BERT+CRF模型在命名实体识别(NER)任务中的应用
BERT+CRF模型在命名实体识别(NER)任务中的应用详解
一、命名实体识别(NER)任务概述
命名实体识别(Named Entity Recognition, NER)是自然语言处理中的一项基础性任务,旨在从非结构化文本中识别出具有特定意义的实体,并将其分类到预定义的类别中(如人名、地名、组织机构名等)。
NER任务的典型应用场景包括:
- 信息抽取系统的基础组件
- 知识图谱构建的前期工作
- 问答系统中的实体识别模块
- 机器翻译中的专有名词处理
传统的NER方法主要基于规则和统计机器学习,而近年来深度学习尤其是预训练语言模型(BERT)与条件随机场(CRF)的结合已成为NER任务的state-of-the-art解决方案。
二、BERT模型的核心原理与特点
2.1 Transformer架构解析
BERT(Bidirectional Encoder Representations from Transformers)的核心是基于Transformer的编码器结构,其主要特点包括:
- 多头注意力机制:允许模型同时关注输入序列的不同位置,捕获丰富的上下文信息
- 每个注意力头学习不同的关注模式
- 注意力权重动态计算,不依赖固定位置
- 位置编码:通过正弦函数生成的固定编码或可学习的位置嵌入,为模型提供序列位置信息
- 解决了传统RNN无法并行计算的瓶颈
- 能够处理长距离依赖关系
- 层归一化和残差连接:每层输出=LayerNorm(x+SubLayer(x)),有效缓解深度网络的梯度消失问题
2.2 BERT的预训练策略
BERT通过两种无监督预训练任务学习通用语言表示:
- 掩码语言模型(MLM):
- 随机掩盖输入token的15%,预测被掩盖的词
- 其中80%替换为[MASK],10%随机替换,10%保持不变
- 迫使模型理解双向上下文
- 下一句预测(NSP):
- 判断两个句子是否为连续文本
- 增强模型理解句子间关系的能力
2.3 BERT在NER任务中的优势
- 上下文感知:双向Transformer结构可捕获丰富的上下文信息
- 迁移学习能力:预训练+微调范式显著降低对标注数据量的需求
- 词义消歧:能够根据上下文区分同一词的不同含义(如"苹果"公司vs水果)
- 子词处理:WordPiece分词有效解决OOV(未登录词)问题
三、条件随机场(CRF)模型详解
3.1 CRF的基本概念
条件随机场是一种判别式概率图模型,特别适合处理序列标注问题:
- 模型形式:定义在观测序列X和标记序列Y上的条件概率分布P(Y|X)
- 马尔可夫性:当前状态仅依赖相邻状态,与更远状态条件独立
- 全局归一化:相比逐点预测,CRF考虑整个序列的联合概率
3.2 线性链CRF的数学表示
对于输入序列x=(x₁,…,xₙ)和标签序列y=(y₁,…,yₙ),线性链CRF定义:
P(y|x) = (1/Z(x)) * exp(∑ᵢ[∑ₖλₖfₖ(yᵢ₋₁,yᵢ,x,i)] + ∑ᵢ[∑ₗμₗgₗ(yᵢ,x,i)])
其中:
- fₖ为转移特征函数,捕捉标签间转移规律
- gₗ为状态特征函数,捕捉标签与观测的关联
- λₖ,μₗ为可学习参数
- Z(x)为归一化因子,确保概率和为1
3.3 CRF在NER中的关键作用
- 标签约束建模:通过学习合法的标签转移模式(如"I-PER"不能跟在"O"后面)
- 全局最优解码:维特比算法可找到概率最大的整体标签序列
- 解决标签不平衡:CRF损失直接优化序列级目标,而非token级
四、BERT+CRF联合模型架构
4.1 整体模型结构
BERT+CRF模型通常包含三个主要组件:
-
BERT编码层:将输入文本转换为上下文相关的token嵌入
-
线性投影层:将BERT输出维度映射到标签空间
-
CRF解码层:建模标签间依赖关系并进行全局解码
[Input Text] → [BERT Encoder] → [Linear Projection] → [CRF Layer] → [Predicted Tags]
4.2 具体实现细节
4.2.1 输入表示处理
- 子词分词:使用BERT的WordPiece分词器处理原始文本
- 解决OOV问题(如"unaffordable"→"un","##aff","##ordable")
- 需注意子词对齐问题(一个词可能分成多个子词)
