C++——入门基础(2)
文章目录
- 一、前言
- 二、C++入门
- 2.1 缺省参数
- 2.2 函数重载
- 2.2.1 参数类型不同
- 2.2.1.1 整体参数类型不同
- 2.2.1.2 参数类型顺序不同
- 2.2.2 参数个数不同
- 2.2.3 避坑注意
- 2.2.3.1无参与有参
- 2.2.3.2 返回值不同
- 2.3 引用
- 2.3.1 引用的概念
- 2.3.2引用的结构
- 2.3.3 引用的特点
- 2.3.4引用的作用
- 2.3.4.1 作用一
- 2.3.4.2 作用二
- 2.3.4.3 作用三
- 2.3.4.4 作用四
- 2.4 传值传参、传值返回、传引用返回的区别
- 2.4.1 传值传参
- 2.4.2 传值返回
- 2.4.3 传引用返回
- 2.4.4 传引用返回的误用
- 2.5 const引用
- 2.5.1 const引用的概念
- 2.5.2 const引用的用法
- 2.6 inline
- 2.7 nullptr
- 2.7.1 nullptr的概念
- 2.7.2 nullptr的用法
- 三、总结
一、前言
学前必问——今天的你还在继续学习吗?Hello啊,各位宝子们!上一节内容博主给大家细致的讲解了C++的入门语法以及与C的不同之处。我相信大家肯定已经完全消化了吧。那今天,博主和大家再续前言,深入理解C++的入门语法基础。
二、C++入门
2.1 缺省参数
1、缺省参数是函数在声明或者定义时为函数参数指定的一个缺省值,在我们调用函数的时候如果没有指定实参,那么默认采用形参的缺省值,否则使用指定的实参。缺省参数可以分为全缺省参数和半缺省参数。(有一些应用场景我们也把缺省参数称之为默认参数)
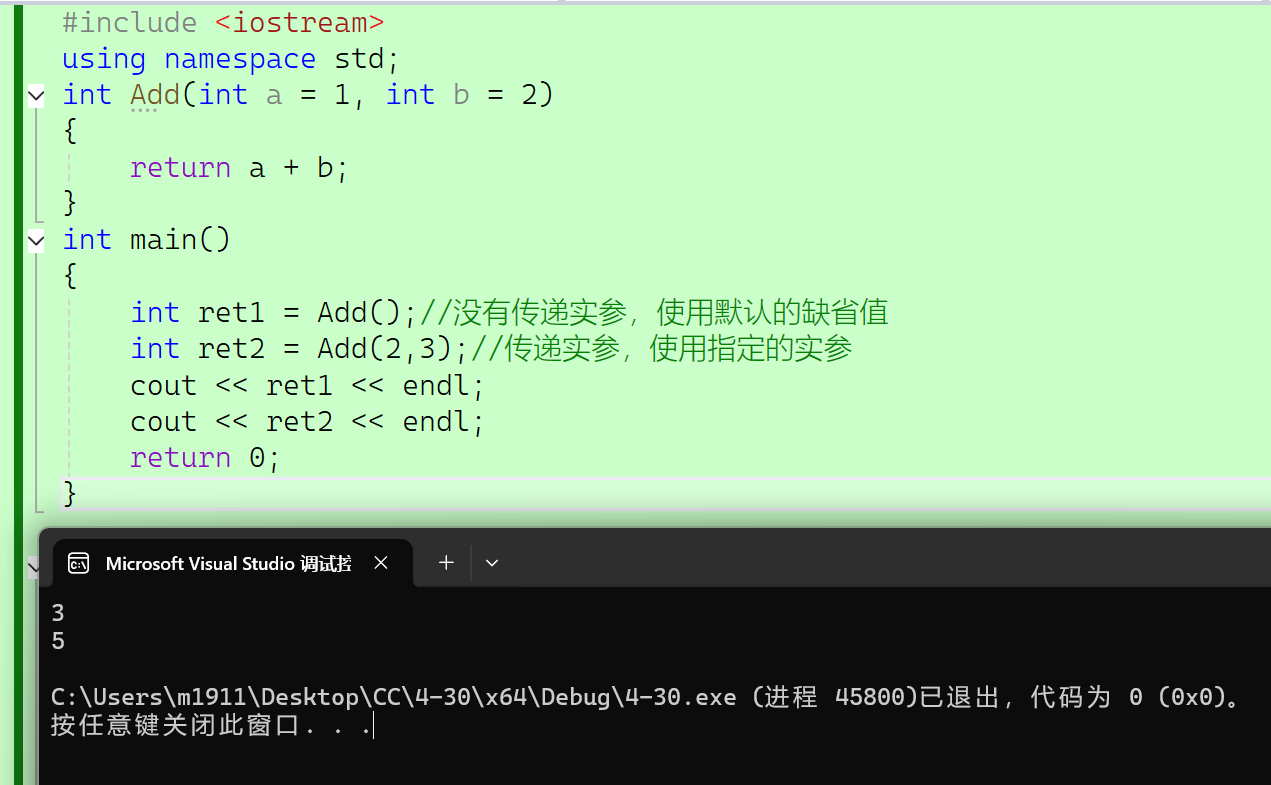
#include <iostream>
using namespace std;
int Add(int a = 1, int b = 2)
{return a + b;
}
int main()
{int ret1 = Add();//没有传递实参,使用默认的缺省值int ret2 = Add(2,3);//传递实参,使用指定的实参cout << ret1 << endl;cout << ret2 << endl;return 0;
}
2、全缺省就是全部形参都给缺省值,半缺省就是部分形参给缺省值。缺省值的指定使用是从右往左依次连续缺省,不可以跳跃或者间隔缺省。
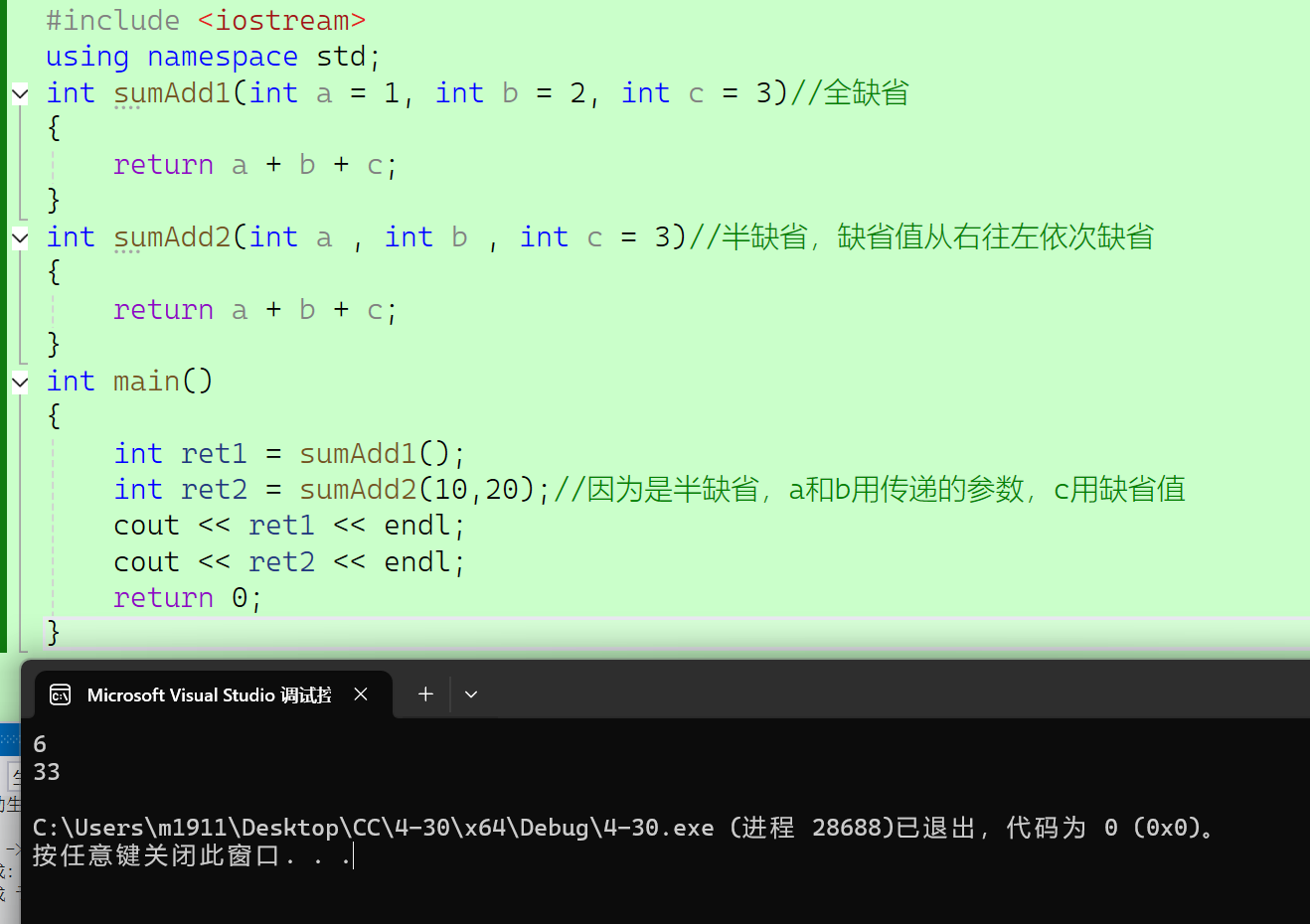
#include <iostream>
