Mybatis学习笔记
介绍
MyBatis 是一款优秀的持久层开发框架,它在 Java 开发中被广泛应用,以下是对它的详细介绍:
概述
MyBatis 最初是 Apache 的一个开源项目 iBatis,2010 年这个项目由 Apache Software Foundation 迁移到了 Google Code,并改名为 MyBatis。它是一个基于 Java 的持久层框架,主要用于将 Java 应用程序与数据库进行交互,提供了一种灵活且高效的方式来执行 SQL 语句、映射数据库结果集到 Java 对象等。
核心功能
SQL 映射:MyBatis 的核心是 SQL 映射,它通过 XML 文件或注解的方式将 SQL 语句与 Java 方法进行关联。开发人员可以在 XML 文件中编写复杂的 SQL 语句,然后通过 Java 方法来执行这些 SQL。
基础配置和使用:
1.引入Maven坐标:
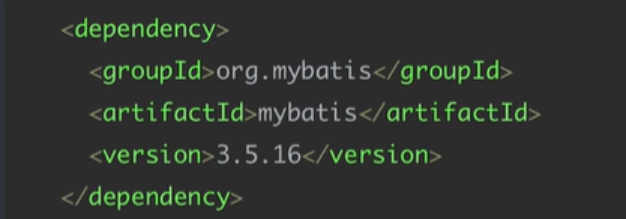
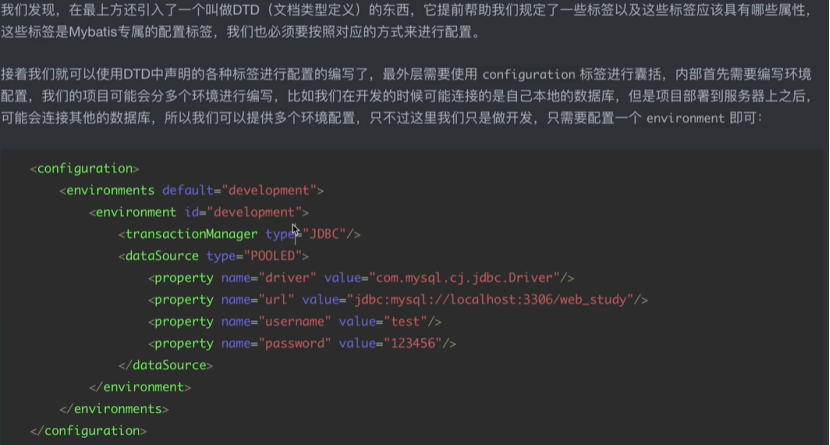
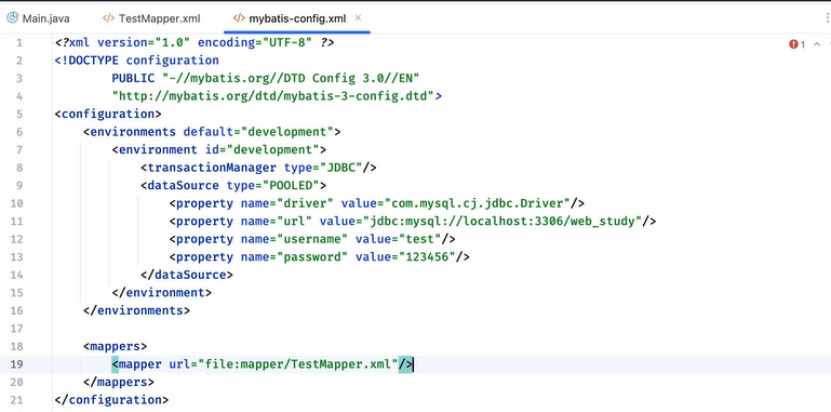
2.创建一个mybatis-config.xml的配置文件:

下面就可以定义一些环境的信息
transactionManager 事务管理器
dataSource,POOLED 数据源
里面写数据库连接信息
分别是驱动,url,user和密码
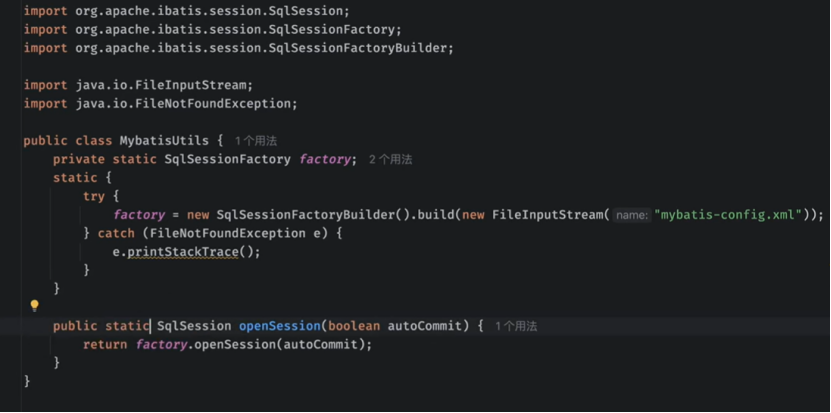
3.sql-session
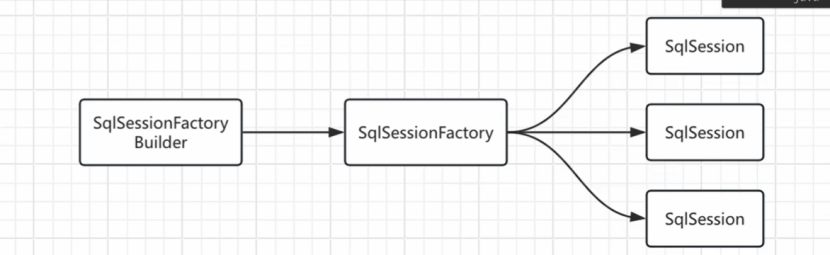
这个可以用来创建和sql数据库的会话
先创建sqlsessionFactory ,通过builder这个来创建factory,通过这个factory和数据库连接
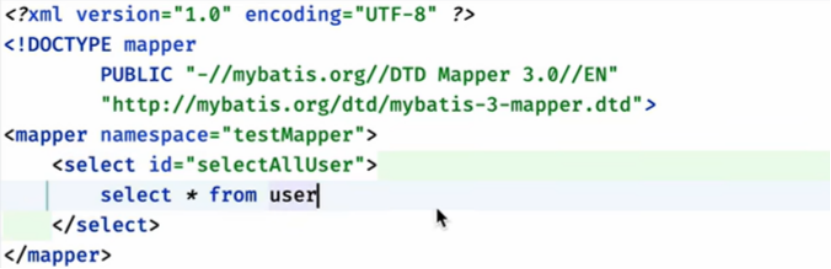
4.Mapper.xml
根目录创建一个mapper文件夹,里面创建mapper.xml文件
里面就可以写sql查询语句
5.创建数据库对应的实体类:并且尽可能都一一对应

6.然后去mybatis的environment后面添加<mappers>,添加Mapper.xml
7.使用session去查询即可,根据查询的个数使用list or one
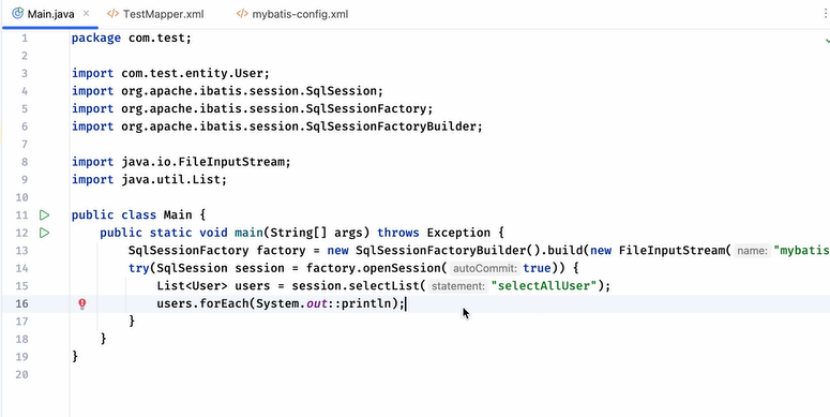
Firsttttt:查询操作:
思想,创建一个Mybatis的类,之后需要查询,找这个类建立会话即可,这样可以简化流程
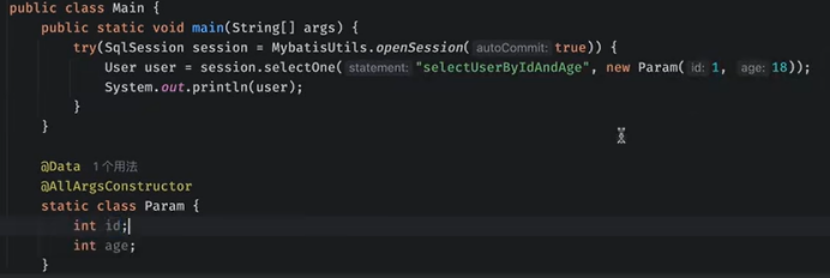
写一个通过id查找user
paramterType=”_int”Mybatis会自己找
这里可以省略,

在<mapper>中去写

#{}和${},推荐#{},后一个是直接的拼接,第一个可以防止sql注入
这里的type可以在在mybatis-config.xml配置文件里面去写别名,这样之后就可以直接写别名即可

也可以通过

让系统取自动的别名(文件名)
()resultType之后是parameterType
如果查询的参数多,可以通过这样传输:


