RAG工程-基于LangChain 实现 Advanced RAG(预检索-查询优化)(上)
Enrich 完善问题
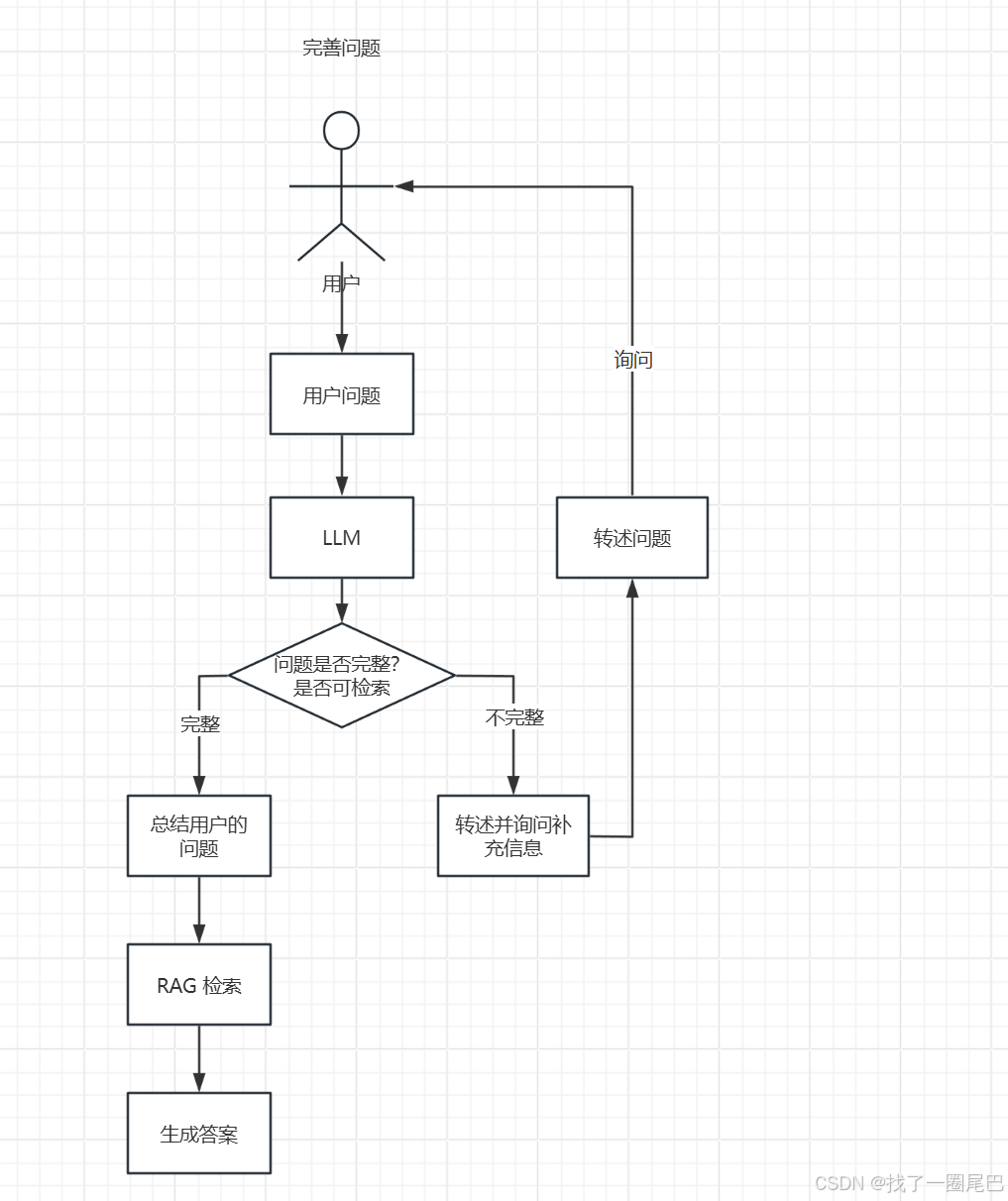
完善问题流程概述
问题转述
在典型RAG架构中,用户问题的质量直接影响检索系统的表现。研究表明,未经优化的自然语言查询会导致:
-
关键实体识别缺失
-
语义漂移导致召回偏离
-
长尾问题检索失败率升高
大多数用户并非提示词工程专家,其提出的问题往往存在模糊、冗余或缺乏关键背景信息等问题。为了提升检索效果,在 Advanced RAG 预检索查询场景下,问题转述成为优化问题质量的关键手段。下面我将详细介绍问题转述的三种核心优化方式,并结合 langchain 框架给出具体的代码实现。
明确核心问题,去除冗余内容
用户提出的问题可能包含大量与核心诉求无关的描述,这些冗余信息会干扰检索的准确性。例如,用户询问 “我前几天在网上看到一款特别酷炫的笔记本电脑,它有着超级好看的外观,还有特别厉害的性能,我现在特别想知道它到底怎么样”,其中 “特别酷炫”“超级好看的外观”“特别厉害的性能” 等修饰性表述属于冗余内容。通过分析,我们可以将核心问题提取为 “这款笔记本电脑的性能怎么样”。
我们可以通过LLM识别并保留核心语义单元,过滤这些干扰性描述。以下是基于LangChain 框架的代码示例:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplatesimplify_prompt = PromptTemplate(input_variables=["query"],template="""请从以下问题中提取核心问题(保留实体和动作):原始问题:{query}精简后问题:"""
)simplify_chain = LLMChain(llm=llm, prompt=simplify_prompt)
optimized_query = simplify_chain.run("我前几天在网上看到一款特别酷炫的笔记本电脑,它有着超级好看的外观,还有特别厉害的性能,我现在特别想知道它到底怎么样?")# 输出:"这款笔记本电脑的性能怎么样"我们直接使用提示词的方式,对问题进行精简,以保留核心语义。也可以使用LangChain 的RePhraseQueryRetriever 方法,重写用户查询以优化检索效果。
'''
You are an assistant tasked with taking a natural language \
query from a user and converting it into a query for a vectorstore. \
In this process, you strip out information that is not relevant for \
the retrieval task. Here is the user query: {question}你是一名负责从用户那里获取自然语言查询并将其转换为向量库查询的助手。在此过程中,你将删除与检索任务无关的信息。
以下是用户查询:{question}
'''
# retriever = RePhraseQueryRetriever.from_llm(retriever, llm)在systemPrompt 补充背景信息
为了让大模型更准确地理解用户意图,给出符合需求的回答,需要在 systemPrompt 中补充必要的背景信息。例如,用户提问 “这个方案可行吗”,由于缺乏具体的方案内容和应用场景,大模型难以给出准确回答。此时,我们可以在 systemPrompt 中补充背景信息,将问题转述为 “在当前预算有限且时间紧迫的情况下,针对某电商平台用户增长的营销方案可行吗”。
补充背景信息时,要围绕问题核心,根据领域特征自动补充查询条件。并结合用户可能的使用场景和需求,提供足够的上下文,帮助大模型明确回答问题的方向。
以下是LangChain 框架的代码示例:
context_enrich_prompt = PromptTemplate(input_variables=["query"],template="""作为医疗领域专家,请为以下问题补充必要限定条件:1. 时间范围(近3年)2. 研究类型(临床验证)3. 数据来源(权威期刊)原始问题:{query}优化后问题:"""
)enrich_chain = LLMChain(llm=llm, prompt=context_enrich_prompt)