using namespace std;
int sumAdd1(int a = 1, int b = 2, int c = 3)//全缺省
{return a + b + c;
}
int sumAdd2(int a , int b , int c = 3)//半缺省,缺省值从右往左依次缺省
{return a + b + c;
}
int main()
{int ret1 = sumAdd1();int ret2 = sumAdd2(10,20);//因为是半缺省,a和b用传递的参数,c用缺省值cout << ret1 << endl;cout << ret2 << endl;return 0;
}
3、当缺省参数进行函数调用是,语法规定缺省值必须从左往右依次传递给实参,不可以跳跃或者间隔传递。
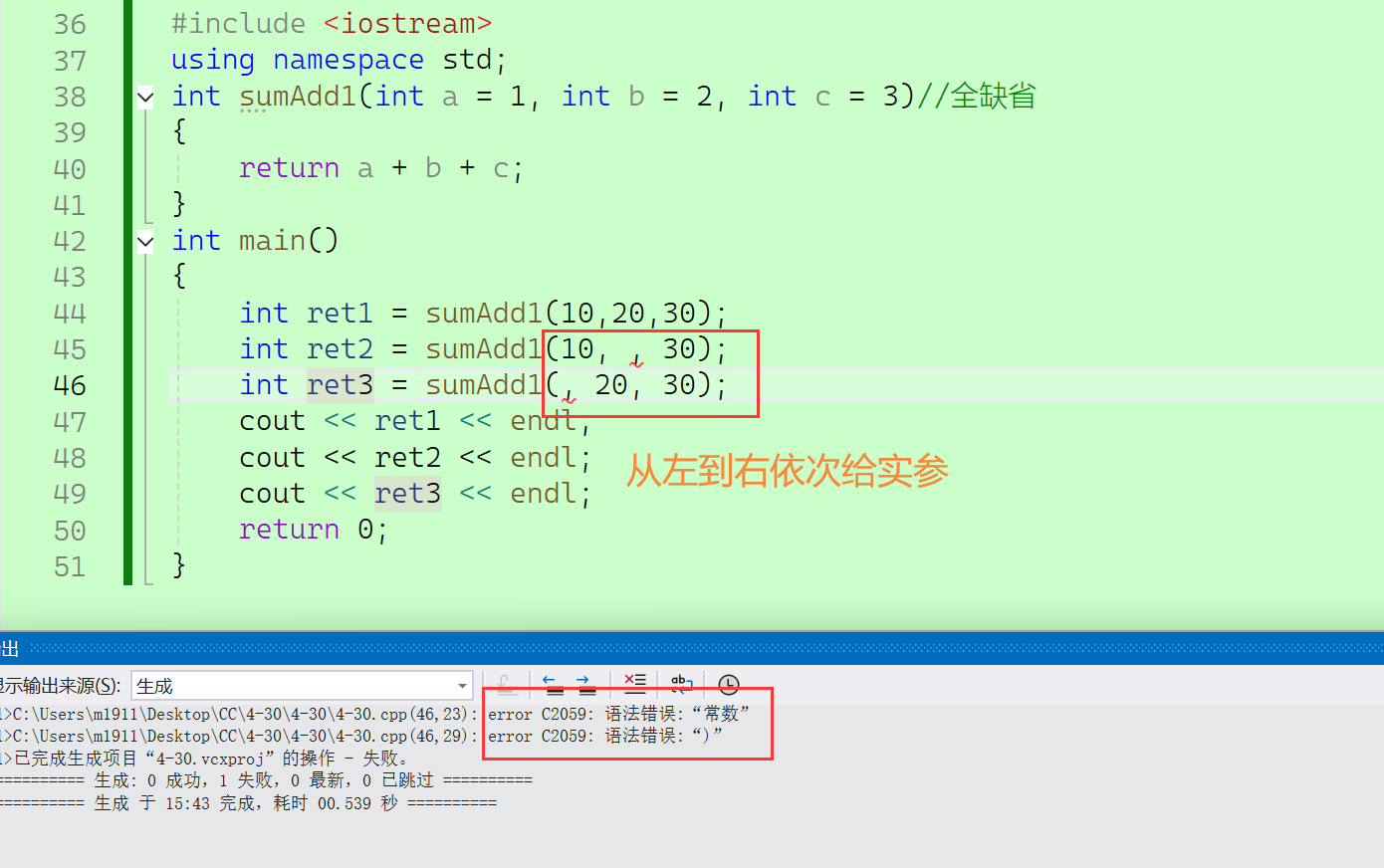
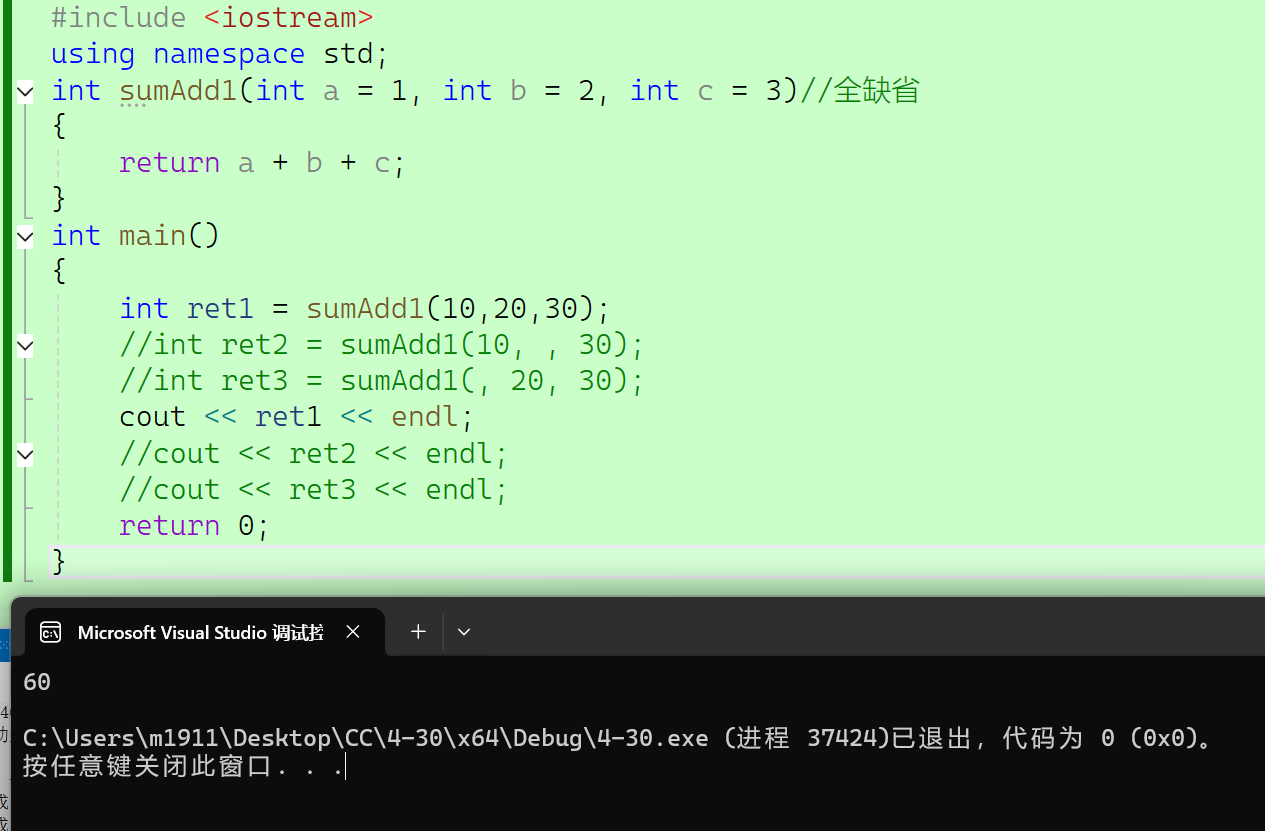
#include <iostream>
using namespace std;
int sumAdd1(int a = 1, int b = 2, int c = 3)//全缺省
{return a + b + c;
}
int main()
{int ret1 = sumAdd1(10,20,30);//int ret2 = sumAdd1(10, , 30);//int ret3 = sumAdd1(, 20, 30);cout << ret1 << endl;//cout << ret2 << endl;//cout << ret3 << endl;return 0;
}
4、当函数的定义和声明分离的时候,语法规定缺省值必须包括在函数声明里面,不可以在定义和声明中同时包括缺省值。
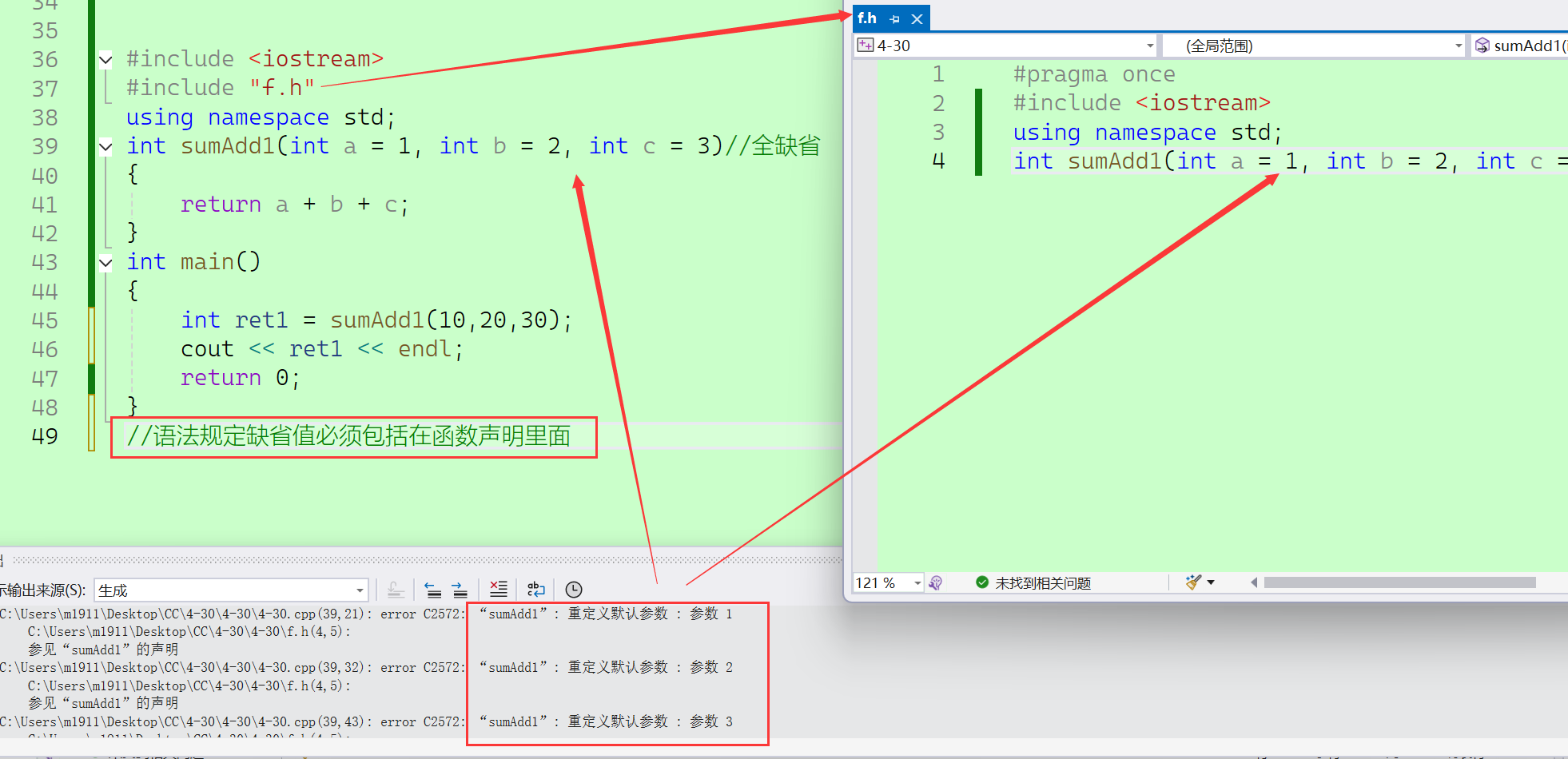
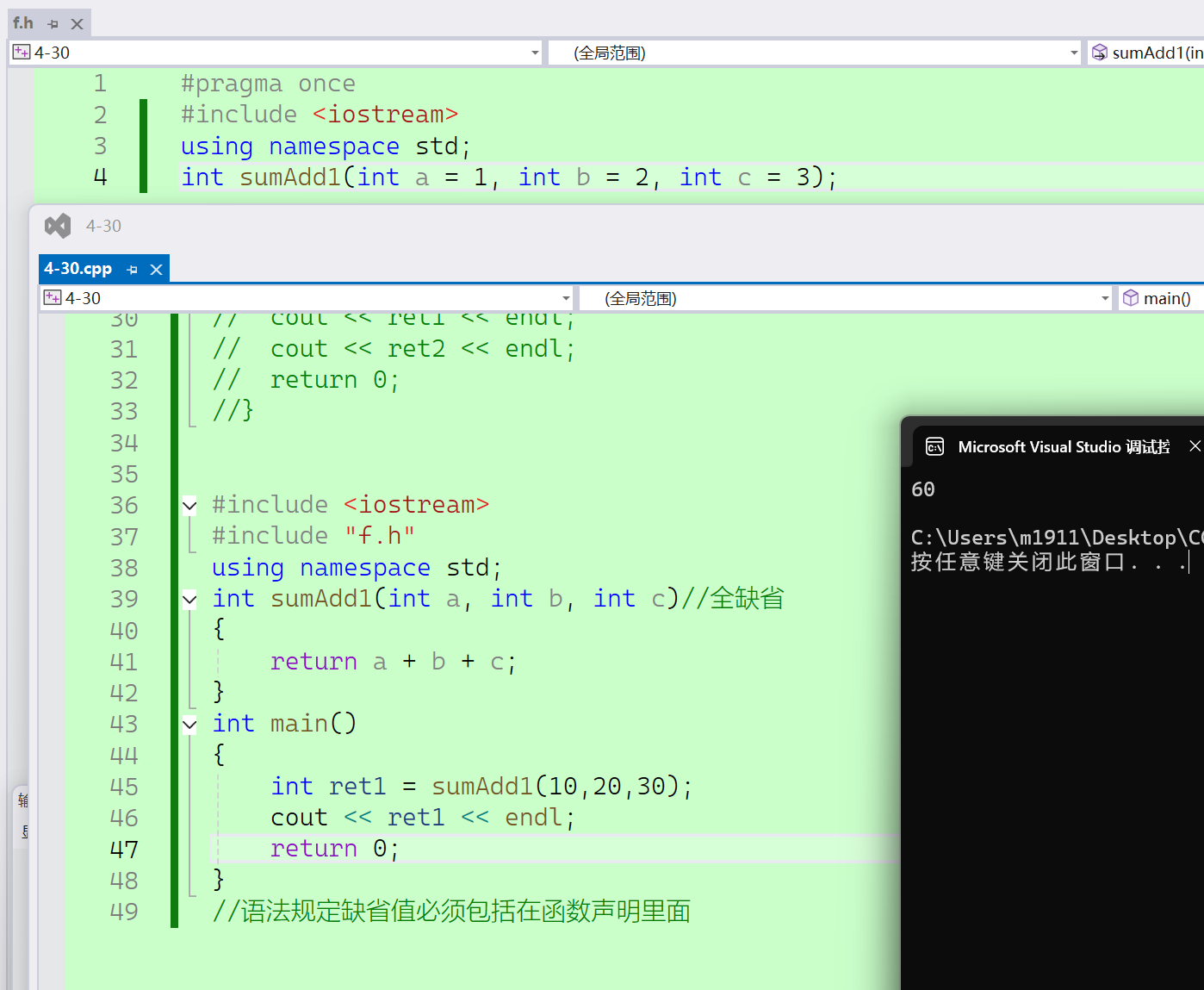
//f.h
#pragma once
#include <iostream>
using namespace std;
int sumAdd1(int a = 1, int b = 2, int c = 3);
#include <iostream>
#include "f.h"
using namespace std;
int sumAdd1(int a, int b, int c)//全缺省
{return a + b + c;
}
int main()
