【Hice入门】Hive性能优化:存储与计算优化深度解析
目录
1 Hive性能优化概述
1.1 存储与计算的关系
2 列式存储格式深度解析
2.1 行式 vs 列式存储
2.1.1 行式存储特点
2.1.2 列式存储特点
2.2 ORC文件格式详解
2.2.1 ORC文件结构
2.2.2 ORC编码与压缩
2.3 Parquet文件格式详解
2.3.1 Parquet文件结构
2.3.2 Parquet与ORC对比
3 小文件问题与合并优化
3.1 小文件问题的影响
3.2 CombineFileInputFormat原理
3.2.1 工作流程
3.2.2 关键配置参数
3.3 小文件合并实践方案
3.3.1 自动合并方案
3.3.2 手动合并方案
4 存储优化实战案例
4.1 案例1:ORC存储优化
4.2 案例2:小文件合并
5 高级优化技巧
5.1 列裁剪与谓词下推
5.2 分区与分桶优化
6 监控与维护
6.1 存储格式监控
6.2 小文件监控脚本
6.3 自动化维护方案
7 总结
7.1 存储优化
7.2 小文件处理
7.3 性能优化
1 Hive性能优化概述
在大数据环境中,Hive作为数据仓库工具,其性能优化主要围绕存储和计算两个维度展开。存储优化关注数据如何高效地组织和存储在HDFS上,而计算优化则关注如何高效地处理这些数据。本文将深入探讨列式存储格式的优化原理和小文件合并的关键技术。
1.1 存储与计算的关系
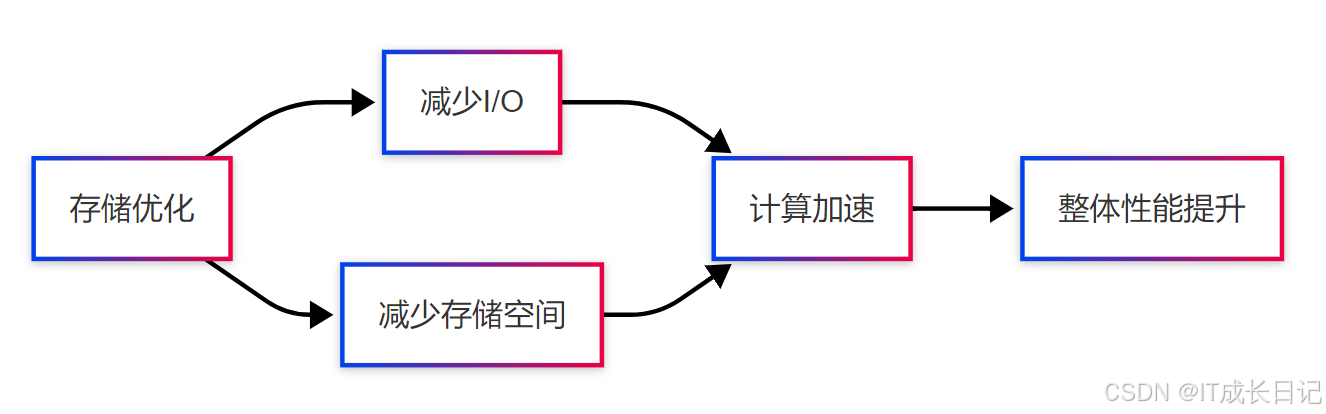
存储优化通过以下方式影响计算性能:
- 减少I/O:高效的数据格式和压缩可以减少数据读取量
- 减少存储空间:压缩技术可以降低存储成本和提高网络传输效率
- 计算下推:某些存储格式支持将计算下推到存储层执行
2 列式存储格式深度解析
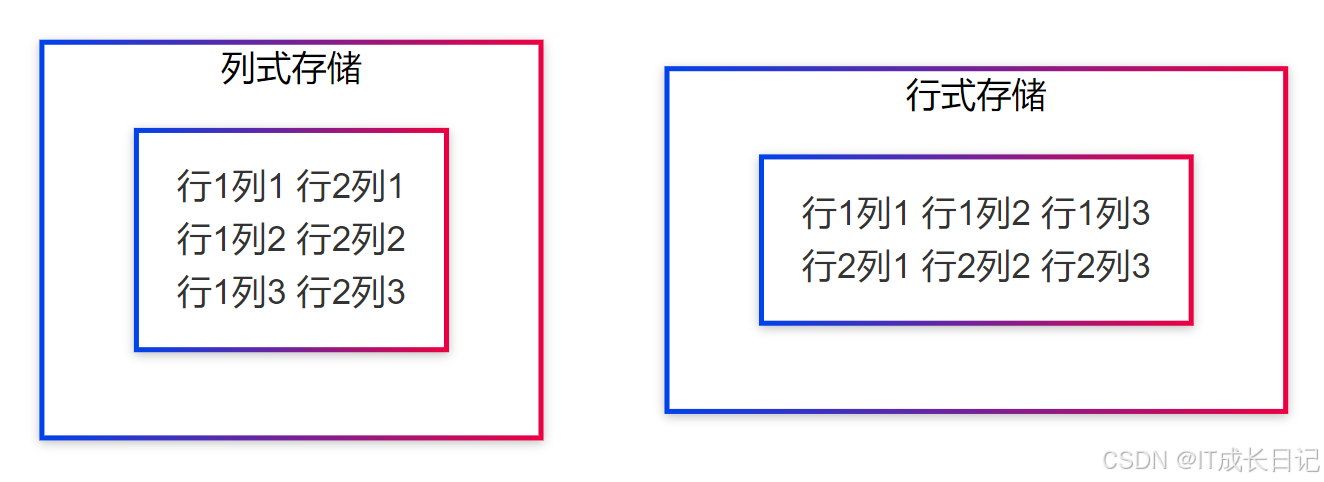