Map.of()也可以改为 new Param()
如果你的字段名和数据库的字段名不一样,可以通过:
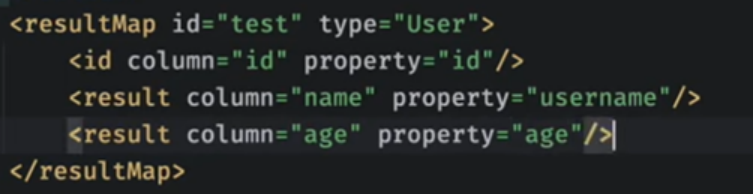
前面是数据库名,后面是类中字段名
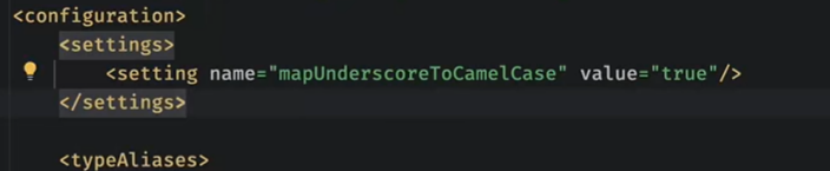
驼峰命名经典映射oneTwo ->one_two
在mybatis的配置文件中config里面加入settings,把
resultMap:
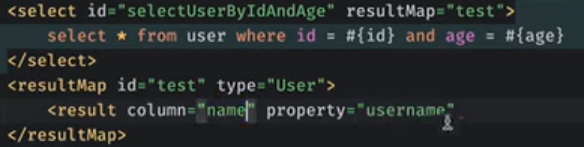
把数据库的name映射为变量名username
如上配置
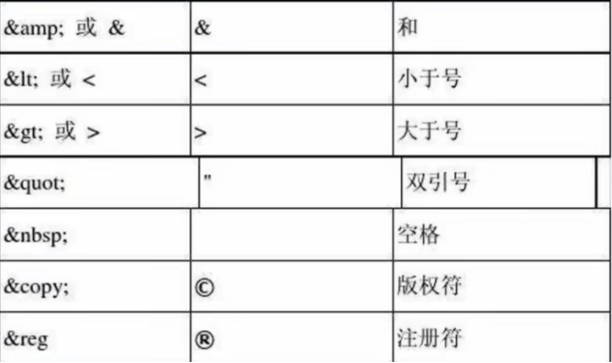
如果出现了> or < 可以用转义字符

多个数据可以selectList也可以selectMap
返回的是Map<string,object>
也可以:Cursor

也可以普通的select:

每完成一个查询就会执行一次lambda表达式的内容
Second::指定构造对象的方法:
Mybatis会通过无参构造返回我们的对象,属性通过反射赋值

如果无参构造被其他的覆盖了,他也会去找其他的构造方法去构造对象
如果存在多个构造,就会出现错误
如果想指定方法,而不是反射,需要在mapper.xml中去配置对应对象的constructor即可
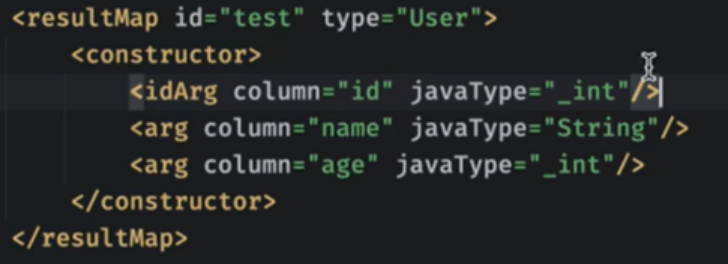
表明使用3个对应的参数就不会反射赋值了
这样之后就可以通过我们的构造方法返回值了
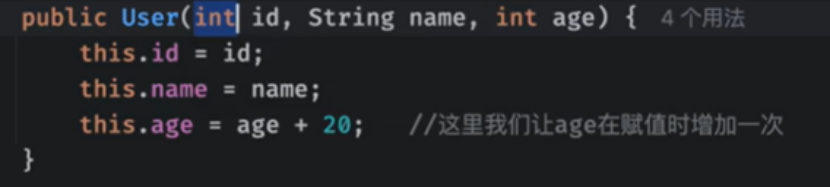
返回的值就是比原来的大20
Third::::接口绑定:
定义一个mapper类:TestMapper

同时在TestMapper.xml文件中的mapper的namespace修改为TestMapper类的完整路径名
推荐都放在在同一个文件夹
,可以放在类文件夹中,记得去修改mybatis-config.xml的mapper.xml的文件路径哦
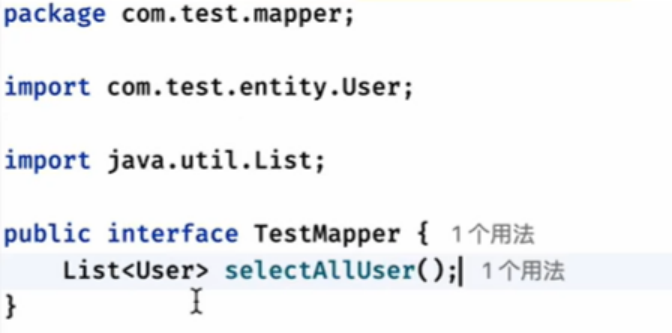

名字和id对应,返回值也和resultTpye对应
使用直接如下即可:
创建mapper对象,使用对应方法

多参数@param()绑定参数即可
![]()
fourth:::复杂查询:
一对一查询:
多来一个表:

同时创建以下对应的对象Userdetail
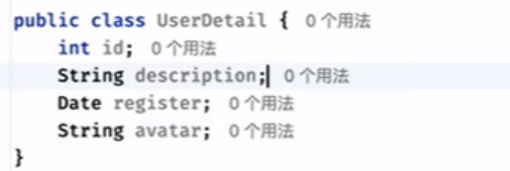
同时user和userdetail一对一绑定
mybatis两个方式来加载关联:
嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集
左连接(通过id来连接):
select如下去写
![]()
然后使用association来连接

