Perforated Backpropagation:神经网络优化的创新技术及PyTorch使用指南
近年来,深度学习在从大型语言模型(LLM)到机器人技术再到医疗人工智能的众多领域展现出了显著成效。随着研究资源的持续投入,这一领域通过架构创新、更大规模的数据集和先进硬件而不断发展。然而,深度学习的基础构建模块——人工神经元,自1943年首次数学表述以来几乎保持不变。同样,其基础算法——基于梯度下降的反向传播,自20世纪80年代首次应用于神经网络以来,仅在优化技术方面有所改进。当前,深度学习领域正迎来对基础组件及训练方法的一次重要革新。
尽管神经网络能够执行复杂任务,但传统人工神经元的工作原理相对简单。网络中的每个神经元本质上是线性分类器,它计算输入的加权和,并通过非线性函数转换得到输出值。通过反向传播,这些神经元学习识别特定的输入模式,成为特征检测器。然而作为线性分类器,它们不可避免地会产生假阳性和假阴性结果。
一个关键的思考是:如果每个神经元能够识别其分类错误的模式,整个神经网络的智能水平是否会有质的提升?如果有一个来自网络外部的节点提供额外的可学习权重,使神经元能够识别其失效情况,会带来怎样的改进?
这正是穿孔反向传播(Perforated Backpropagation)技术所解决的问题,该技术的灵感来源于近八十年来神经科学领域对真实生物神经元的研究发现。
树突学习机制
在深度学习系统的传统训练过程中,输入数据在网络中前向传播,计算误差值,然后该误差通过反向传播调整网络参数。在这一过程中,每个神经元会计算一个误差项,表示其决策的准确性,并用于权重调整。这个误差值同时也是一个量化指标,能够标识特定输入模式何时被错误分类。Perforated Backpropagation技术正是利用这一误差值来训练新的"树突"节点。
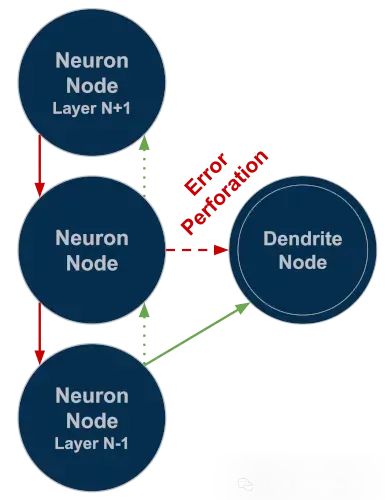
树突与传统神经元有两个显著区别:
首先,树突在训练阶段形成不同的连接方式。创建时,树突没有输出连接,但会与关联神经元建立相同输入源的加权连接。不同的是,树突不使用标准梯度下降计算误差,而是采用基于协方差的损失函数。该函数的设计目标是最大化树突输出与神经元计算误差之间的协方差值。树突通过调整权重,使得对神经元分类困难的输入模式能产生较高的输出响应。这使树突能够专门识别神经元分类决策中的异常值模式,其理论基础类似于ResNet中的残差误差学习,但应用于单个神经元级别。
树突增强型神经元
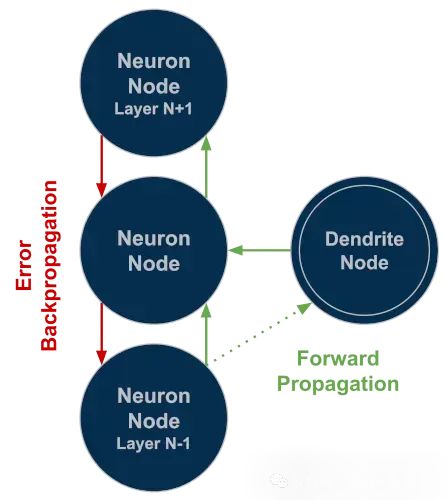
树突权重学习完成后,通过添加从树突到关联神经元的单个输出连接集成到网络中。该连接权重根据神经元的误差项,与其他权重采用相同的方式进行调整。误差不会通过此连接继续反向传播。这一设计使神经元在权重更新过程中只考虑其他神经元的误差贡献,而树突被置于主网络"外部"。这使每个神经元能够保持其原始特征编码能力,同时获得对该特征做出更精确决策的能力。这一机制从神经元级别提升了整个网络的性能表现。
实际应用案例
将Perforated Backpropagation应用于各种BERT模型进行自然语言处理。实验结果显示,该技术在所有测试模型中实现了3%至17%的准确率提升。
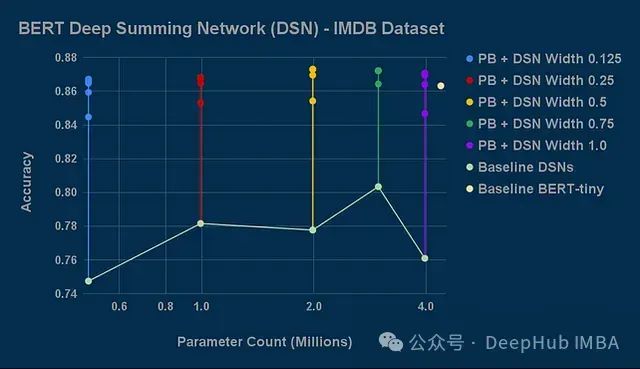
更为显著的是,树突的引入使神经元计算能力增强,甚至可用于创建参数更少但保持高精度的压缩模型架构。这一点通过从简化模型开始实现,即使加入树突带来的额外参数,总参数量仍远低于原始模型。实验表明,基于深度求和网络(Deep-Summing-Network)的改进模型能够匹配甚至超越BERT-tiny的性能,而参数数量仅为后者的11%。
PyTorch实现