2.1 行式 vs 列式存储
2.1.1 行式存储特点
行式存储(如TextFile、SequenceFile)将一行数据连续存储,适合:
- 需要频繁整行读取的场景
- 需要写入整个行的场景
- 行数据量较小的OLTP场景
2.1.2 列式存储特点
列式存储(如ORC、Parquet)将每列数据连续存储,优势在于:
- 只读取查询需要的列
- 更好的压缩效率(同列数据类型一致)
- 支持复杂的编码和压缩方式
2.2 ORC文件格式详解
ORC(Optimized Row Columnar)是Hive原生支持的高效列式存储格式。
2.2.1 ORC文件结构
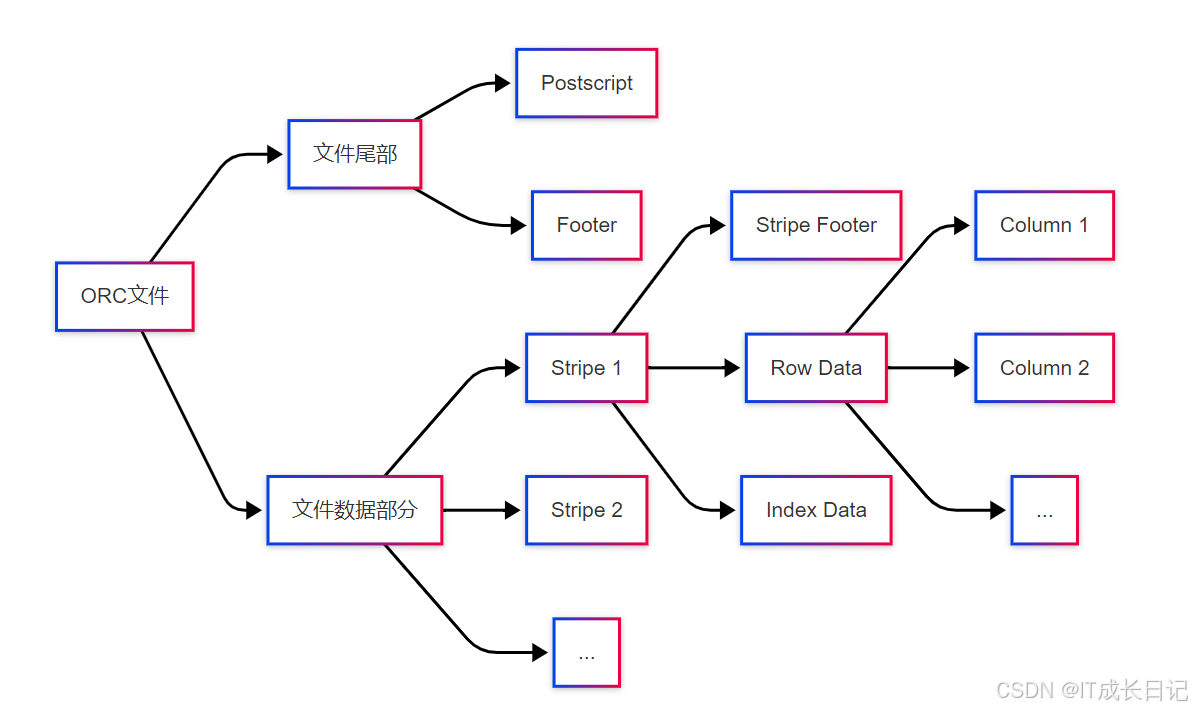
文件尾部:
- Postscript:存储压缩参数和Footer长度
- Footer:文件元数据,包括Schema、行数、各Stripe信息
Stripe结构:
- Index Data:每列的最小/最大/行位置等统计信息
- Row Data:实际列数据
- Stripe Footer:Stripe的元数据
2.2.2 ORC编码与压缩
| 编码类型 | 适用场景 | 原理 |
| Run Length Encoding(RLE) | 低基数列 | 存储值和重复次数 |
| Dictionary Encoding | 中低基数列 | 构建字典存储索引而非实际值 |
| Bit Packing | 小整数值 | 紧凑存储小整数 |
| Delta Encoding | 有序数值列 | 存储差值而非绝对值 |
- 压缩算法配置:
-- 设置ORC压缩算法
SET hive.exec.orc.compression.strategy=COMPRESSION;
SET hive.exec.orc.compression.codec=snappy;- 常用压缩算法比较:
| 算法 | 压缩比 | 速度 | CPU开销 | 适用场景 |
| NONE | 1.0x | 最快 | 最低 | 测试环境 |
| ZLIB | 高 | 慢 | 高 | 存储敏感场景 |
| SNAPPY | 中等 | 快 | 中等 | 平衡场景 |
| LZO | 中等 | 快 | 中等 | 需可切分场景 |
2.3 Parquet文件格式详解
Parquet是另一种流行的列式存储格式,与ORC相比更适合复杂嵌套数据结构。
2.3.1 Parquet文件结构
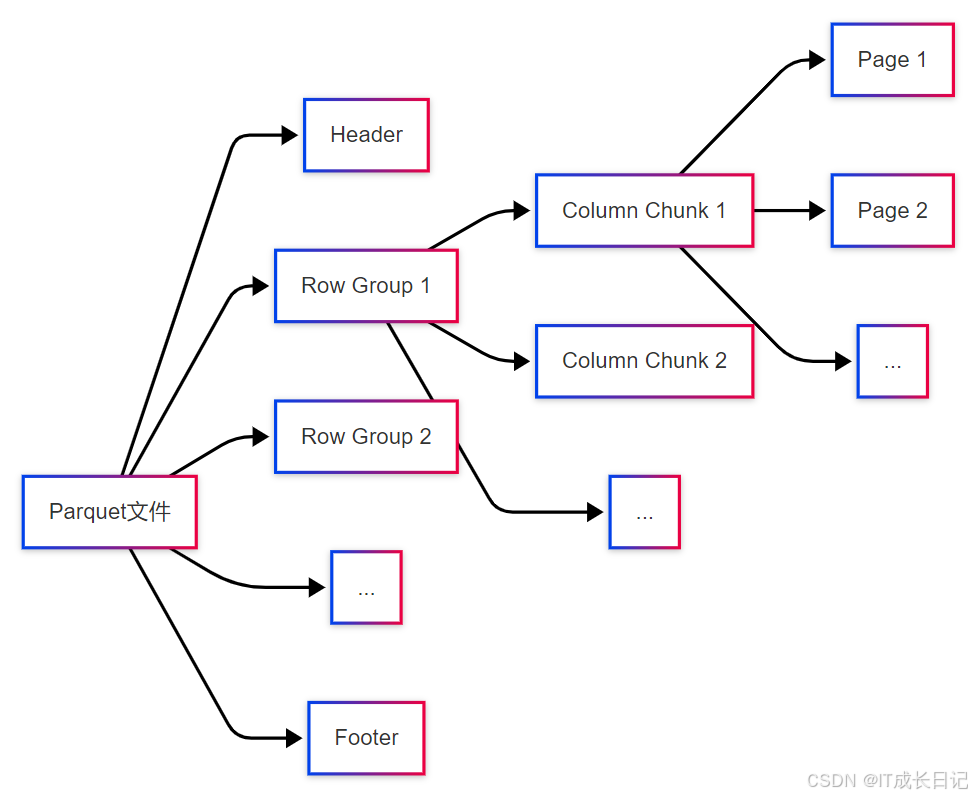
- Row Group:数据水平分区,包含一批行的数据
- Column Chunk:单个列在Row Group中的数据
- Page:Column Chunk的物理存储单元,压缩编码的基本单位
2.3.2 Parquet与ORC对比
| 特性 | ORC | Parquet |
| 复杂数据类型支持 | 有限 | 优秀(支持嵌套结构) |
| 生态系统 | Hive生态 | 跨生态(Spark等) |
| 压缩效率 | 高 | 高 |
| 读取性能 | 优 | 优 |
| ACID支持 | 支持 | 不支持 |
| 谓词下推 | 支持 | 支持 |
3 小文件问题与合并优化
3.1 小文件问题的影响
HDFS小文件(远小于块大小的文件)会导致:
- NameNode内存压力:每个文件占用约150字节内存
- Map任务开销:每个小文件产生一个Map任务
- 元数据操作开销:大量小文件增加元数据操作时间
3.2 CombineFileInputFormat原理
CombineFileInputFormat是解决小文件问题的关键技术,它将多个小文件"打包"到一个输入分片中。
3.2.1 工作流程
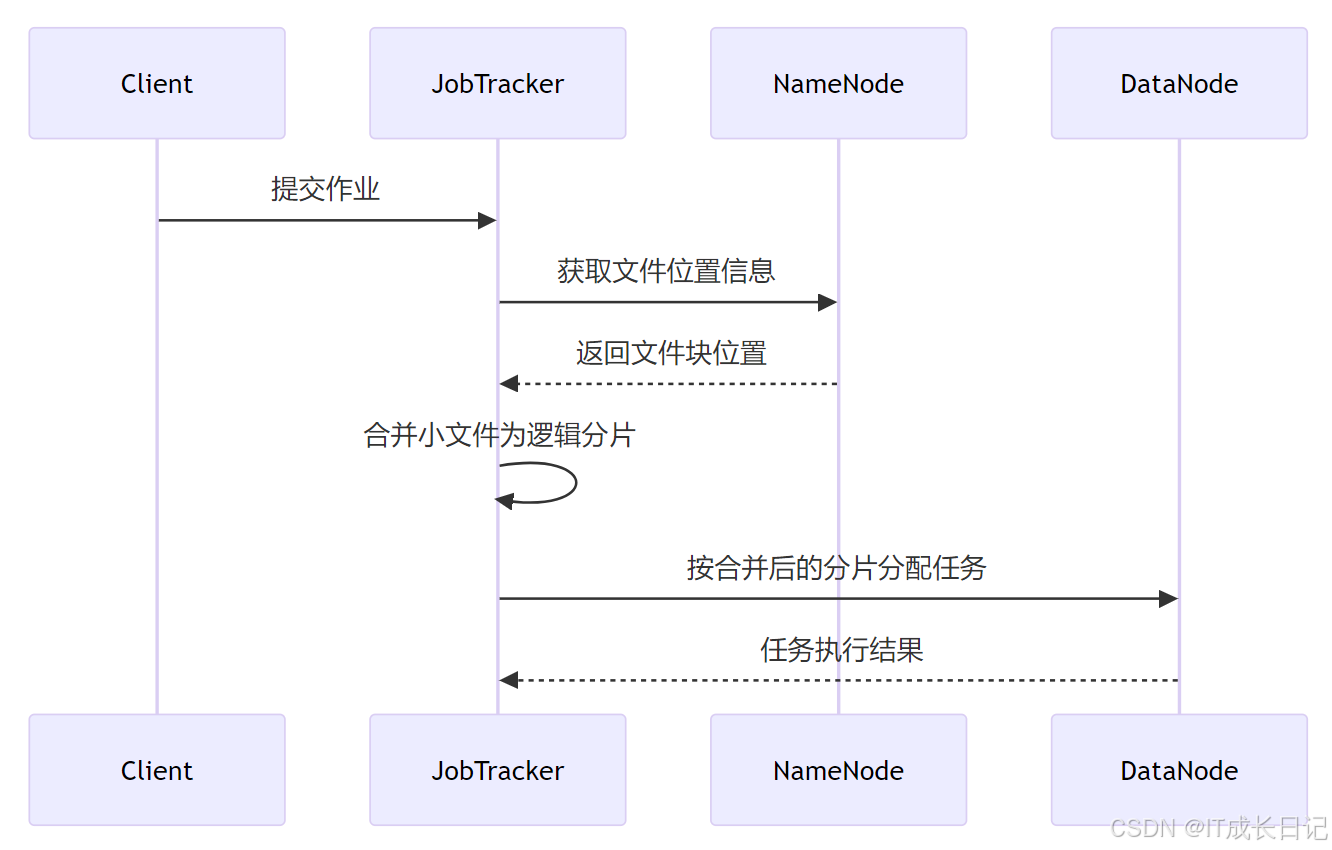
