第T10周:数据增强
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
从 tensorflow.keras 中导入 layers 模块,包含了常用的神经网络层,用来搭建模型结构。
检查并列出系统中可用的物理 GPU 设备,返回一个 GPU 列表。
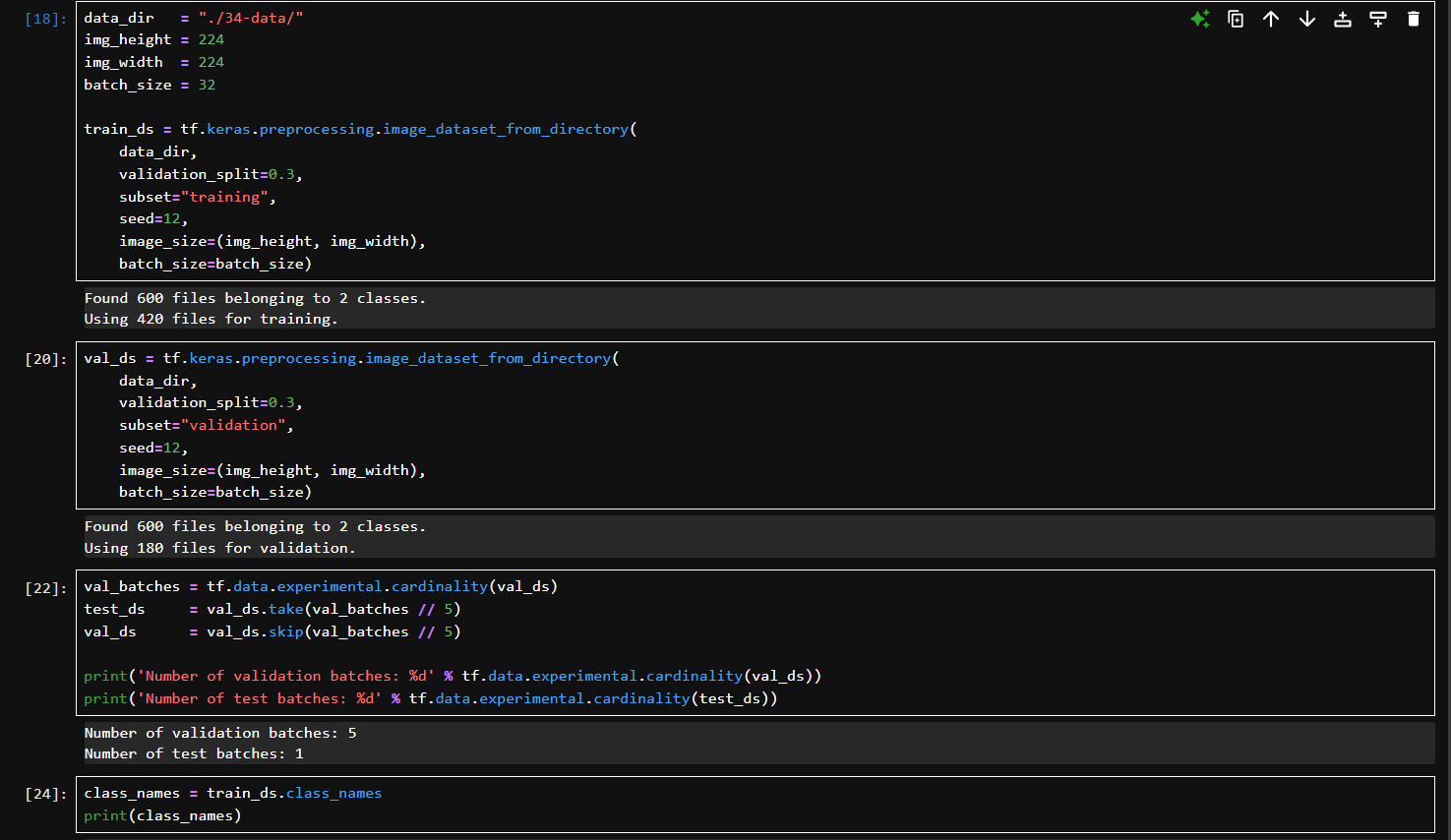
img_height, img_width:图片统一 resize 成 224x224。
batch_size:每个训练 batch 中的样本数为 32。
validation_split=0.3:把 30% 数据预留为验证用;
subset=“training”:表示当前提取的是训练数据;
seed=12:用于保证训练/验证划分一致;
自动读取所有图像并打标签,resize 到指定大小,分成批次。输出:总共 600 张图像,420 用于训练。
subset=“validation”:这次提取的是验证集;同样参数以确保训练验证划分方式一致。
输出:验证集为 180 张图像。