enriched_query = enrich_chain.run("CT图像识别技术现状")# 输出:"2020-2023年基于深度学习的CT图像识别技术在临床验证中的最新进展(来源:Nature、Science子刊)"通过用户问题生成多个转述问题
生成多个相关的转述问题,可以从不同角度覆盖用户需求,提高检索到相关内容的概率。在生成转述问题时,需要保持与原始问题的语义一致性,同时通过调整表述方式、变换提问角度等方法,生成多样化的问题表述。
我们依旧选用LangChain 框架的RePhraseQueryRetriever方法,它可以很方便的创建多个转述问题,以下是具体的LangChain 框架代码示例:
from langchain.retrievers import RePhraseQueryRetrieverrephrase_prompt = """请生成3个不同视角的问题表述:
要求:
1. 保持核心实体不变
2. 使用不同句式结构
3. 包含抽象化和具体化两种形式输入:{query}
输出:"""base_retriever = vectorstore.as_retriever()
enhanced_retriever = RePhraseQueryRetriever.from_llm(retriever=base_retriever,llm=llm,prompt_template=rephrase_prompt,num_phrases=3
)多轮会话交互
多轮会话交互基于自然语言处理和对话管理技术,系统在接收到用户的初始问题后,会分析问题中的关键信息和缺失部分,主动向用户提问,引导用户补充信息。每一轮对话中,系统会根据用户的回答更新对问题的理解,并决定下一轮提问的方向,直到获取足够的信息来完善问题。
多轮会话交互的实现流程
-
问题分析与意图识别:系统接收到用户问题后,利用自然语言处理技术,如分词、词性标注、命名实体识别、语义分析等,提取问题中的关键信息,并尝试识别用户意图。
-
确定缺失信息与生成提问:根据问题分析结果,确定需要补充的关键信息,结合业务场景和常见问题模式,生成针对性的提问。
-
对话管理与交互推进:管理多轮对话的流程和状态,记录用户的每一轮回答,并根据回答内容调整后续提问策略。
-
问题完善与结束判断:当系统认为获取到的信息足以清晰界定问题,或达到预设的对话轮数上限时,结束对话,并将用户的原始问题与补充信息整合,生成完善后的问题。
基于LangChain 框架的代码示例
from typing import Dict, List, Any
from dotenv import load_dotenv
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory# 假设已实现的LLM配置和历史管理模块
from llm import llmConfig # 需要实际实现
from llm.llmHistory import get_session_history # 需要实际实现# 加载环境变量(需包含LLM连接配置)
load_dotenv()class IntentRecognizer:def __init__(self):# 初始化LLMself.llm = llmConfig.getCommonLLM()# 配置JSON解析器self.parser = JsonOutputParser()# 构建对话链self.prompt = ChatPromptTemplate.from_messages([("system", "你是一个信息补充助手,任务是分析用户问题是否完整,并根据模板提取关键信息。"),MessagesPlaceholder(variable_name="chat_history"),("human", "{input}")])self.chain = self.prompt | self.llm# 配置带历史记录的链self.chain_with_history = RunnableWithMessageHistory(self.chain,get_session_history=get_session_history,input_messages_key="input",history_messages_key="chat_history")def recognize_intent(self,user_input: str,selected_template: List[str],session_id: str = "default") -> Dict[str, Any]:"""完整可调用的意图识别方法参数示例:>>> recognizer = IntentRecognizer()>>> result = recognizer.recognize_intent("我想了解治疗方案",["疾病名称", "患者年龄", "症状描述"])"""try:# 构建信息补充提示info_prompt = f"""请根据用户原始问题和模板,判断原始问题是否完善。