- 输入分片计算:根据配置的最大分片大小和节点位置信息,将多个小文件合并为一个逻辑分片
- 记录边界处理:确保每个文件的记录完整性不被破坏
- 本地性优化:尽量将同一节点上的小文件合并
3.2.2 关键配置参数
-- 启用CombineHiveInputFormat
SET hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;-- 每个分片最大大小(默认256MB)
SET mapreduce.input.fileinputformat.split.maxsize=268435456;-- 同一节点上分片最小大小
SET mapreduce.input.fileinputformat.split.minsize.per.node=0;-- 同一机架上分片最小大小
SET mapreduce.input.fileinputformat.split.minsize.per.rack=0;3.3 小文件合并实践方案
3.3.1 自动合并方案
- Hive自动合并:
-- 启用自动合并
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=16000000; -- 当平均文件大小小于此值时触发合并
SET hive.merge.size.per.task=256000000; -- 合并后文件大小- 定时合并脚本:
INSERT OVERWRITE TABLE target_table
SELECT * FROM source_table;3.3.2 手动合并方案
- 使用CONCATENATE命令(仅适用于未分区的ORC表):
ALTER TABLE table_name [PARTITION(partition_key='partition_value')] CONCATENATE;- 使用Hadoop Archive(HAR):
hadoop archive -archiveName myhar.har -p /user/hive/warehouse/mydb.db/mytable /user/hive/warehouse/archives- 自定义合并工具:
// 示例:使用Java API合并小文件
FileSystem fs = FileSystem.get(conf);
Path inputPath = new Path("/input/path");
Path outputPath = new Path("/output/path");CombineFileInputFormat<LongWritable, Text> inputFormat = new CombineTextInputFormat();
Job job = Job.getInstance(conf);
List<InputSplit> splits = inputFormat.getSplits(job);
// 处理合并后的分片...4 存储优化实战案例
4.1 案例1:ORC存储优化
- 转换为ORC格式:
CREATE TABLE logs_orc STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY")
AS SELECT * FROM logs_text;- 添加索引:
ALTER TABLE logs_orc [PARTITION(...)]
SET TBLPROPERTIES ("orc.create.index"="true");4.2 案例2:小文件合并
- 创建目标表(使用ORC格式):
CREATE TABLE orders_merged (order_id string,customer_id string,-- 其他字段...