{int ret1 = sumAdd1(10,20,30);cout << ret1 << endl;return 0;
}
//语法规定缺省值必须包括在函数声明里面
2.2 函数重载
C++语法支持在同一块作用域中出现同名的函数,但是这些函数的参数类型不同或者参数个数不同。通过函数重载使C++函数调用出现了多态行为,也让语法变得更加灵活。但值得注意的是:C语言中并不支持函数重载。
2.2.1 参数类型不同
2.2.1.1 整体参数类型不同
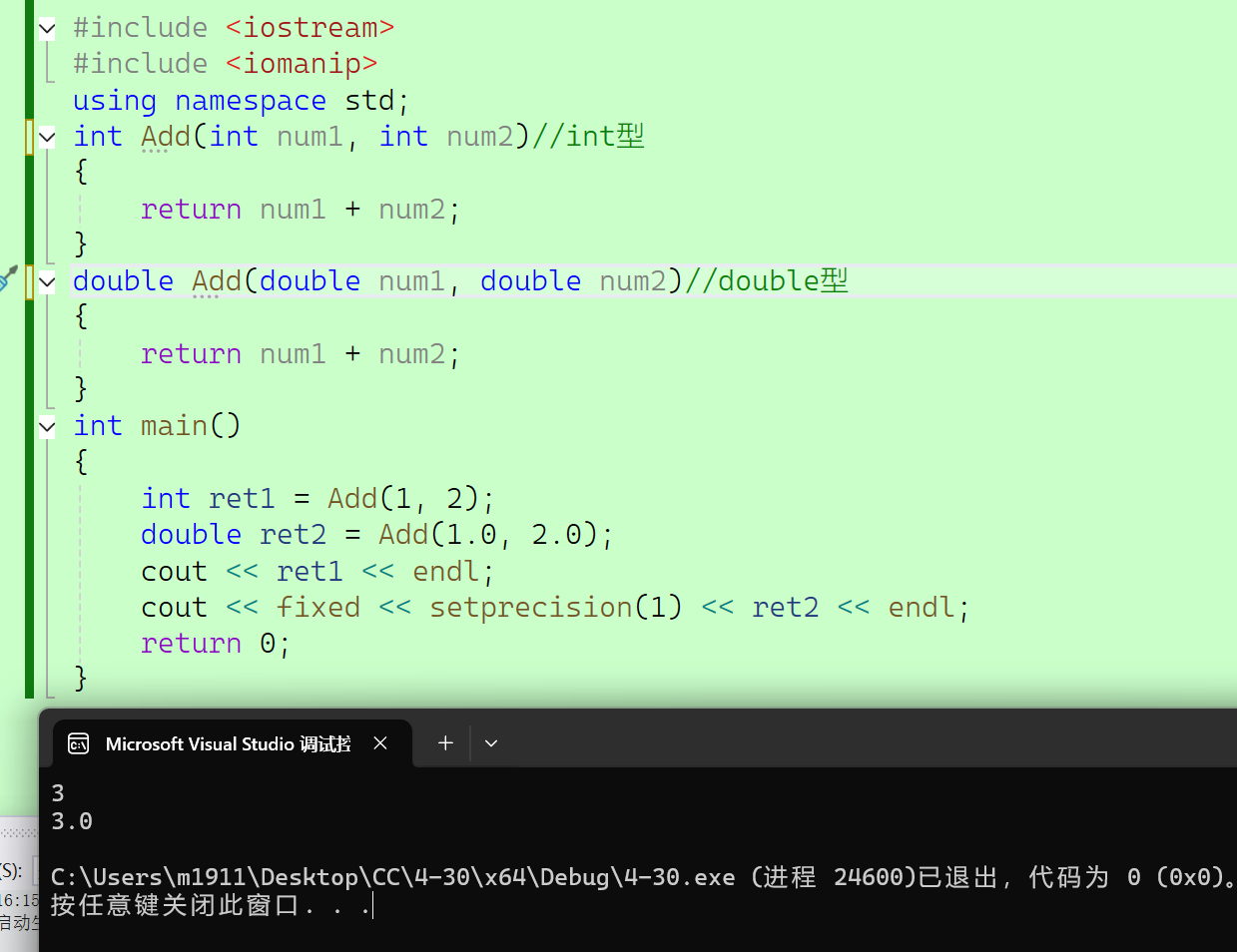
//整体参数类型不同
#include <iostream>
#include <iomanip>
using namespace std;
int Add(int num1, int num2)//int型
{return num1 + num2;
}
double Add(double num1, double num2)//double型
{return num1 + num2;
}
int main()
{int ret1 = Add(1, 2);double ret2 = Add(1.0, 2.0);cout << ret1 << endl;cout << fixed << setprecision(1) << ret2 << endl;return 0;
}
2.2.1.2 参数类型顺序不同
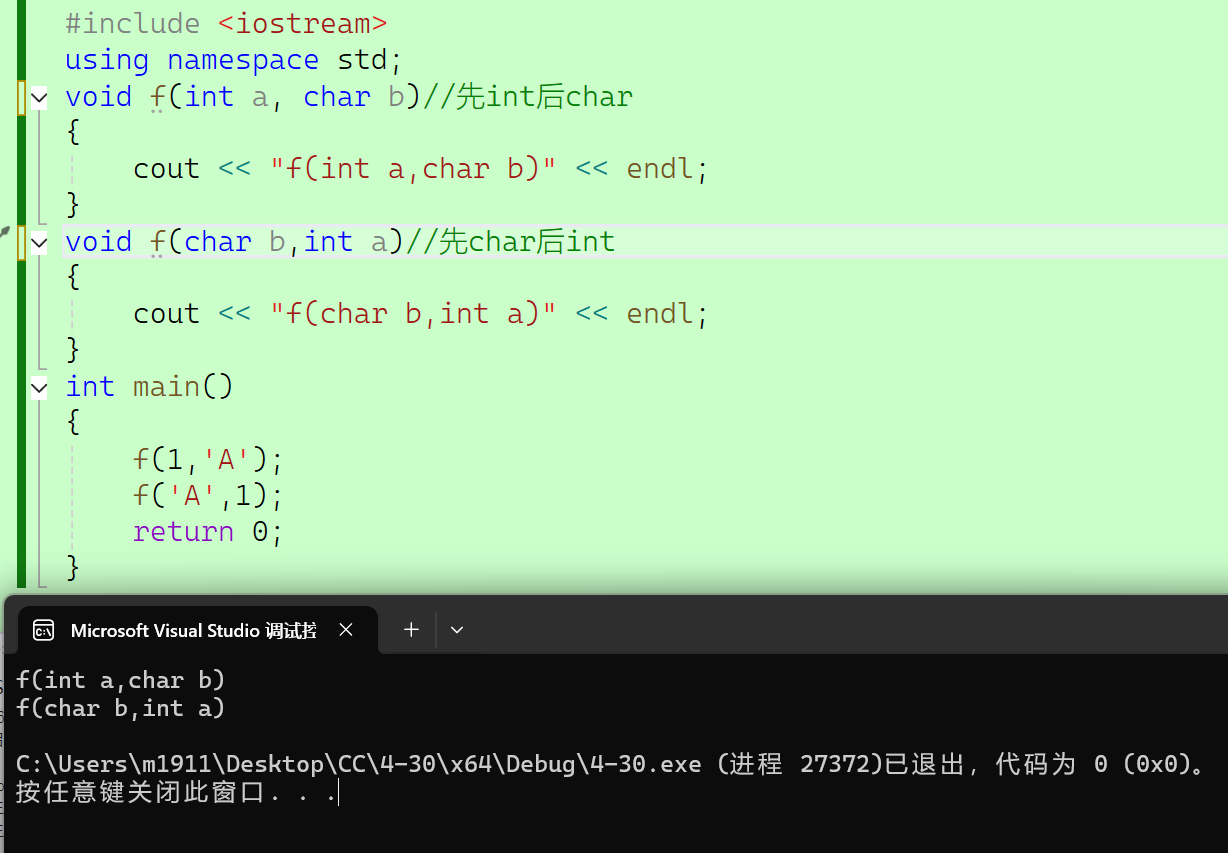
//参数类型顺序不同
#include <iostream>
using namespace std;
void f(int a, char b)//先int后char
{cout << "f(int a,char b)" << endl;
}
void f(char b,int a)//先char后int
{cout << "f(char b,int a)" << endl;
}
int main()
{f(1,'A');f('A',1);return 0;
}
2.2.2 参数个数不同
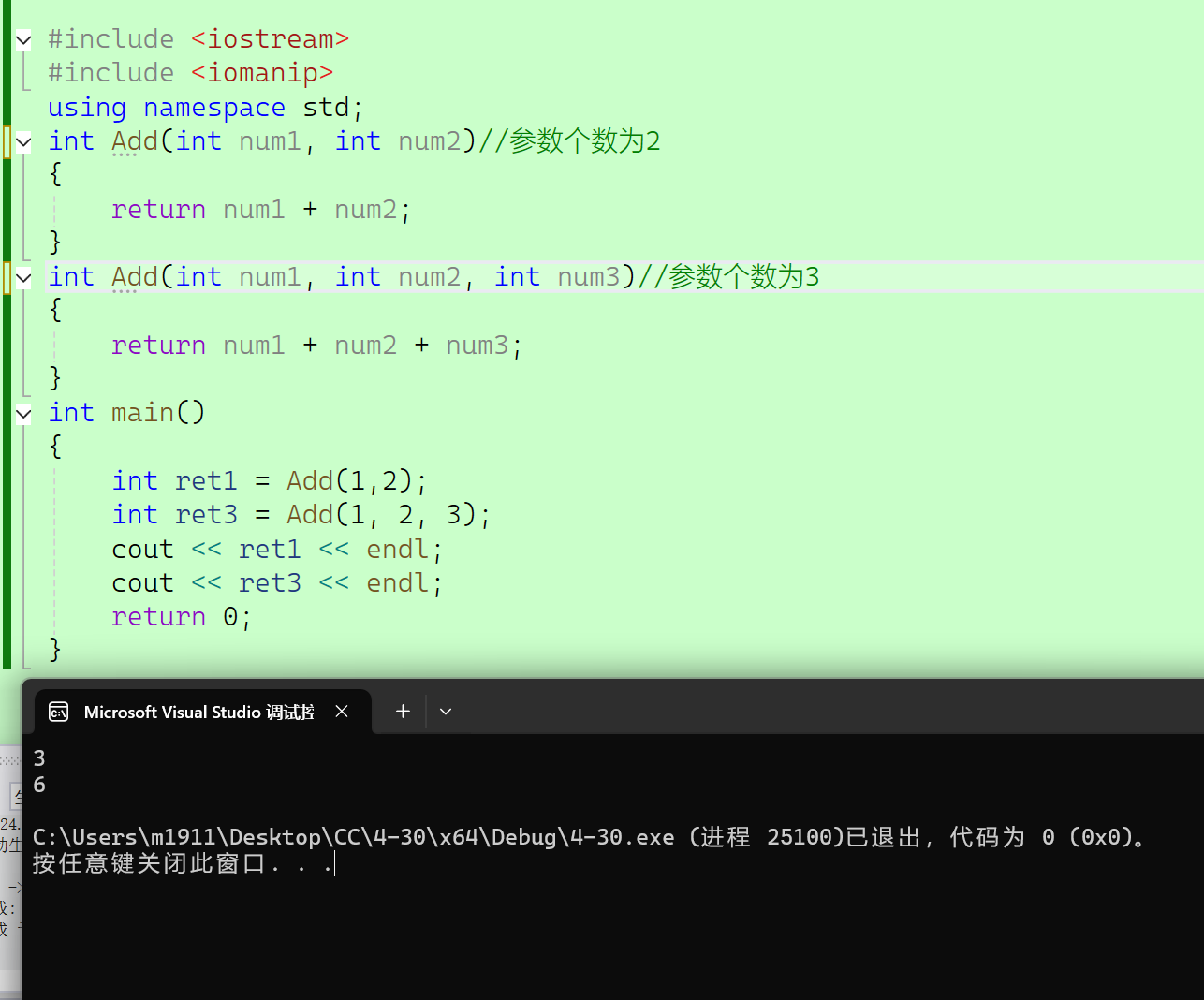
//参数个数不同
#include <iostream>
#include <iomanip>
using namespace std;
int Add(int num1, int num2)//参数个数为2
{return num1 + num2;
}
int Add(int num1, int num2, int num3)//参数个数为3
{return num1 + num2 + num3;
}