这样就detail和user一一对应了
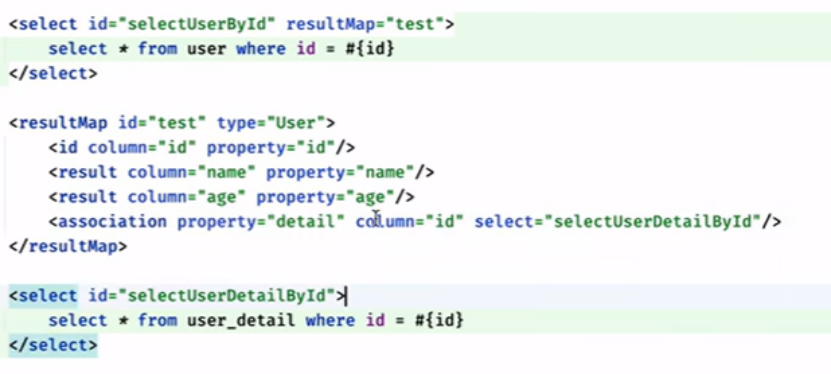
嵌套select查询:通过执行另外一个sql映射语句来加载期望的复杂类型
将两个语句拆分,先找到user的id,再通过这个id去userdetail去查询,
如下
(column表示通过那个参数去进一步查询)
mybatis打开MySQL日志:再config里面加入

即可
一对多查询:
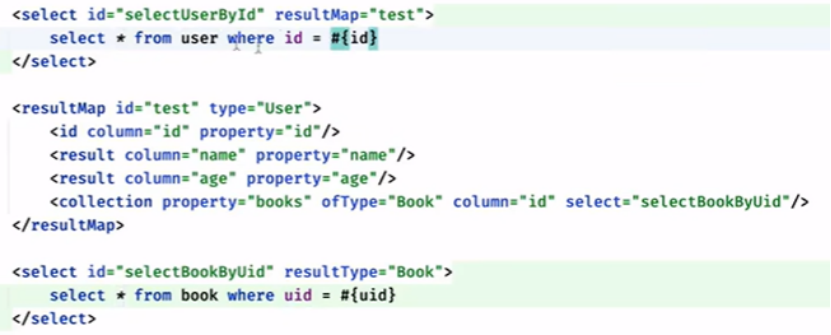
假设一个user有多个书:
建立一个book的对象:
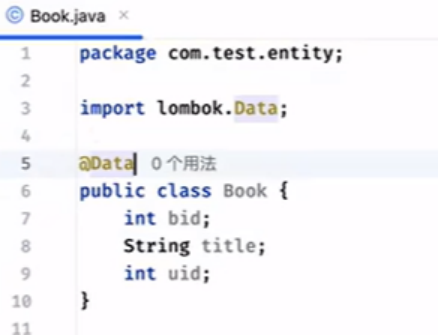
user有多个书:
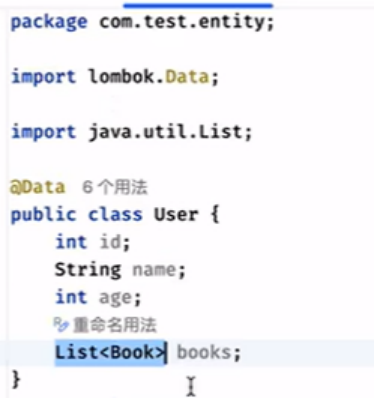
方法一:
使用关联查询:
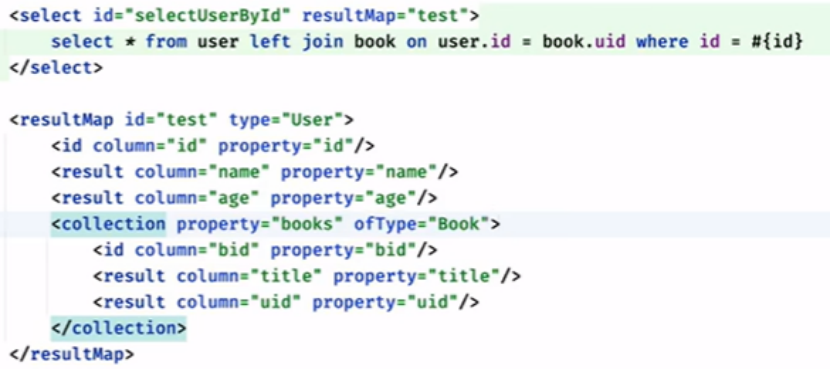
方法二:
当然也可以多次查询
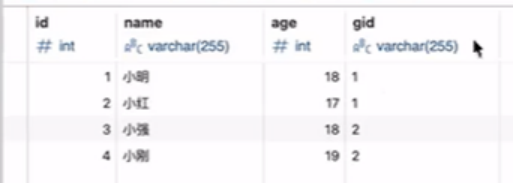
多对一查询:
多个人,对应一个组
组的表:

再user里面去记录组名
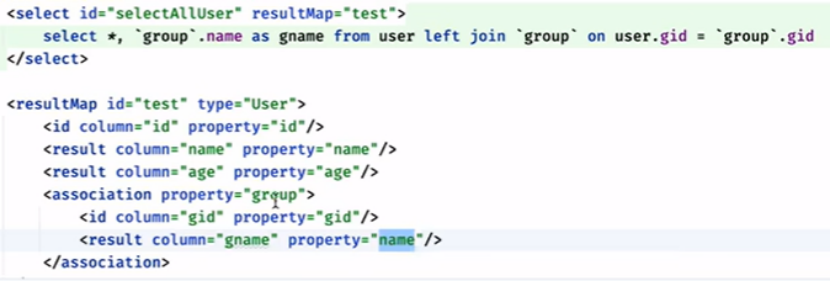
第一种用法:
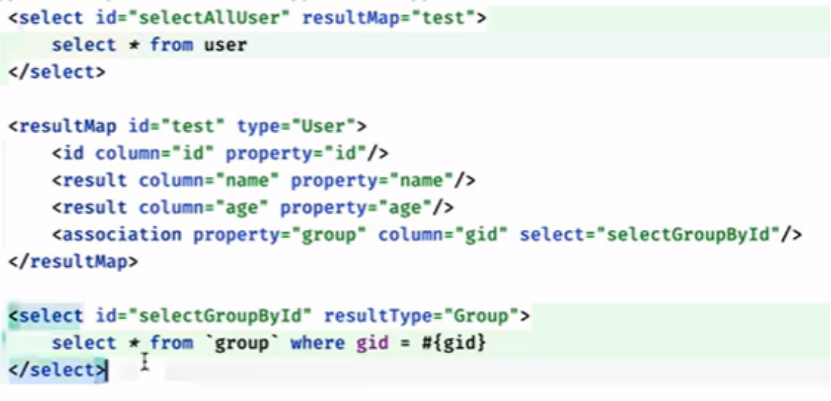
第二种用法:
FivTH:DML操作:
相关返回的int都是受影响的行数
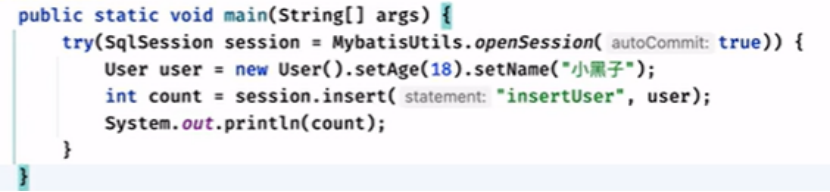
insert操作:
传入user,将对应的name和age插入数据库

1-使用对话去调用
2-使用testmapper的对象去调用方法
设置参数来确保主键自增

第一个是mysql的列名,第二个是实体类的值字段
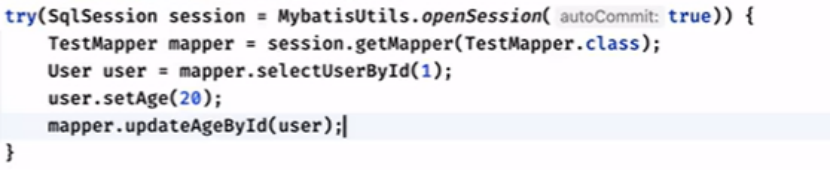
update操作

传多个参的3个方法:
在testmapper去配置即可
1,@param
2,Map
3,实体类
delete操作:

然后使用mapper去调用即可
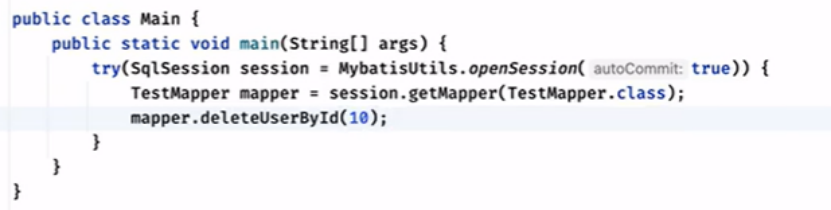
Sixth:::事务模式:
这个是在factory的时候去定义的