- 特殊token处理:
- [CLS]和[SEP]分别表示序列开始/结束
- 实际NER任务中通常不使用[CLS]的输出
- 位置嵌入:BERT自动添加的位置信息帮助模型理解token顺序
4.2.2 BERT输出处理
- 序列提取:通常取最后一层或最后几层平均的token表示
- 子词聚合:对属于同一原始词的子词表示进行平均或取首子词
- 维度变换:通过全连接层将BERT输出(hidden_size)投影到标签空间(num_tags)
4.2.3 CRF参数学习
- 转移矩阵初始化:
- 可随机初始化
- 也可用标注数据统计初始化(更优起点)
- 损失函数:
- 负对数似然:-log P(y|x)
- 包含两项:真实路径分数与所有可能路径的logsumexp
- 正则化:通常添加L2正则防止过拟合
4.3 训练技巧与优化
-
分层学习率:
- BERT底层参数使用较小学习率(如2e-5)
- 顶层CRF参数使用较大学习率(如1e-3)
-
梯度裁剪:防止梯度爆炸,通常设置max_grad_norm=1.0
-
早停机制:基于验证集性能停止训练,防止过拟合
-
标签平滑:缓解标注噪声问题,提高模型鲁棒性
五、关键实现步骤与代码示例
5.1 数据准备与预处理
-
标注格式转换:通常使用BIO或BIOES标注体系
- BIO: B-实体开始,I-实体内部,O-非实体
- BIOES: 增加E(实体结束)和S(单字实体)
-
数据集划分:按比例(如8:1:1)分为训练/验证/测试集
-
DataLoader构建:
- 需处理不等长序列(padding)
- 注意attention mask(忽略padding位置)
5.2 模型定义(PyTorch示例)
import torch
import torch.nn as nn
from transformers import BertModel
from torchcrf import CRF class BERT_CRF_NER(nn.Module):def __init__(self, bert_model, num_tags):super().__init__()self.bert = BertModel.from_pretrained(bert_model) self.dropout = nn.Dropout(0.1)self.classifier = nn.Linear(self.bert.config.hidden_size, num_tags)self.crf = CRF(num_tags, batch_first=True)def forward(self, input_ids, attention_mask, labels=None):outputs = self.bert(input_ids, attention_mask=attention_mask)sequence_output = outputs[0]sequence_output = self.dropout(sequence_output) emissions = self.classifier(sequence_output) if labels is not None:loss = -self.crf(emissions, labels, mask=attention_mask.byte()) return loss else:return self.crf.decode(emissions, mask=attention_mask.byte())
5.3 训练循环关键步骤
- 前向传播:获取BERT输出和CRF发射分数
- 损失计算:CRF负对数似然损失
- 反向传播:计算梯度并更新参数
- 解码预测:使用维特比算法找到最优标签序列
5.4 评估指标
- 精确率/召回率/F1值:基于实体级别而非token级别
- 混淆矩阵分析:识别常见错误类型(如实体边界错误)
- 推理速度:每秒处理的token数量
六、实际应用中的挑战与解决方案
6.1 领域适应问题
- 领域自适应预训练:在目标领域数据上继续预训练BERT
- 多任务学习:联合训练NER与相关任务(如词性标注)
- 对抗训练:引入领域鉴别器,学习领域不变特征
6.2 标签不平衡问题
- 焦点损失(Focal Loss):降低易分类样本的权重
- 采样策略:过采样少数类或欠采样多数类