如果问题缺乏需要的信息,请生成一个友好的请求,明确指出需要补充的信息。若问题完善后,返回包含所有信息的完整问题。### 原始问题 {user_input}### 模板字段{",".join(selected_template)} ### 输出格式{{"isComplete": true,"content": "完整问题内容","extracted_info": {{"字段1": "对应值","字段2": "对应值"}}}}或{{"isComplete": false,"content": "友好的引导需要补充的信息","missing_fields": ["缺失字段"]}} """# 第一轮调用response = self.chain_with_history.invoke(input={"input": info_prompt},config={"configurable": {"session_id": session_id}}).content# 解析响应try:json_data = self.parser.parse(response)except Exception as e:return self._handle_parse_error(e)# 处理完整问题的情况if json_data.get("isComplete"):return self._handle_complete_case(json_data, selected_template, session_id)# 处理不完整问题的情况return self._validate_incomplete_response(json_data, selected_template)except Exception as e:return self._handle_general_error(e)def _handle_complete_case(self, data: Dict, template: List[str], session_id: str) -> Dict:"""处理完整问题的结构化提取"""extraction_prompt = f"""请从以下完整问题中提取关键信息:### 完整问题{data['content']}### 模板字段{",".join(template)}### 输出格式{{"extracted_info": {{"{template[0]}": "值","{template[1]}": "值"}}}}"""try:extraction_response = self.chain_with_history.invoke(input={"input": extraction_prompt},config={"configurable": {"session_id": session_id}}).contentextraction_data = self.parser.parse(extraction_response)if "extracted_info" in extraction_data:data["extracted_info"] = extraction_data["extracted_info"]return datareturn {"isComplete": False,"content": "信息提取失败,请重新描述问题","error": "extraction_failed"}except Exception as e:return self._handle_parse_error(e)def _validate_incomplete_response(self, data: Dict, template: List[str]) -> Dict:"""验证不完整响应格式"""required_keys = ["isComplete", "content", "missing_fields"]if not all(k in data for k in required_keys):return {"isComplete": False,"content": "响应格式异常,请重新尝试","error": "invalid_format"}# 验证缺失字段是否在模板范围内invalid_fields = [f for f in data["missing_fields"] if f not in template]if invalid_fields:return {"isComplete": False,"content": "检测到无效字段请求","error": f"invalid_fields: {invalid_fields}"}return datadef _handle_parse_error(self, error: Exception) -> Dict:"""处理解析错误"""print(f"JSON解析错误: {str(error)}")return {"isComplete": False,"content": "解析响应时出错,请尝试重新提问","error": f"parse_error: {str(error)}"}def _handle_general_error(self, error: Exception) -> Dict:"""处理通用错误"""print(f"系统错误: {str(error)}")return {"isComplete": False,"content": "处理请求时发生系统错误","error": f"system_error: {str(error)}"}# 使用示例
if __name__ == "__main__":recognizer = IntentRecognizer()# 测试用例1:完整问题case1 = recognizer.recognize_intent("我想了解糖尿病患者的胰岛素治疗方案(患者年龄65岁,病程10年)",["疾病名称", "患者年龄", "症状描述"])print("测试用例1结果:", case1)# 测试用例2:不完整问题case2 = recognizer.recognize_intent("关于心脏病的治疗",["疾病类型", "患者年龄", "症状表现"])print("测试用例2结果:", case2)# 测试用例3:错误格式输入case3 = recognizer.recognize_intent("我想预约挂号",["科室名称", "预约时间"])print("测试用例3结果:", case3)实现多轮会话包含一些必要组件,首先是RunnableWithMessageHistory,作为对话历史管理的核心载体,通过记录每一轮用户输入与模型回复,为 LLM 构建起完整的上下文语境。这样LLM才能基于上下文,识别用户是否补充了完整信息。第二个必要组件就是一个引导LLM 进行多轮会话的提示词模板,精心设计的提示词模板是规范 LLM 输出的 “导航仪”。它通过明确的指令框架,约束模型的回复方向,确保对话沿着既定目标推进,以保证整体输出内容的正确性。
元数据模板
元数据模板是一种预先定义好的结构化框架,它包含了与问题相关的各类属性和字段。在用户提出问题后,系统依据元数据模板,引导用户补充或自动提取问题相关的关键信息,如问题的主题、涉及对象、应用场景、时间范围、约束条件等。这些结构化的元数据能够帮助系统更精准地理解问题背景和用户意图,避免因信息缺失或模糊导致的检索偏差。
以下是一段采用引导用户补充元数据的方式,以获取标准元数据模板的代码示例:
import json
# 定义元数据模板
metadata_template = {"question_topic": "","product_name": "","problem_phenomenon": "","operation_environment": "","impact_scope": "","urgency": ""
}
# 模拟用户输入问题
original_question = "电脑无法开机"
# 引导用户补充元数据信息
print("请根据以下模板补充问题相关信息:")
for key in metadata_template.keys():metadata_template[key] = input(f"{key}: ")