这里的autocommit是自动提交,如果改为了false就不会自动提交,要手动提交,也就是事务模式
事务下的一些操作:
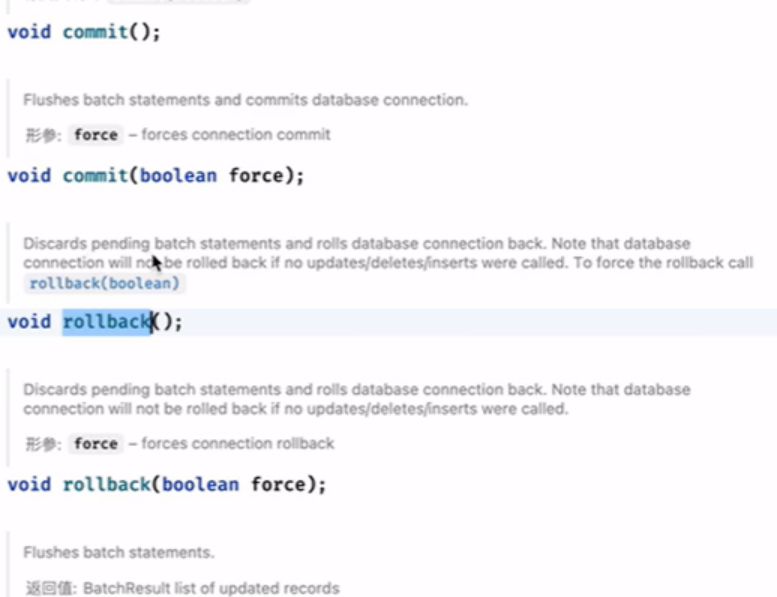
如下操作就会提交:
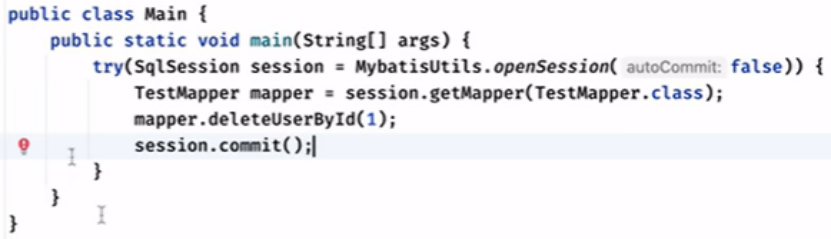
如果没有任何的DML操作,commit不会提交的
Seventh:::批处理:

BATCH

正常的插入:
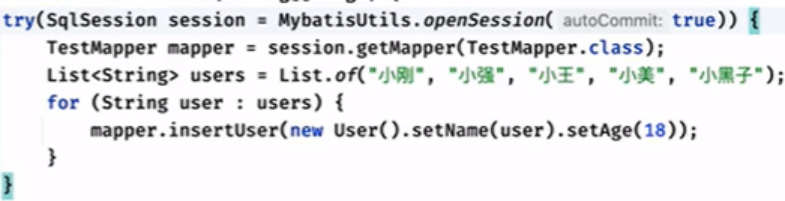
会
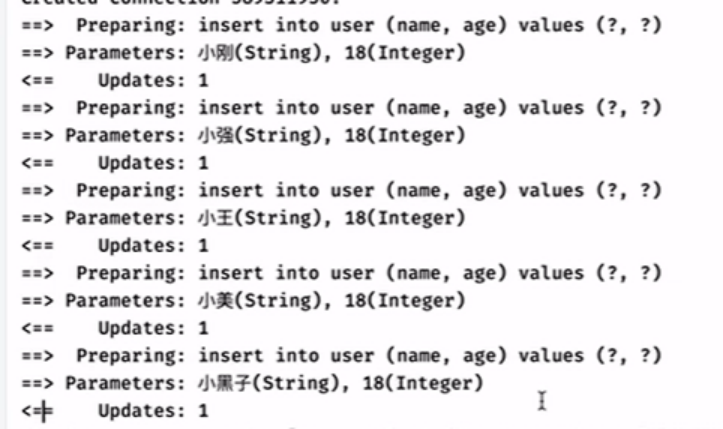
一次插入一次会话,
开启批处理后:
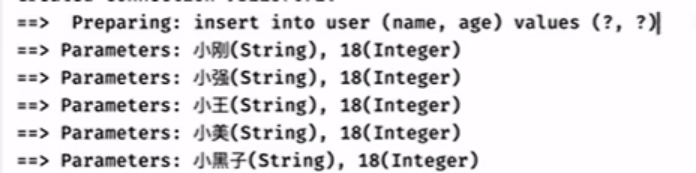
一次会话5个参数,
但是没有提交,需要手动调用session.flushStatements()去提交(也可以commit
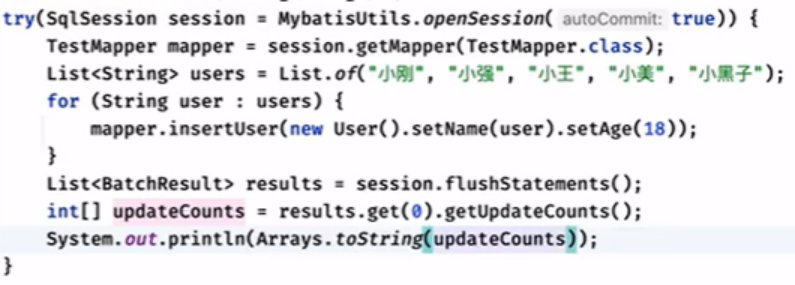
返回的结果可以如上的形式转换为数组
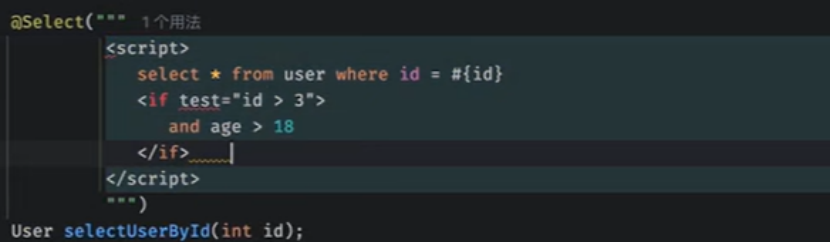
Eighth::::动态sql:
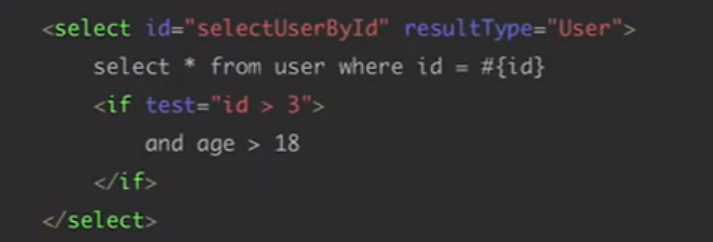
if:
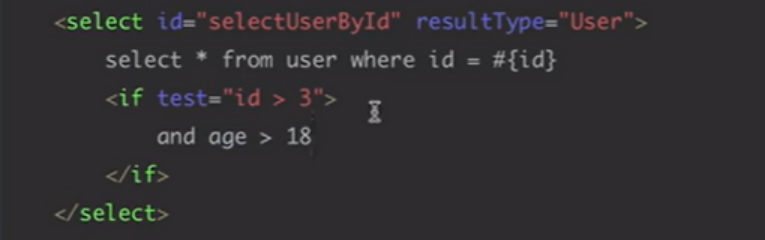
如果id大于3,那么就会加入下面的语句
否则就只有上面的语句
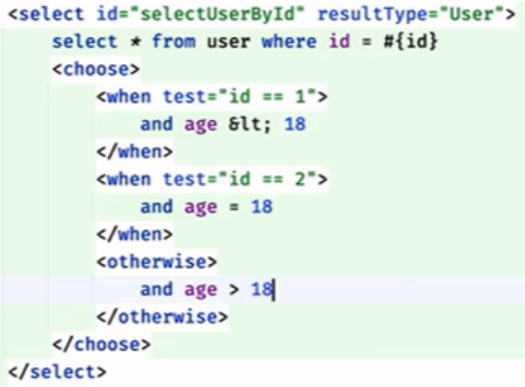
choose -when - otherwise:
这里的when不允许有>,<,>=,<=这些模糊匹配的
foreach:
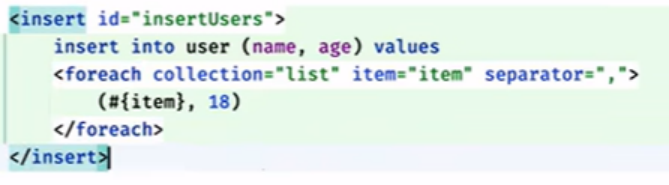
实现的是insert into user (name,age ) values(name1,age1),(name2,age2).....
传入要删除的id数组即可