- 代价敏感学习:为不同类别设置不同的误分类代价
6.3 长文本处理
- 滑动窗口:将长文本分割为重叠的短片段
- 层次化模型:先分段处理,再整合全局信息
- 内存高效注意力:使用稀疏注意力或分块注意力机制
七、进阶优化方向
7.1 模型结构改进
- BERT变体选择:
- RoBERTa: 更鲁棒的预训练策略
- ALBERT: 参数共享,更轻量级
- ELECTRA: 替换token检测任务,样本效率更高
- 层级CRF:
- 浅层CRF处理基础标签(如BIO)
- 深层CRF处理细粒度类型(如人物/地点)
- 图神经网络增强:引入语法依存树等结构化信息
7.2 预训练策略优化
- 任务自适应预训练:
- 实体遮盖策略(如遮盖完整实体而非随机token)
- 实体边界预测辅助任务
- 知识增强:
- 注入实体知识(如实体描述)
- 联合训练实体链接任务
7.3 半监督与主动学习
- 一致性训练:对未标注数据添加扰动,强制预测一致
- 伪标签:用现有模型标注未标注数据,扩充训练集
- 主动学习:优先标注模型最不确定的样本
核心技术总结
下表总结了BERT+CRF模型在NER任务中涉及的核心技术:
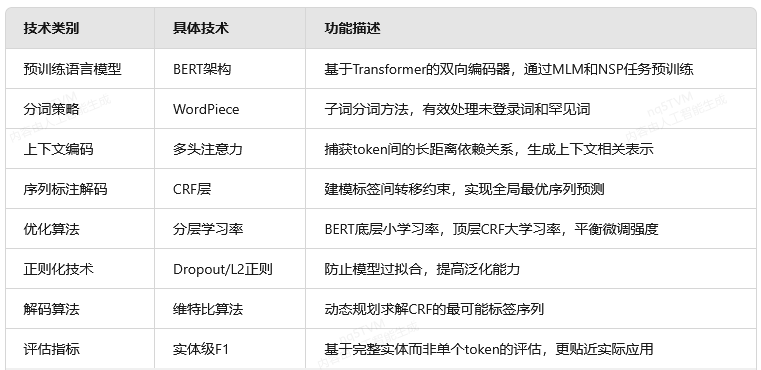
CRF在NER任务中的核心机制详解
一、基本框架与角色定义
1. 隐含状态与可观测状态
- 隐含状态:对应NER中的标签序列,如
B-PER,I-LOC等。每个token的标签是待预测的离散变量 - 可观测状态:对应输入文本的token序列,如句子"John lives in Paris"中的每个词
2. 核心参数矩阵
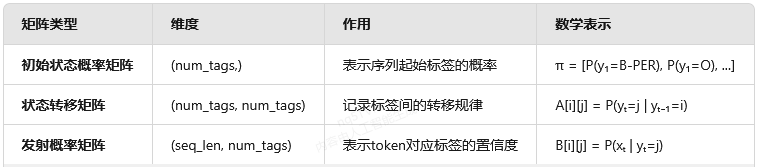
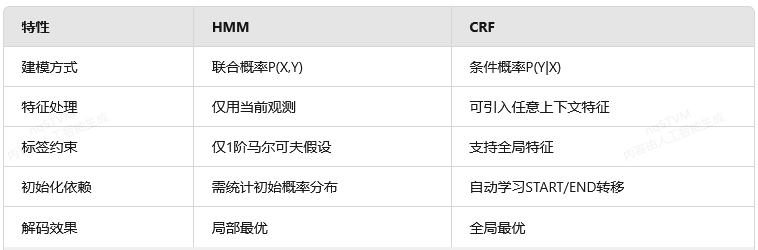
二、HMM与CRF的对比建模
1. HMM的生成式建模
HMM通过联合概率分解建模序列关系:
P(X,Y) = P(y₁)∏ₜ P(yₜ|yₜ₋₁)P(xₜ|yₜ)
- 参数学习:通过统计语料中的频次估计π、A、B矩阵
2. CRF的判别式建模
CRF直接定义条件概率分布:
P(Y|X) = (1/Z(X))exp(∑λₖfₖ(yₜ₋₁,yₜ,x)+∑μₗgₗ(yₜ,x))
- 特征函数:fₖ捕捉标签转移规律,gₗ捕捉标签与观测的关联
三、CRF的矩阵计算细节
1. 发射矩阵(Emission Matrix)
- 生成方式:BERT输出的每个token向量经过线性层得到标签得分
- 数学形式:
B[i][j] = W⋅h_i + b
其中h_i是第i个token的BERT编码,W∈ℝ^(d×K),K为标签数量
2. 状态转移矩阵(Transition Matrix)
- 学习目标:捕捉合法标签转移模式,例如:
A[B-PER][I-PER] = 1.2(正向激励)A[I-PER][B-LOC] = -∞(绝对禁止)
- 初始化策略:可用训练集的转移统计初始化
3. 路径分数计算
对于标签序列Y=(y₁,…,yₙ),其分数计算包含:
score(Y,X) = ∑(B[i][y_i]) + ∑A[y_{i-1}][y_i] + A[START][y₁] + A[yₙ][END]
四、动态规划与最优解码
1. 维特比算法流程
-
前向传播:记录每个位置的最大分数和路径指针
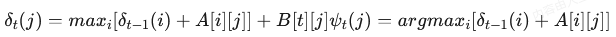
-
回溯路径:从终结点反向追踪最优路径
2. 解码示例
假设标签集为{B-PER, I-PER, O},某时刻计算:
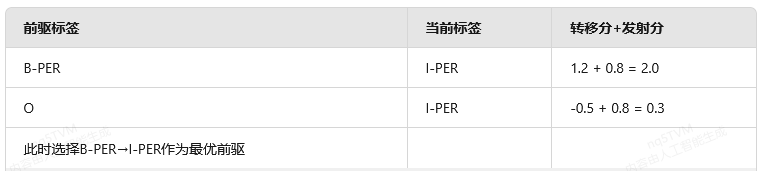
五、与HMM的关键差异
六、特殊状态处理技巧
- START/END标签:扩展转移矩阵维度(num_tags+2, num_tags+2)
- 非法转移处理:初始化时设置-1e4等极大负值
- 长程依赖建模:通过高阶CRF或引入句法特征增强
应用实例:在"John lives in New York"中,CRF可能给出:
John/B-PER lives/O in/O New/B-LOC York/I-LOC
此时转移矩阵确保了:
- B-LOC后只能接I-LOC/O
- B-PER后不能直接接B-LOC
通过这种显式的状态转移约束,CRF有效解决了BiLSTM等模型可能产生的非法标签序列问题。