int main()
{int ret1 = Add(1,2);int ret3 = Add(1, 2, 3);cout << ret1 << endl;cout << ret3 << endl;return 0;
}
2.2.3 避坑注意
2.2.3.1无参与有参
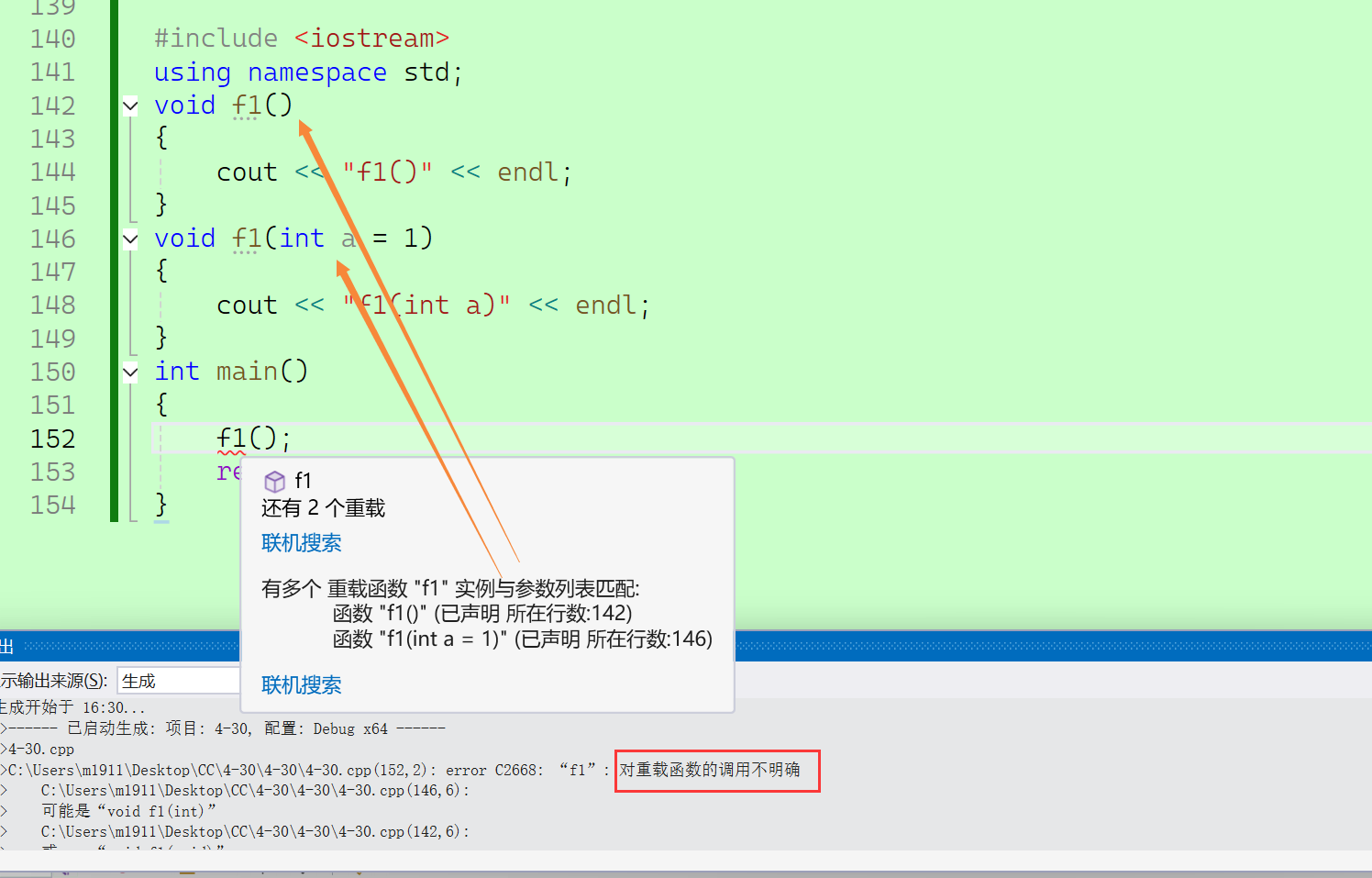
这样两个函数进行重载会产生歧义并且报错,因为编译器不知道应该调用哪一个。
2.2.3.2 返回值不同
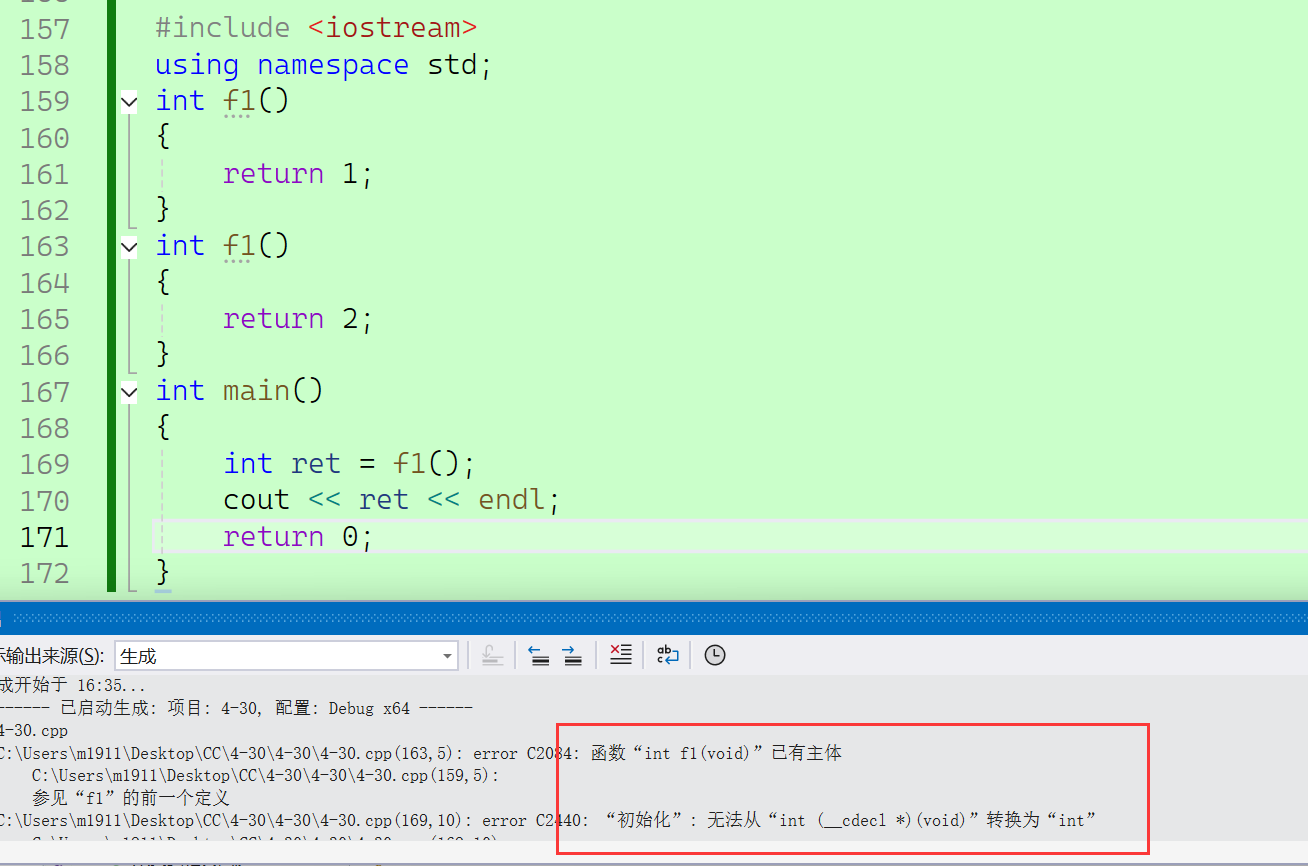
返回值不同不能作为函数重载的条件,因为编译器也不知道应该用谁。
2.3 引用
2.3.1 引用的概念
在C语言中,我们在学习指针的时候经常用到一个操作符&——取地址操作符。但是在C++语法中,它却又有了另外一种定义——引用。
引用不是定义一个新的变量,而是给已有的变量取一个别名,这个别名和它指向的变量共用同一块空间。编译器也不会因为引用而开辟新的空间。
说到这里你可能还是会有点懵逼,那我们就来举个例子吧。最近很火的一部动漫——不良人,相信大家都有一定的了解吧。里面的主角本名叫做李星云,他的手下称李星云为大帅,江湖又称之为天暗星。那么如果李星云一统天下,是不是大帅也一统天下了呢?那天暗星又有没有一统天下呢?其实本质上——李星云、大帅、天暗星所指代的都是同一个个体,只是具体叫法多样化了而已。
2.3.2引用的结构
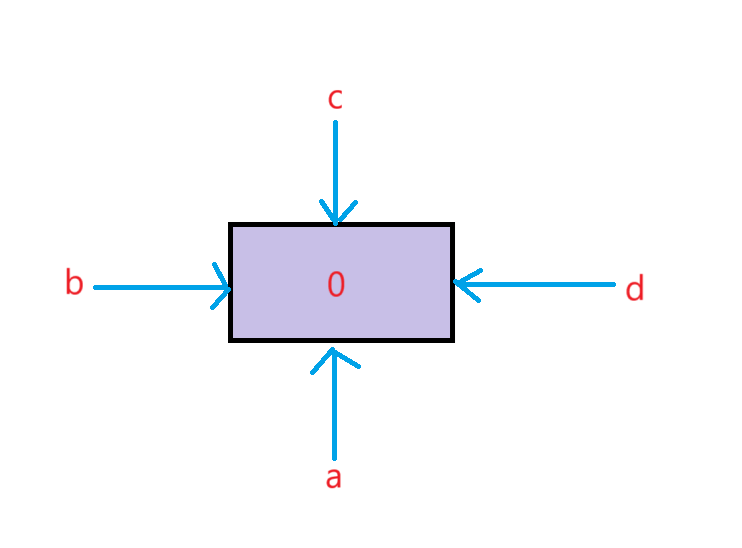
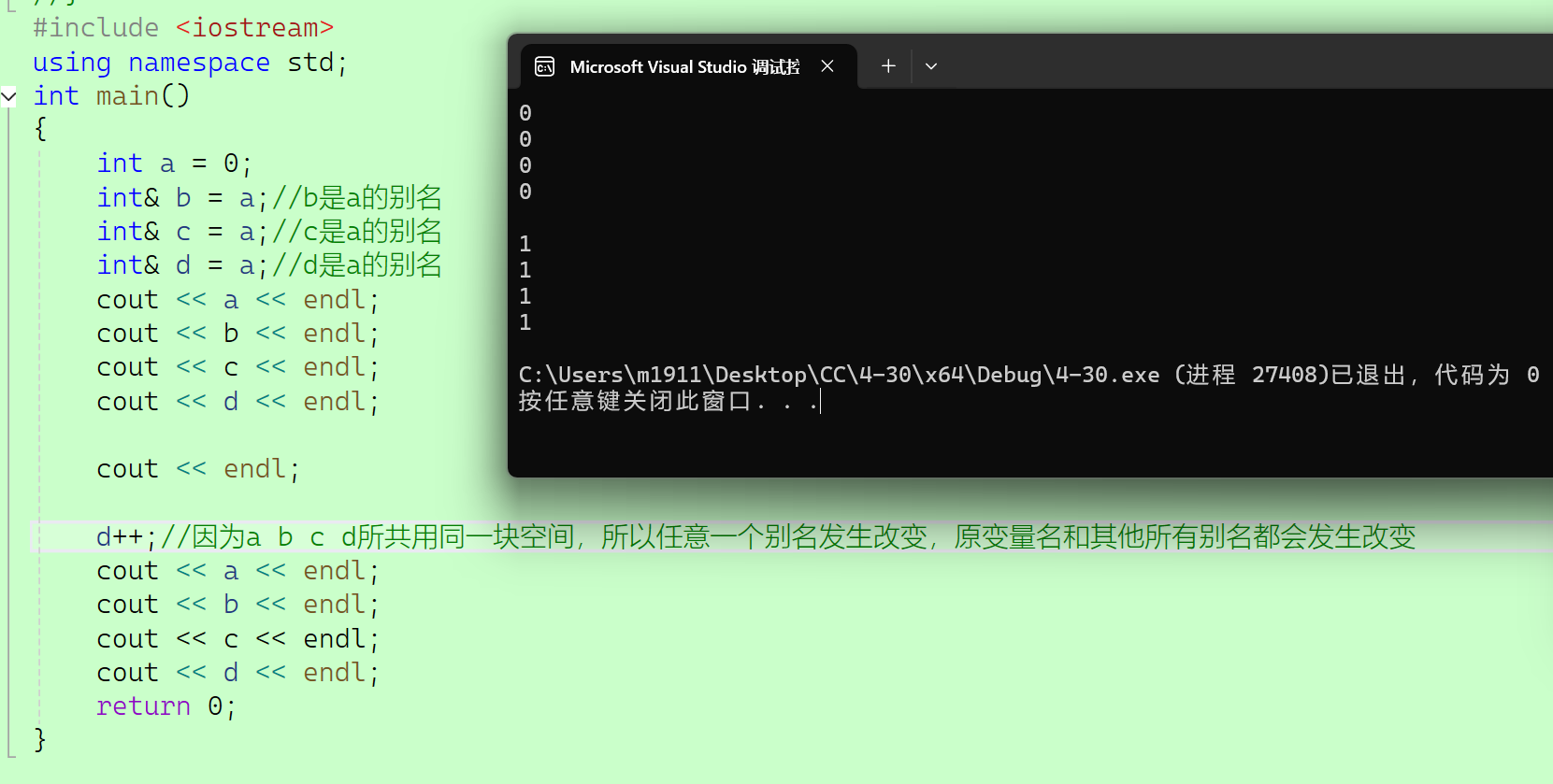
#include <iostream>
using namespace std;
int main()
{int a = 0;int& b = a;//b是a的别名int& c = a;//c是a的别名int& d = a;//d是a的别名cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;cout << endl;d++;//因为a b c d所共用同一块空间,所以任意一个别名发生改变,原变量名和其他所有别名都会发生改变cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;return 0;
}
2.3.3 引用的特点
1、引用在定义时必须初始化;
2、对同一个变量可以进行多次引用;
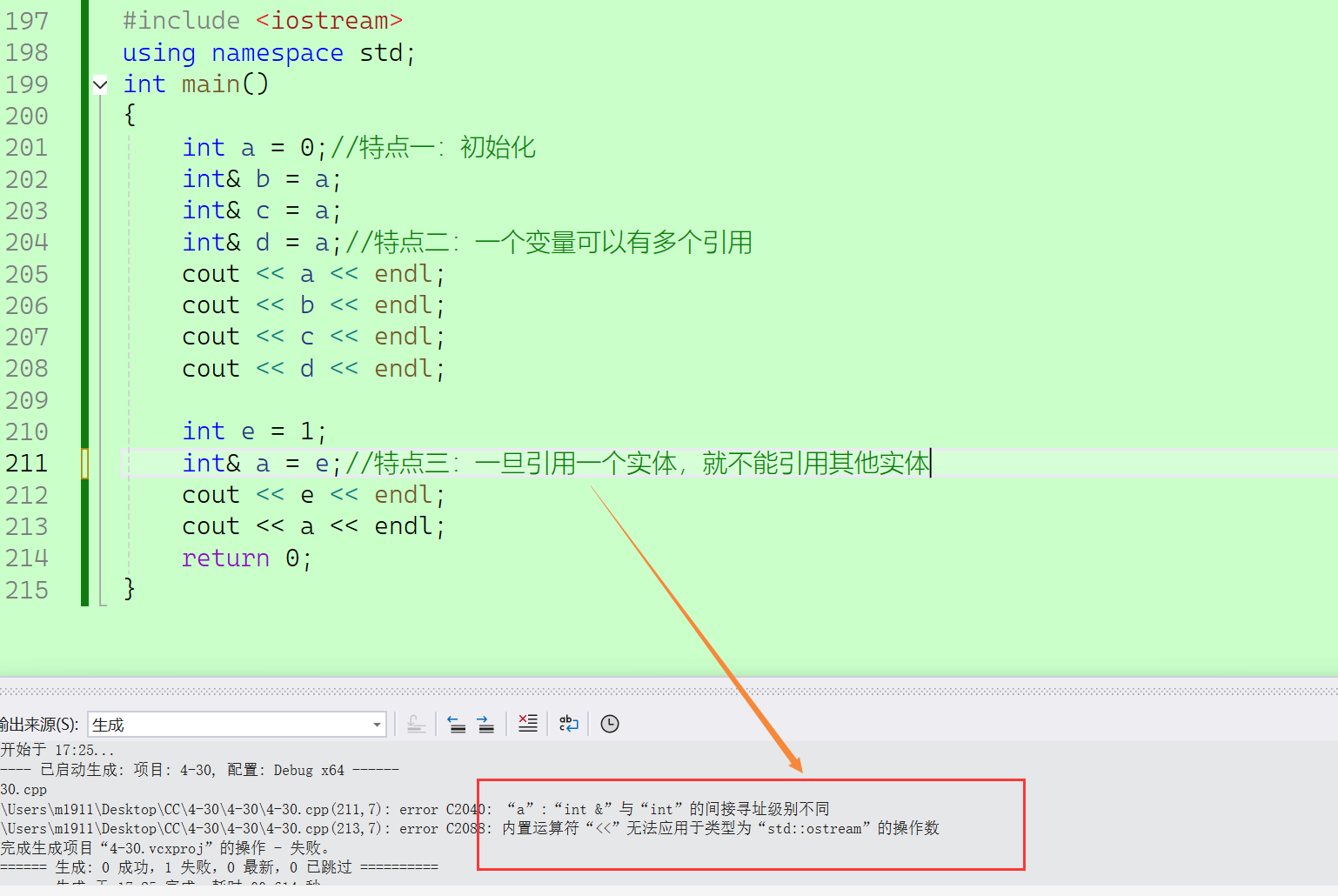
3、一旦引用了一个实体,就不能引用其他实体。