) PARTITIONED BY (dt string)
STORED AS ORC;- 配置自动合并参数:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=16000000;- 执行合并:
INSERT OVERWRITE TABLE orders_merged PARTITION(dt)
SELECT * FROM orders_source DISTRIBUTE BY dt;5 高级优化技巧
5.1 列裁剪与谓词下推
- 列裁剪:只读取查询需要的列
-- 只读取name和age列
SELECT name, age FROM users;- 谓词下推:将过滤条件下推到存储层
-- ORC/Parquet会利用统计信息跳过不满足条件的行
SELECT * FROM logs WHERE dt = '2023-01-01' AND status = 'ERROR';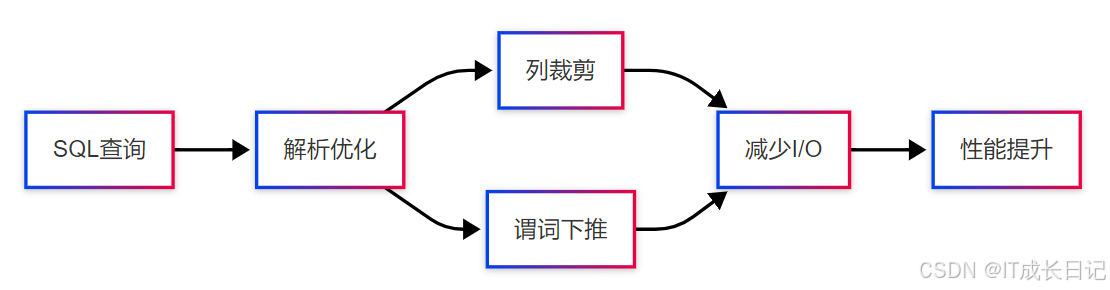
5.2 分区与分桶优化
- 分区优化:
-- 按日期和地区分区
CREATE TABLE sales (id string,amount double
) PARTITIONED BY (dt string, region string);- 分桶优化:
-- 按user_id分10个桶
CREATE TABLE user_actions (user_id string,action_time timestamp,-- ...
) CLUSTERED BY (user_id) INTO 10 BUCKETS;- 分区与分桶对比:
| 特性 | 分区 | 分桶 |
| 数据组织方式 | 目录 | 文件 |
| 优化查询类型 | 范围查询 | JOIN/聚合 |
| 文件数量控制 | 可能产生小文件 | 固定数量 |
| 适用场景 | 高基数列 | 低中基数列 |
6 监控与维护
6.1 存储格式监控
- 查看表存储格式:
DESCRIBE FORMATTED table_name;- 分析表统计信息:
ANALYZE TABLE table_name [PARTITION(...)] COMPUTE STATISTICS;
ANALYZE TABLE table_name [PARTITION(...)] COMPUTE STATISTICS FOR COLUMNS;6.2 小文件监控脚本
# 查看HDFS目录小文件情况
hdfs dfs -count -q /user/hive/warehouse/mydb.db/mytable# 统计小文件数量
hdfs dfs -ls /path | awk '{if($5 < 1000000) print $8}' | wc -l6.3 自动化维护方案
- 定期合并脚本:
-- 每周合并一次历史分区
SET hive.exec.dynamic.partition=true;
INSERT OVERWRITE TABLE target PARTITION(dt)
SELECT * FROM source
WHERE dt BETWEEN '2023-01-01' AND '2023-01-07'
DISTRIBUTE BY dt;自动化监控系统:
- 监控NameNode内存使用
- 监控Hive表文件数量和大小
- 设置阈值自动触发告警或合并任务
7 总结
7.1 存储优化
格式选择:
- 优先选择ORC或Parquet格式
- 纯Hive环境优先ORC,跨平台场景考虑Parquet
压缩配置:
- 平衡压缩比和性能:SNAPPY是不错的选择
- 存储敏感场景考虑ZLIB
编码优化:
- 根据列特征选择合适的编码方式
- 对低基数列启用字典编码
7.2 小文件处理
预防措施:
- 合理设置Hive输出文件大小
- 避免高频小批量写入
治理方案:
- 定期合并历史分区
- 对新数据配置自动合并
监控体系:
- 建立小文件监控告警
- 定期评估存储优化效果
7.3 性能优化

通过持续的性能监控、评估和优化,构建Hive存储与计算的性能优化闭环,确保数据平台始终保持高效运行。