# 整合原始问题和元数据信息
completed_question = f"{original_question}。问题主题:{metadata_template['question_topic']},产品名称:{metadata_template['product_name']},问题现象:{metadata_template['problem_phenomenon']},操作环境:{metadata_template['operation_environment']},影响范围:{metadata_template['impact_scope']},紧急程度:{metadata_template['urgency']}"
print("完善后的问题:", completed_question)意图分析
意图分析是指通过对用户输入的文本信息进行理解和处理,识别用户话语背后真正的目的和需求。在 RAG 系统中,用户的初始提问往往模糊、隐晦,如 “帮我看看”,若不进行意图分析,系统难以理解用户具体想解决什么问题。准确的意图分析能让系统明确用户是想查询信息、寻求解决方案,还是进行其他操作,进而确定后续对话策略,引导用户完善问题,避免无效沟通,提高交互效率。
意图分析的实现流程
-
数据预处理:对用户输入的文本进行清洗,去除噪声,如特殊字符、停用词;进行分词处理,将文本拆分成词语;有时还需要进行词性标注、词形还原等操作,以便后续的特征提取和分析。
-
特征提取:根据所选的分析方法,提取文本的特征。基于规则时,提取关键词等特征;基于机器学习时,使用词向量(如 Word2Vec、GloVe)、TF-IDF 值等作为特征;基于深度学习时,模型自动学习文本的分布式表示作为特征 。
-
意图识别与分类:将提取的特征输入到训练好的模型(规则引擎或机器学习 / 深度学习模型)中,判断用户意图所属的类别。
-
意图修正与细化:在多轮对话过程中,根据用户后续的回答和上下文信息,对初始识别的意图进行修正和细化。
基于语料库对问题进行意图分析
我们可以采用自然语言处理库,如 NLTK、spaCy 或基于深度学习框架(如 TensorFlow、PyTorch)搭建的自定义模型,对用户输入文本进行深度处理。以使用 spaCy 库为例,可通过以下代码实现基础的意图分析:
import spacynlp = spacy.load("en_core_web_sm")def analyze_intent(text):doc = nlp(text)# 定义关键词匹配规则和语义分析逻辑for token in doc:if token.text in ["relax", "rest"]:return "休闲度假"return "未明确"在实际的意图分析过程中,为提高准确性,还可结合预训练的语言模型,如 BERT、GPT 系列等,通过微调模型适应特定领域的意图识别任务。将用户输入的文本转化为向量表示,输入到微调后的模型中,模型输出对用户意图的预测结果,从而更精准地把握用户真实需求。
使用朴素贝叶斯构建意图分类模型
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline# 示例训练数据,包含问题文本和对应的意图标签
train_data = [("如何安装软件", "软件安装"),("软件打开后闪退", "软件故障"),("推荐一款手机", "产品推荐"),("手机电池不耐用", "手机故障")
]
texts, intents = zip(*train_data)# 创建文本分类管道,包含TF-IDF特征提取和朴素贝叶斯分类器
pipeline = Pipeline([('vectorizer', TfidfVectorizer()),('classifier', MultinomialNB())
])# 训练模型
pipeline.fit(texts, intents)# 示例用户输入
user_input = "软件运行时很卡顿"
# 预测意图
predicted_intent = pipeline.predict([user_input])[0]
print("预测的用户意图:", predicted_intent)上述代码使用朴素贝叶斯算法构建了一个简单的意图分类模型。先准备训练数据,然后通过Pipeline将 TF-IDF 特征提取和朴素贝叶斯分类器组合起来进行训练,最后对用户输入进行意图预测。在实际应用中,可使用更多的训练数据和更复杂的模型,以提高意图分析的准确性。