2.3.4引用的作用
2.3.4.1 作用一
作函数形参,通过形参影响实参。
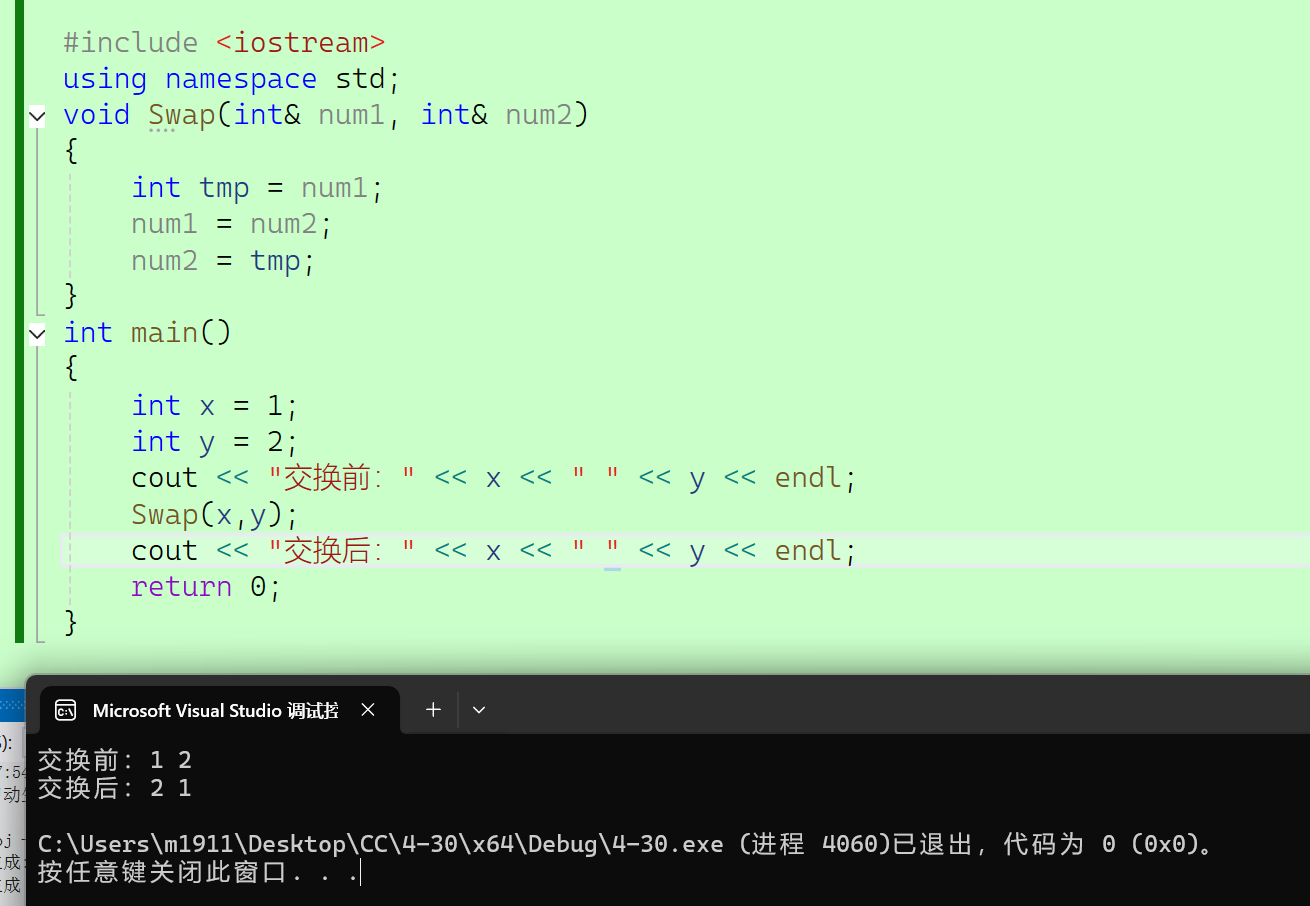
#include <iostream>
using namespace std;
void Swap(int& num1, int& num2)
{int tmp = num1;num1 = num2;num2 = tmp;
}
int main()
{int x = 1;int y = 2;cout << "交换前:" << x << " " << y << endl;Swap(x,y);cout << "交换后:" << x << " " << y << endl;return 0;
}
2.3.4.2 作用二
作函数形参,减少拷贝,提高效率
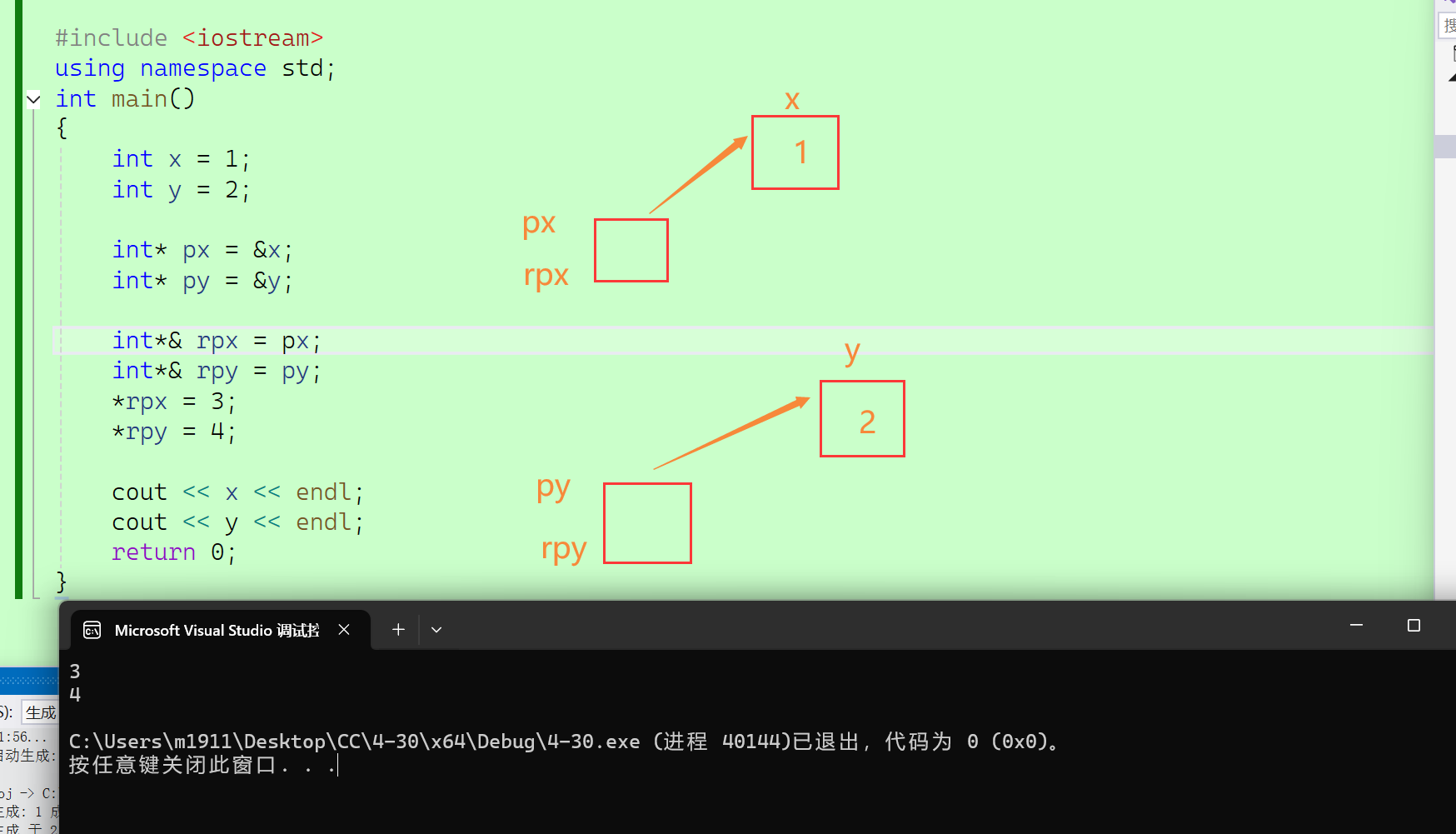
#include <iostream>
using namespace std;
int main()
{int x = 1;int y = 2;int* px = &x;int* py = &y;int*& rpx = px;int*& rpy = py;*rpx = 3;*rpy = 4;cout << x << endl;cout << y << endl;return 0;
}
2.3.4.3 作用三
做返回值类型,修改返回对象。
头文件:

主体代码文件:
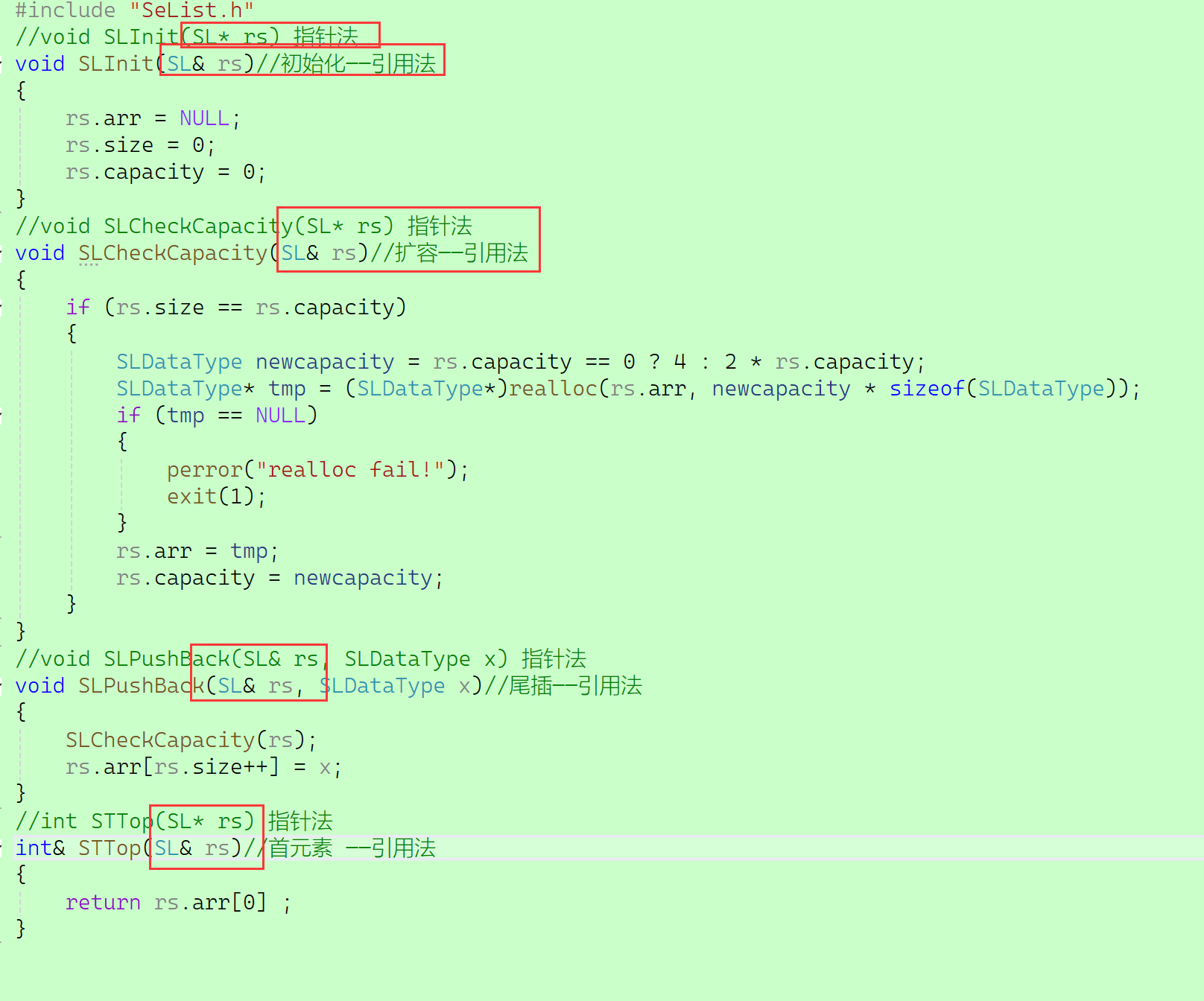
测试文件:
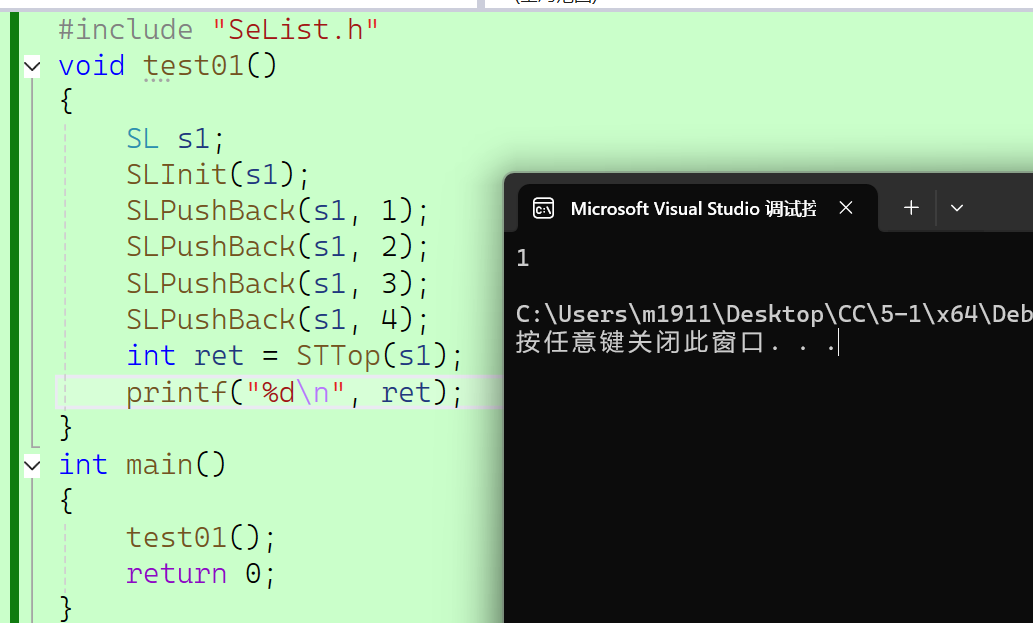
可以看出代码可以正确运行,无报错。
//SeList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
typedef int SLDataType;
struct Sequelist
{SLDataType* arr;int size;int capacity;
};
typedef struct Sequelist SL;
void SLInit(SL& rs);
void SLPushBack(SL& rs, SLDataType x);
int& STTop(SL& rs);//SeList.cpp
#include "SeList.h"
//void SLInit(SL* rs) 指针法
void SLInit(SL& rs)//初始化——引用法
{rs.arr = NULL;rs.size = 0;rs.capacity = 0;
}
