4.2 定时合并策略
对于无法避免小文件产生的场景,可以设置定时合并任务:
- 使用Hive合并命令:
ALTER TABLE table_name CONCATENATE;- 使用Hadoop Archive(HAR):
hadoop archive -archiveName data.har -p /user/hive/warehouse/table /user/hive/archive- 自定义合并脚本:
# 示例
for partition in partitions:if avg_file_size(partition) < threshold:merge_files(partition, target_size)4.3 写入时优化
在数据写入阶段预防小文件产生:
- 批量插入:减少INSERT操作频率
- 合理设置Reduce数量:
SET mapred.reduce.tasks=适当数量;- 使用CTAS代替INSERT:
CREATE TABLE new_table AS SELECT * FROM source_table;5 案例分析
5.1 日志分析案例
- 场景:每日用户行为日志,按dt(日期)、hour(小时)两级分区
- 问题:每小时一个约5MB的小文件
- 解决方案:
-- 建表时指定合并参数
CREATE TABLE user_behavior (user_id string,action string,...
) PARTITIONED BY (dt string, hour string)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","hive.merge.mapfiles"="true","hive.merge.smallfiles.avgsize"="64000000", -- 64MB"hive.merge.size.per.task"="256000000" -- 256MB
);-- 插入数据时控制动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode=100;INSERT INTO TABLE user_behavior
PARTITION(dt, hour)
SELECT user_id, action, ..., dt, hour
FROM raw_log;5.2 数据仓库ETL案例
- 场景:每日全量同步上游数据库表
- 问题:全表扫描产生大量小文件
- 解决方案:
-- 使用CTAS创建中间表
CREATE TABLE temp_table STORED AS ORC AS
SELECT * FROM source_table;-- 使用DISTRIBUTE BY控制文件分布
SET hive.exec.reducers.bytes.per.reducer=256000000;INSERT OVERWRITE TABLE target_table
SELECT * FROM temp_table
DISTRIBUTE BY FLOOR(RAND()*10); -- 随机分布到10个Reducer-- 定期合并历史分区
ALTER TABLE target_table PARTITION(dt='20230101') CONCATENATE;6 监控与评估
6.1 小文件检测方法
- HDFS命令检查:
hdfs dfs -count -q /user/hive/warehouse/db/table- Hive元数据查询:
SELECT partition_name, file_count, total_size
FROM metastore.PARTITIONS p
JOIN metastore.TBLS t ON p.TBL_ID = t.TBL_ID
WHERE t.TBL_NAME = 'table_name';- 自定义监控脚本:
# 检查分区文件数量和大小分布
for part in partitions:files = list_files(part)if len(files) > threshold:alert_small_files(part)6.2 性能评估指标
| 指标 | 优化前 | 优化后 | 测量方法 |
| 文件数量 | 1000 | 10 | hdfs dfs -count |
| NameNode内存使用 | 高 | 低 | NameNode UI |
| 查询响应时间 | 慢 | 快 | EXPLAIN ANALYZE |
| 任务执行时间 | 长 | 短 | JobHistory |
7 总结
7.1 Hive小文件处理
预防为主:
- 合理设计分区策略
- 控制动态分区数量
- 使用适当Reduce数量
合并为辅:
- 启用hive.merge.smallfiles
- 定期执行合并操作
- 根据存储格式调整参数
监控持续:
- 建立小文件监控告警
- 定期评估合并效果
- 根据业务变化调整策略
7.2 参数推荐配置
-- 通用小文件合并配置
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=64000000; -- 64MB
SET hive.merge.size.per.task=256000000; -- 256MB-- 动态分区优化配置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=2000;
SET hive.exec.max.dynamic.partitions.pernode=100;-- 存储格式优化
SET hive.exec.orc.default.block.size=268435456; -- 256MB
SET parquet.block.size=268435456; -- 256MB通过合理配置这些参数可以显著改善Hive中的小文件问题,提升集群整体性能和查询效率。