cardinality():获取 val_ds 中 batch 的总数(为 5);val_ds.take(n):取前 n 个 batch 作为 test_ds;val_ds.skip(n):剩余部分留作 val_ds。相当于把验证集的 20% 再切出来当 test 集(180 张图中约 36 张是测试集,剩余 144 张继续作验证集)。
每个 batch 有 32 张图像。
获取类别名称,[‘cat’, ‘dog’]。
自定义预处理函数:
把图像像素值归一化到 [0, 1](原始值是 0~255);保留原标签。
map():将上面定义的预处理函数应用到数据集中每个元素;num_parallel_calls=AUTOTUNE:启用多线程并行处理。
.cache():将数据缓存到内存中,加快读取速度;
.prefetch():训练时提前准备好下一个 batch,减少训练等待时间。
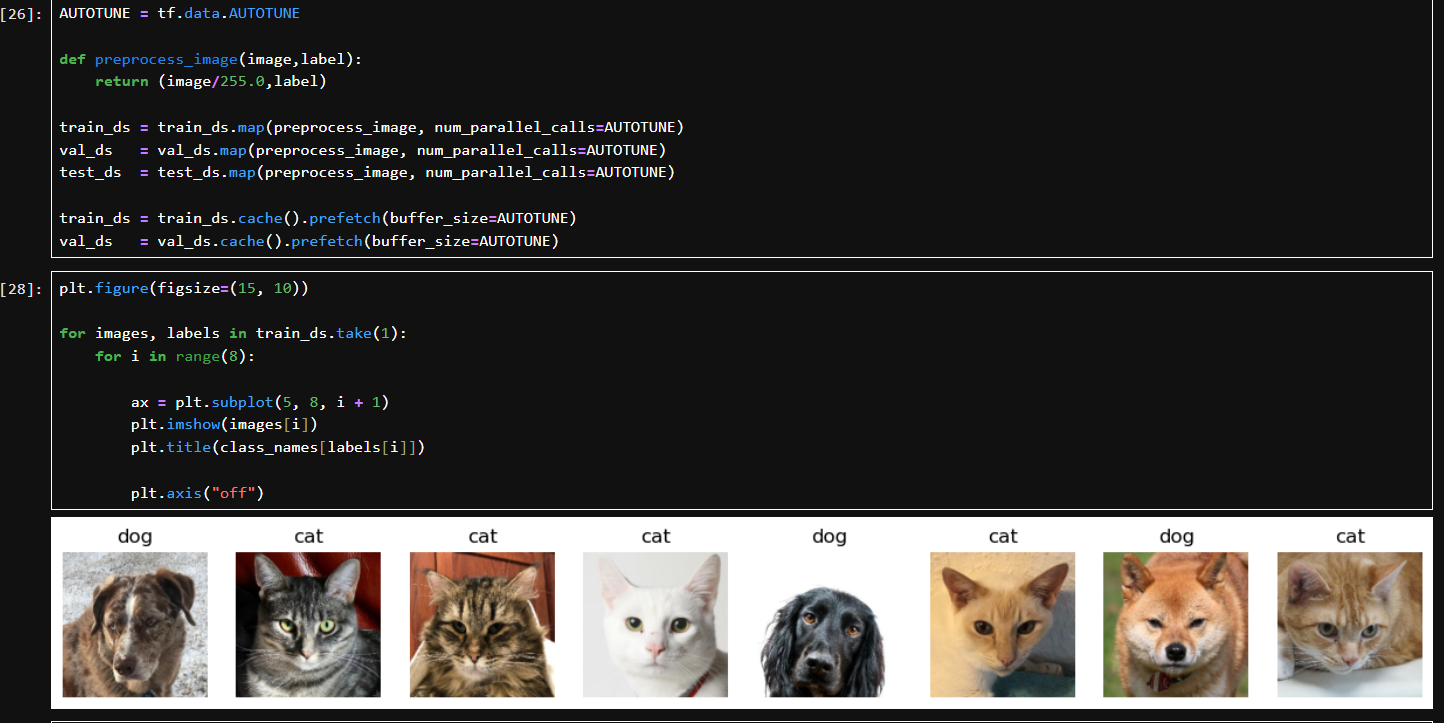
take(1):从训练集中取出 1 个 batch(共 32 张图);迭代取出其中的图像和标签。
只显示前 8 张图片;plt.subplot(5, 8, i + 1):在 5x8 的网格中放置图像;plt.imshow():显示图片;plt.title():显示类别;plt.axis(“off”):隐藏坐标轴。
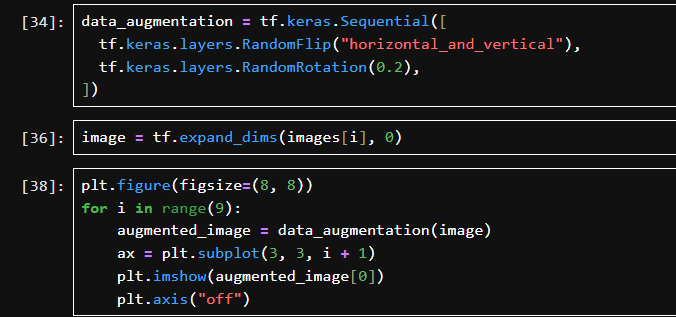