//void SLCheckCapacity(SL* rs) 指针法
void SLCheckCapacity(SL& rs)//扩容——引用法
{if (rs.size == rs.capacity){SLDataType newcapacity = rs.capacity == 0 ? 4 : 2 * rs.capacity;SLDataType* tmp = (SLDataType*)realloc(rs.arr, newcapacity * sizeof(SLDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}rs.arr = tmp;rs.capacity = newcapacity;}
}
//void SLPushBack(SL& rs, SLDataType x) 指针法
void SLPushBack(SL& rs, SLDataType x)//尾插——引用法
{SLCheckCapacity(rs);rs.arr[rs.size++] = x;
}
//int STTop(SL* rs) 指针法
int& STTop(SL& rs)//首元素 ——引用法
{return rs.arr[0] ;
}
test.cpp
#include "SeList.h"
void test01()
{SL s1;SLInit(s1);SLPushBack(s1, 1);SLPushBack(s1, 2);SLPushBack(s1, 3);SLPushBack(s1, 4);int ret = STTop(s1);printf("%d\n", ret);
}
int main()
{test01();return 0;
}
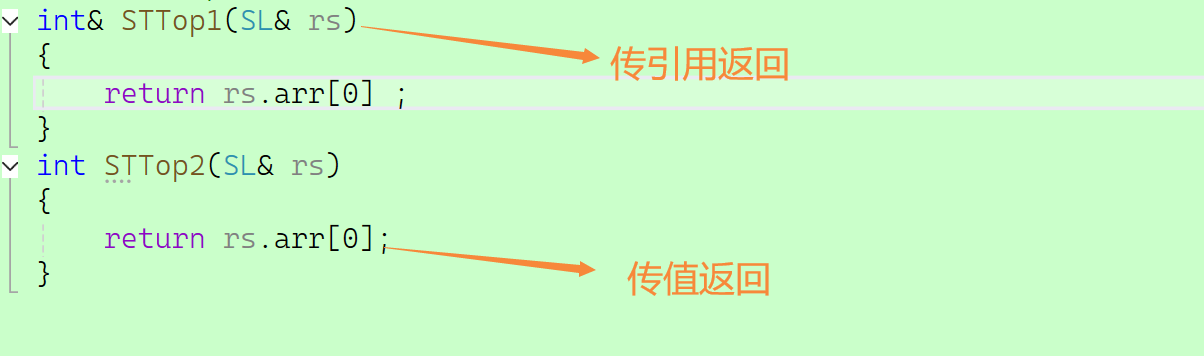
2.3.4.4 作用四
做返回值类型,减少拷贝,提高效率。
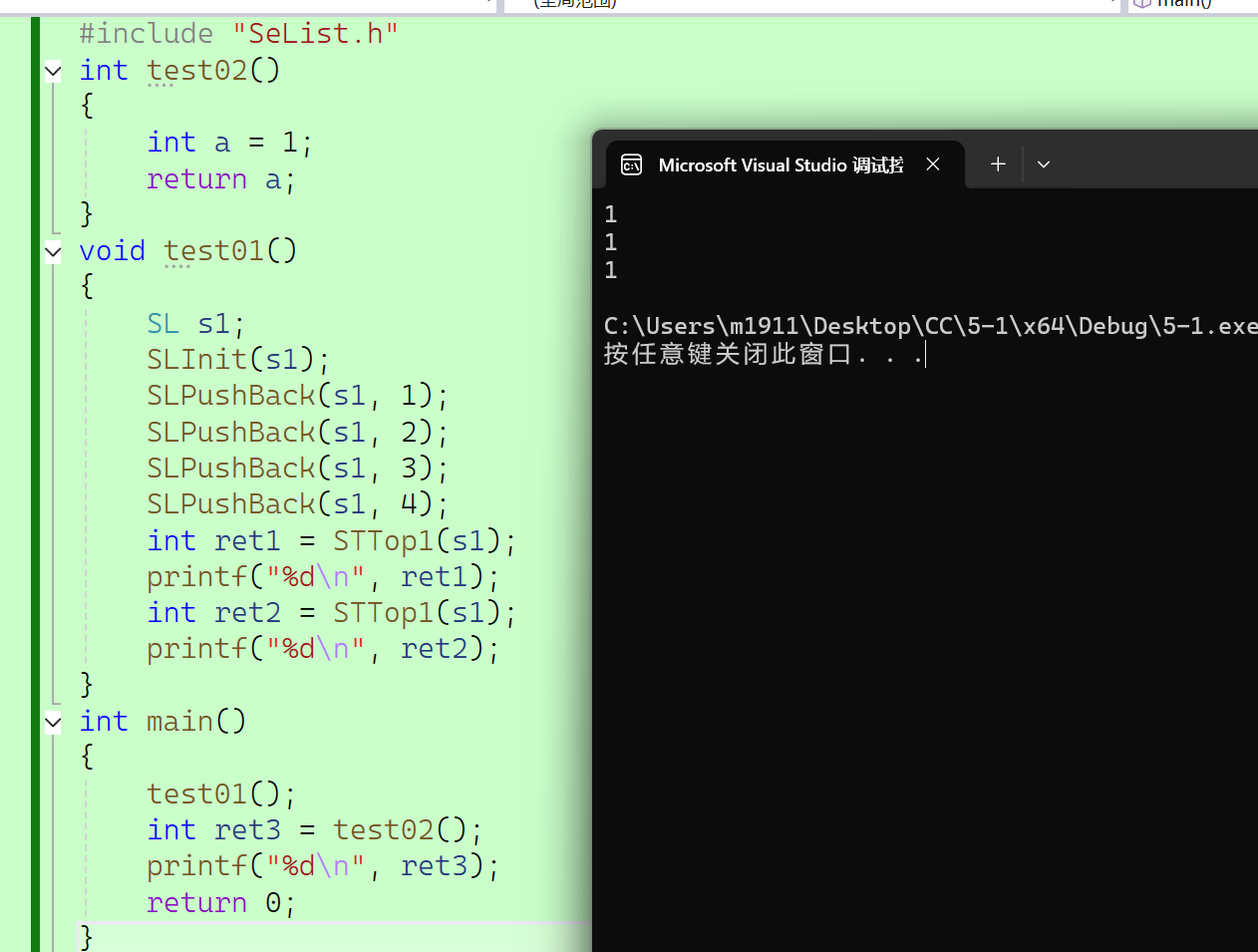
//主体代码文件
//头文件
#pragma once
#include <stdio.h>
#include <stdlib.h>
typedef int SLDataType;
struct Sequelist
{SLDataType* arr;int size;int capacity;
};
typedef struct Sequelist SL;
void SLInit(SL& rs);
void SLPushBack(SL& rs, SLDataType x);
int& STTop1(SL& rs);