Perforated Backpropagation这种新型神经元实例化了人工树突的概念,赋予其类似于生物神经元中树突所增加的计算能力。以下是在PyTorch中实现Perforated Backpropagation的分步指南,基于PyTorch官方仓库的MNIST基准示例。
首先,通过PyPI安装所需的软件包:
pip install perforatedai
在训练脚本开始处添加以下导入语句:
fromperforatedaiimportpb_globalsasPBGfromperforatedaiimportpb_modelsasPBMfromperforatedaiimportpb_utilsasPBU
要使模型组件能够添加人工树突,需要在模型创建后进行转换处理:
model=Net().to(device)model=PBU.initializePB(model)
树突功能的核心由Perforated Backpropagation追踪器对象管理。该对象不仅记录训练改进情况,还决定何时向网络模块添加树突。为获得最佳性能,追踪器管理优化器和调度器,这需要对初始设置进行如下修改:
# 原始格式:
optimizer=optim.Adadelta(model.parameters(), lr=args.lr)
scheduler=StepLR(optimizer, step_size=1, gamma=args.gamma)# 新格式:
PBG.pbTracker.setOptimizer(optim.Adadelta)
PBG.pbTracker.setScheduler(StepLR)
optimArgs= {'params':model.parameters(),'lr':args.lr}
schedArgs= {'step_size':1, 'gamma': args.gamma}optimizer, scheduler=PBG.pbTracker.setupOptimizer(model, optimArgs, schedArgs)
这样配置后,创建的优化器和调度器保持原有设置,但追踪器获得了对它们的引用。此外,应保留
optimizer.step()
,但需要从训练循环中移除
scheduler.step()
。
最后一个必要修改是将验证分数传递给追踪器。对于MNIST示例,在
test
函数中添加以下代码:
model, restructured, trainingComplete=PBG.pbTracker.addValidationScore(100.*correct/len(test_loader.dataset),model)model.to(device)if(restructured):optimArgs= {'params':model.parameters(),'lr':args.lr}schedArgs= {'step_size':1, 'gamma': args.gamma}optimizer, scheduler=PBG.pbTracker.setupOptimizer(model, optimArgs, schedArgs)returnmodel, optimizer, scheduler, trainingComplete
当添加树突时,
model
将是包含新树突模块且保持原有权重的新架构。此时
restructured
变为true,需要重置优化器和调度器以指向新模型参数。
addValidationScore
函数的第三个输出
trainingComplete
表示追踪器是否确定额外树突不再提升性能。所有这些变量都需要从
test
函数返回以供后续训练使用。相应地,需要对函数定义和训练循环做出以下调整:
# 原始 test 定义:
deftest(model, device, test_loader):
# 新格式
deftest(model, device, test_loader, optimizer, scheduler, args):# 原始训练循环