RandomFlip(“horizontal_and_vertical”)
随机水平 & 垂直翻转图像。
RandomRotation(0.2)
随机将图像旋转 ±20% 的角度。
images[i] 是单张图像的张量,形状是 [height, width, channels];模型要求输入带有 batch 维度,即 [1, height, width, channels];所以expand_dims(…, 0) 在最前加了一个维度,构成一个 batch。
创建一个 3x3 网格画布;每次对同一张图 image 进行数据增强;用 plt.imshow() 显示增强后的图像;隐藏坐标轴。
使用 Keras 增强层对图像进行随机翻转和旋转,并将同一张原始图片经过 9 次增强后的结果可视化。
data_augmentation表示训练时自动进行数据增强;Conv2D(16, 3, …):卷积层,16 个 3x3 的卷积核,激活函数 ReLU;MaxPooling2D():池化层,降低特征图空间维度。将数据增强模块嵌入训练数据集(用 training=True 激活增强);map() 函数在 TensorFlow Dataset 中遍历每个样本 (x, y);设置 num_parallel_calls=AUTOTUNE 自动调节线程数。train_ds 数据会自动带数据增强。
Conv2D + ReLU,三层卷积提取空间特征;MaxPooling2D,每层后面做降采样,减小计算量;Flatten,将多维张量展平,连接到全连接层;Dense(128),全连接隐藏层,128 个神经元,ReLU 激活;Dense(len(class_names)), 输出层,单元个数 = 类别数,未加激活函数。
使用 Adam 优化器;SparseCategoricalCrossentropy:适用于标签是整数编码;from_logits=True:表示最后一层未经过 softmax,loss 会自动处理;指标使用 accuracy 来评估性能。
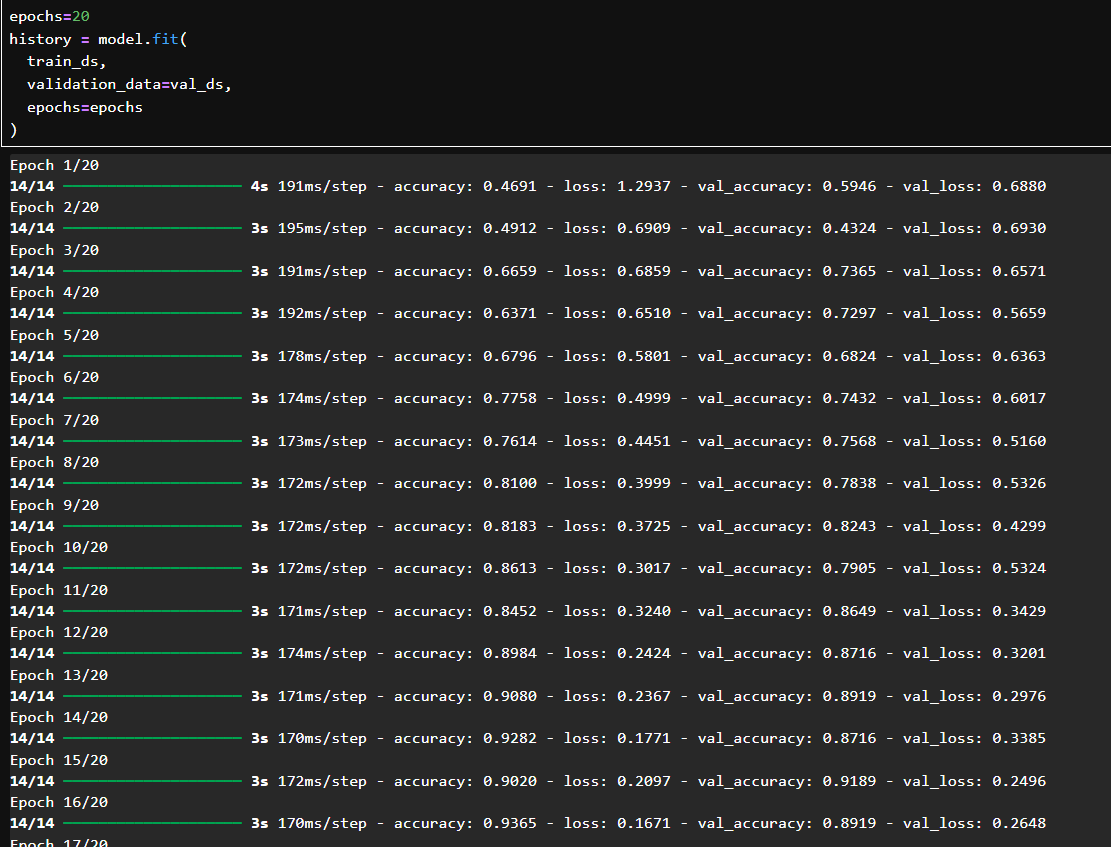
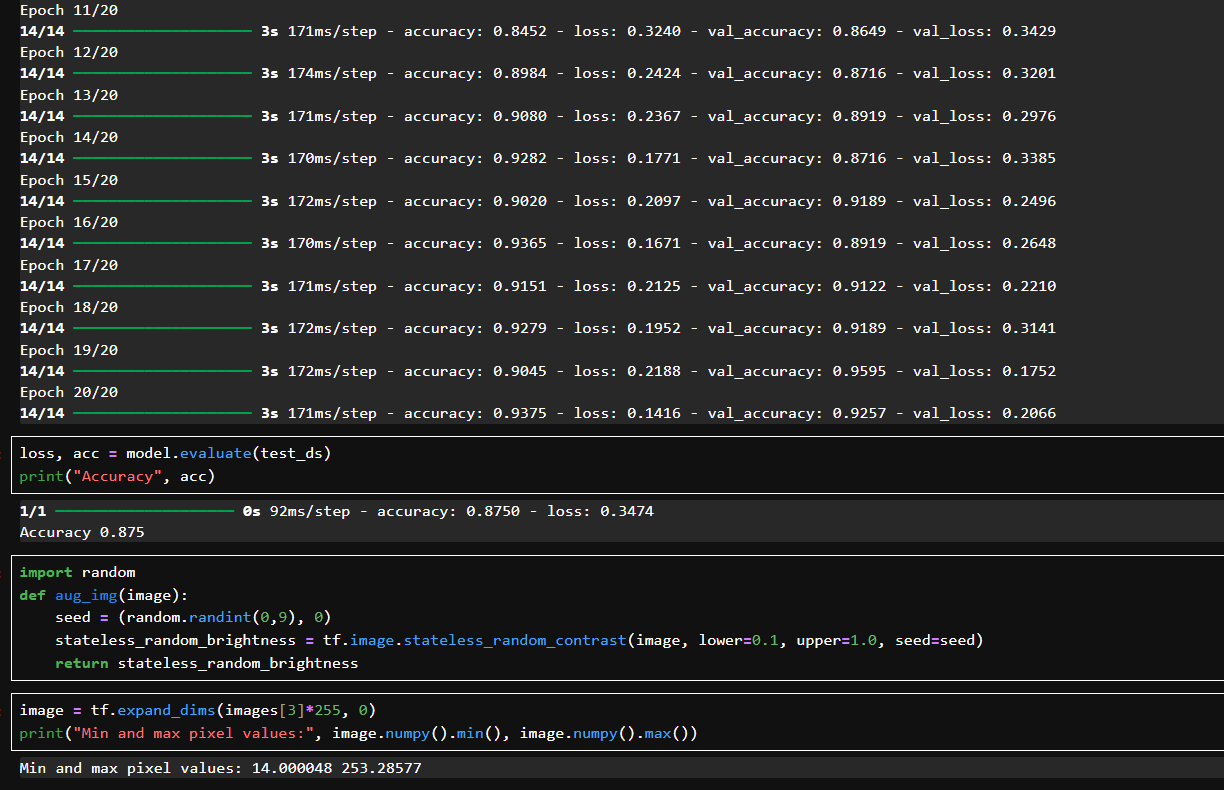
用 train_ds 训练,val_ds 验证;总共训练了 20 轮(epoch);
每一轮都输出了:
accuracy:训练集准确率;
loss:训练损失;
val_accuracy:验证集准确率;
val_loss:验证损失。
初始 val_accuracy 为 59.4%,逐轮提升,最终达到 92.5%;
loss 和 val_loss 都稳定下降,没有过拟合;从第 10 轮开始准确率就提升很高。
用分离出来的测试集 test_ds 评估最终模型性能,表示模型在从未见过的数据上仍能达到 87.5% 的分类准确率。
使用 stateless_random_contrast:给图像加入对比度增强;使用固定种子 (seed, 0):可以控制随机性、实现复现。
将训练图像 [3] 乘回 255,还原为原始像素;使用 expand_dims 添加 batch 维;打印最小/最大像素值:表明增强后图像仍保持合理亮度范围,没有过度偏暗或偏亮。
创建一个新的图像窗口,大小为 8x8 英寸。
对同一张图像 image 进行 9 次增强;每次调用 aug_img() 函数,使用tf.image.stateless_random_contrast() 添加随机对比度。
创建一个 3x3 网格的子图,把当前增强图像放在第 i+1 个位置。
augmented_image 的 shape 是 [1, h, w, c],取出 [0] 表示取出图像本身;
.numpy():将 Tensor 转为 NumPy 数组;.astype(“uint8”):把图像像素转回标准的 8-bit 整数格式,然后去除坐标轴。