int& STTop(SL& rs);
#include "SeList.h"
//void SLInit(SL* rs) 指针法
void SLInit(SL& rs)//初始化——引用法
{rs.arr = NULL;rs.size = 0;rs.capacity = 0;
}
//void SLCheckCapacity(SL* rs) 指针法
void SLCheckCapacity(SL& rs)//扩容——引用法
{if (rs.size == rs.capacity){SLDataType newcapacity = rs.capacity == 0 ? 4 : 2 * rs.capacity;SLDataType* tmp = (SLDataType*)realloc(rs.arr, newcapacity * sizeof(SLDataType));if (tmp == NULL){perror("realloc fail!");exit(1);}rs.arr = tmp;rs.capacity = newcapacity;}
}
//void SLPushBack(SL& rs, SLDataType x) 指针法
void SLPushBack(SL& rs, SLDataType x)//尾插——引用法
{SLCheckCapacity(rs);rs.arr[rs.size++] = x;
}
//int STTop(SL* rs) 指针法
int& STTop1(SL& rs)
{return rs.arr[0] ;
}
int STTop2(SL& rs)
{return rs.arr[0];
}
//测试文件
#include "SeList.h"
int test02()
{int a = 1;return a;
}
void test01()
{SL s1;SLInit(s1);SLPushBack(s1, 1);SLPushBack(s1, 2);SLPushBack(s1, 3);SLPushBack(s1, 4);int ret1 = STTop1(s1);printf("%d\n", ret1);int ret2 = STTop1(s1);printf("%d\n", ret2);
}
int main()
{test01();int ret3 = test02();printf("%d\n", ret3);return 0;2.4 传值传参、传值返回、传引用返回的区别
在刚刚的引用介绍中,我们大体了解了传值传参、传值返回、传引用返回这三种传值方式。那么这三种方式具体又有什么区别呢?