forepochinrange(1, args.epochs+1):train(args, model, device, train_loader, optimizer, epoch)test(model, device, test_loader)scheduler.step()
# 新格式
forepochinrange(1, args.epochs+1):train(args, model, device, train_loader, optimizer, epoch)model, optimizer, scheduler, trainingComplete=test(model, device, test_loader, optimizer, scheduler, args)if(trainingComplete):break
完成上述修改后,系统将默认添加三个树突用于初始测试。初次成功运行后,通过添加以下配置启用完整实验:
PBG.testingDendriteCapacity=False
实验结果显示,添加树突后MNIST模型的错误率减少了29%,验证了Perforated Backpropagation的有效性。
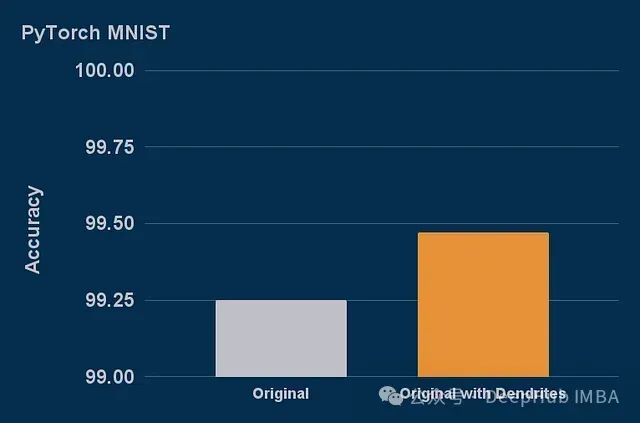
使用树突实现模型压缩
向模型添加树突会增加参数数量,但性能提升并非仅仅由参数增加解释。新型神经元及其树突实际上比传统神经元更具计算效率,这使得树突技术也适用于模型压缩场景。
实现树突辅助的模型压缩的关键在于从比原始模型更小的基础模型开始。对于MNIST示例,可通过向模型定义添加
width
参数来实现:
classNet(nn.Module):def__init__(self, num_classes, width):super(Net, self).__init__()self.conv1=nn.Conv2d(1, int(32*width), 3, 1)self.conv2=nn.Conv2d(int(32*width), int(64*width), 3, 1)self.dropout1=nn.Dropout(0.25)self.dropout2=nn.Dropout(0.5)self.fc1=nn.Linear(144*int(64*width), int(128*width))self.fc2=nn.Linear(int(128*width), num_classes)
使用0.61的宽度值并添加一个树突后,得到了如下结果:
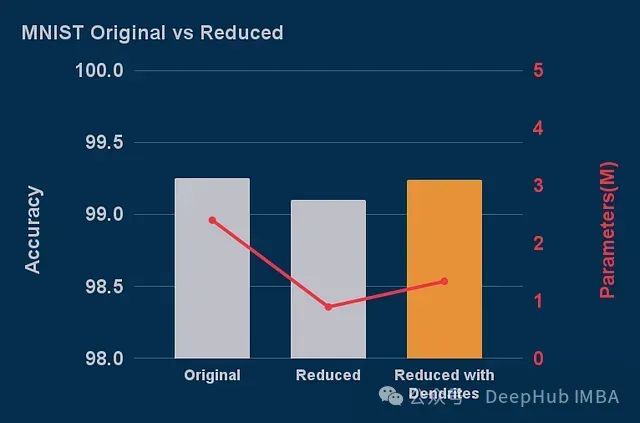
使用Perforated Backpropagation实现44%模型压缩且无精度损失
如图所示,缩减的基础模型在MNIST数据上表现较差。减小全连接层模型的宽度会导致参数数量的二次减少,而添加树突仅带来线性的参数增加。这就解释了为什么向每个神经元添加树突后,模型能够恢复原始性能水平,同时总体参数量仍比原始模型减少44%。
总结
Perforated Backpropagation技术代表了深度学习基础构建模块的重要革新,通过仿生学习机制重塑了人工神经元的计算范式。本文详述的树突增强型神经元不仅从理论上突破了传统线性分类器的局限性,更在实践中展现出显著价值:提升模型精度的同时开辟了高效模型压缩的新途径。
实验结果表明,这一技术能够在不同规模的神经网络中产生实质性改进,尤其在BERT等复杂模型中实现高达17%的准确率提升。更引人注目的是,通过树突辅助压缩的模型能在参数减少44%的情况下保持原有性能水平,这对计算资源受限的边缘设备部署和大规模模型优化具有重要意义。
代码:
https://avoid.overfit.cn/post/bf9607216a264d90aea41d7f3fe6cee7
作者:Dr. Rorry Brenner