ninth:::缓存机制:
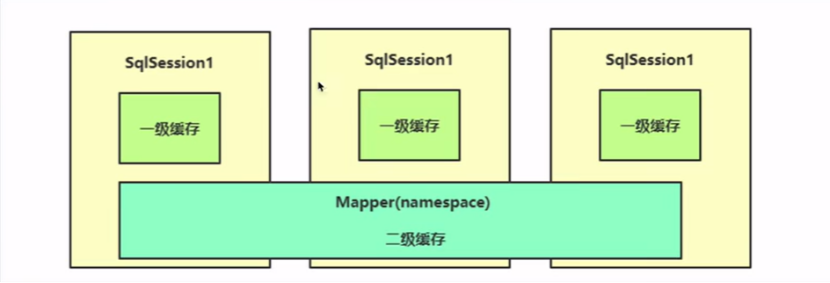
没有给sqlsession都有一个本地缓存,
不同session的缓存不会互通的
二级缓存一般不会启用的
查询+修改+查询 会清楚第一个缓存的,进行第二次查询
开启二级缓存(默认是事务性的):
<cache/>在mybatis-config.xml去配置
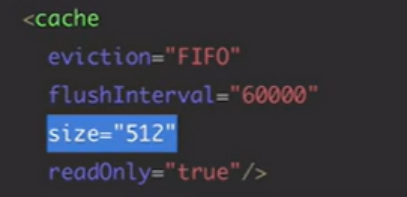
size表示cache的数量大小
eviction表示清理策略:
FIFO-先进先出
LRU-最近最少使用
SOFT-软引用,基于垃圾回收器状态和软引用规则来移除对象
WEAk-弱引用:更积极的SOFT
flushInterval:缓存刷新时间,用于定期清理
readOnly:只读,直接返回不可修改的对象,如果是可读写的就会返回一个拷贝
只有session提交过后,才会提交二级缓存.sessiong米有commit就不会命中
优先二级缓存->一级缓存->数据库
如果你想对部分语句不进行cahce操作,如下配置:

还有一个flushcache,让每次查询后都会清理掉cache和自己的本地缓存
需要自己去保证数据一致性的问题:
redis,memcache去解决一致性问题
可以使用这个关闭二级缓存

tenth::::全注解开发:
删除配置文件mapper.xml
对应的mybatis-config.xml也需要去改改

mapper类直接使用:
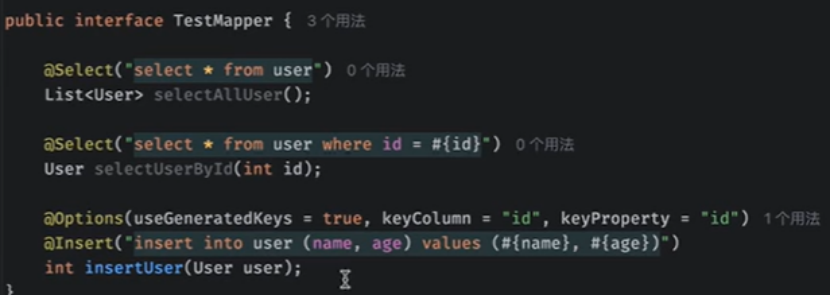
注解去些即可
@results 就是resultMap
(解决实体类和数据库字段不同:
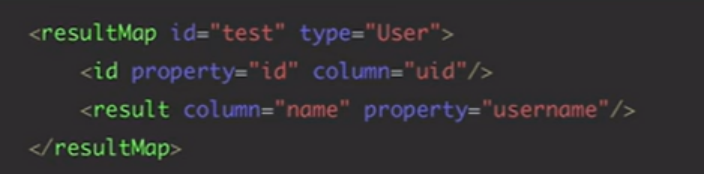
换成下面
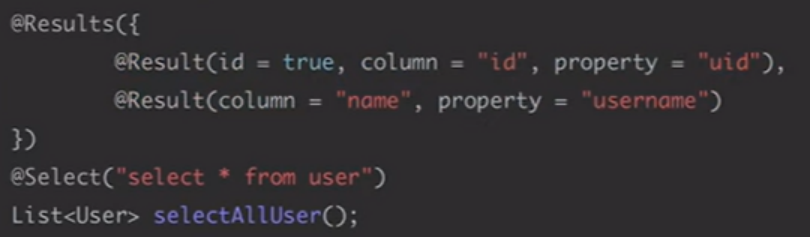
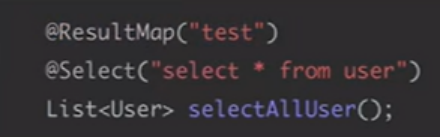
也可以混着来:
些mapper.xml的resultMap,然后如下使用
constructor标签:

换成如下
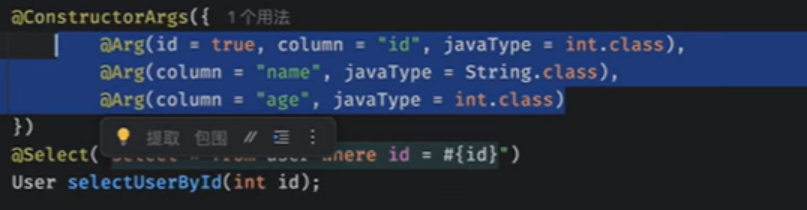
分步查询(只能第二个,不支持第一种的复杂的查询):
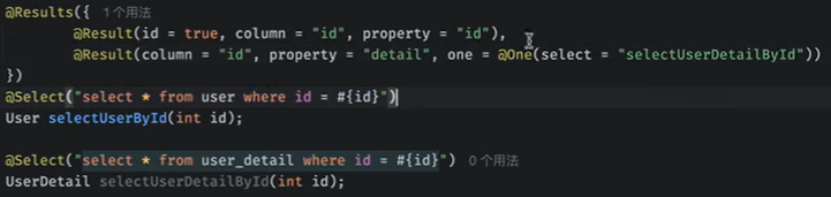
这里的one表示一对一
还可以一对多many=@Many(select =”xxx”)
动态sql:
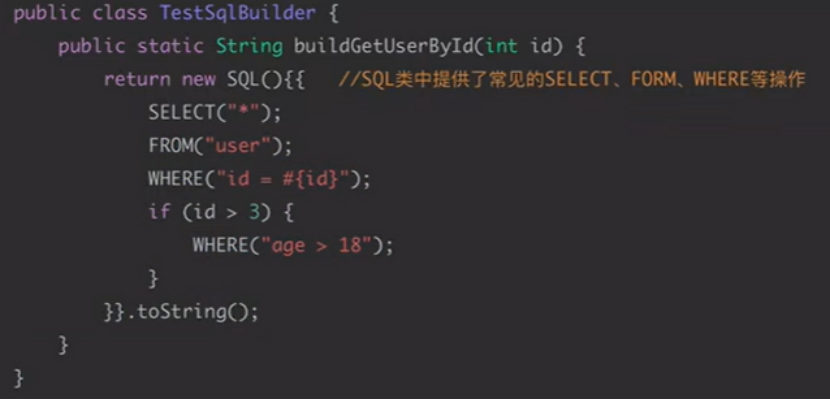
使用:

使用method的方法类
也可以:
二级缓存:
@cacheNamespace ()里面可以配置之前的配置
可以@option 去用之前的配置