2.4.1 传值传参

传值传参的过程:在函数被调用结束之后函数栈帧被销毁,需要返回的值实际上被拷贝存储在一个临时变量之中,最后由这个临时变量把返回值传递给接收值。
2.4.2 传值返回
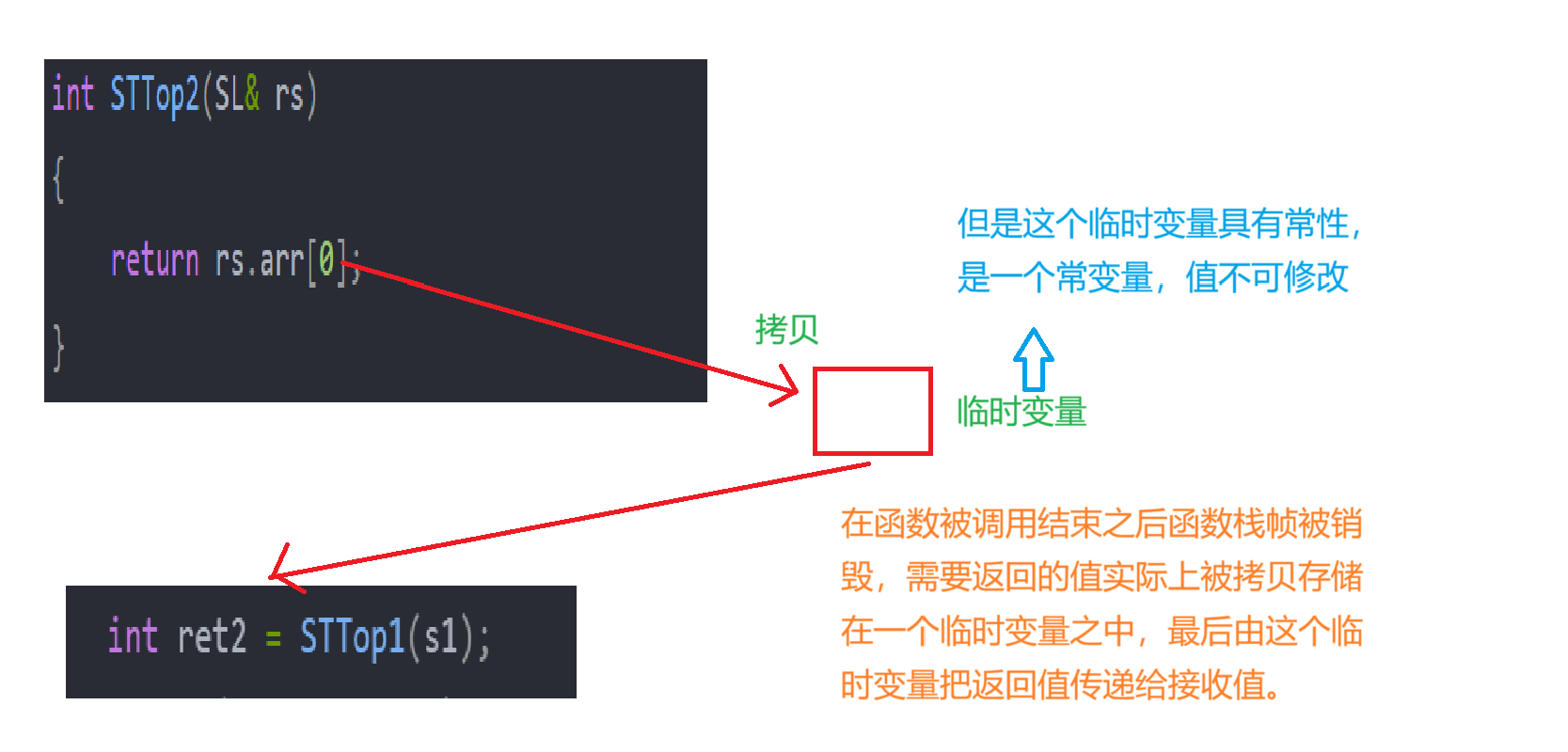
传值返回的实质:在函数被调用结束之后函数栈帧被销毁,需要返回的值实际上被拷贝存储在一个临时变量之(但是注意:这个临时变量具有常性,是一个常变量,值不可修改)中,最后由这个临时变量把返回值传递给接收值。
2.4.3 传引用返回
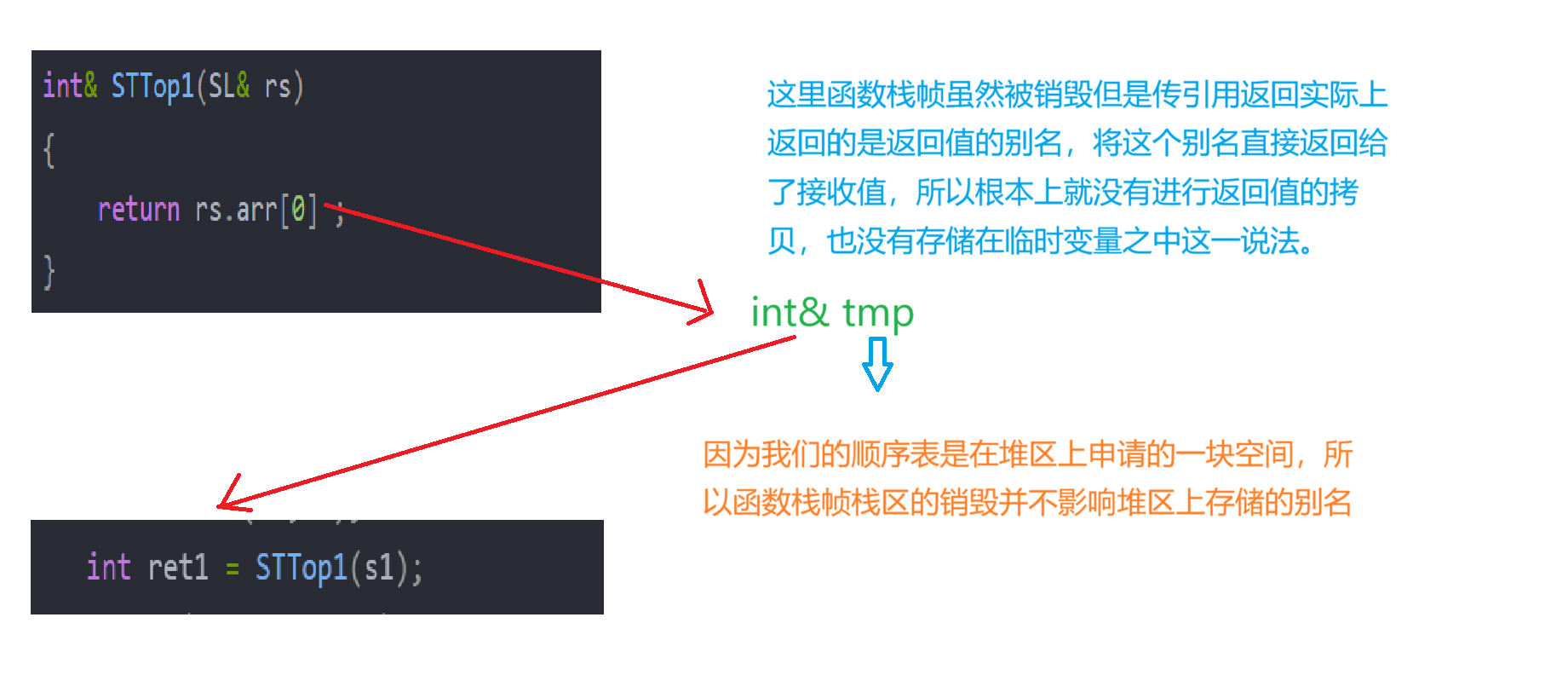
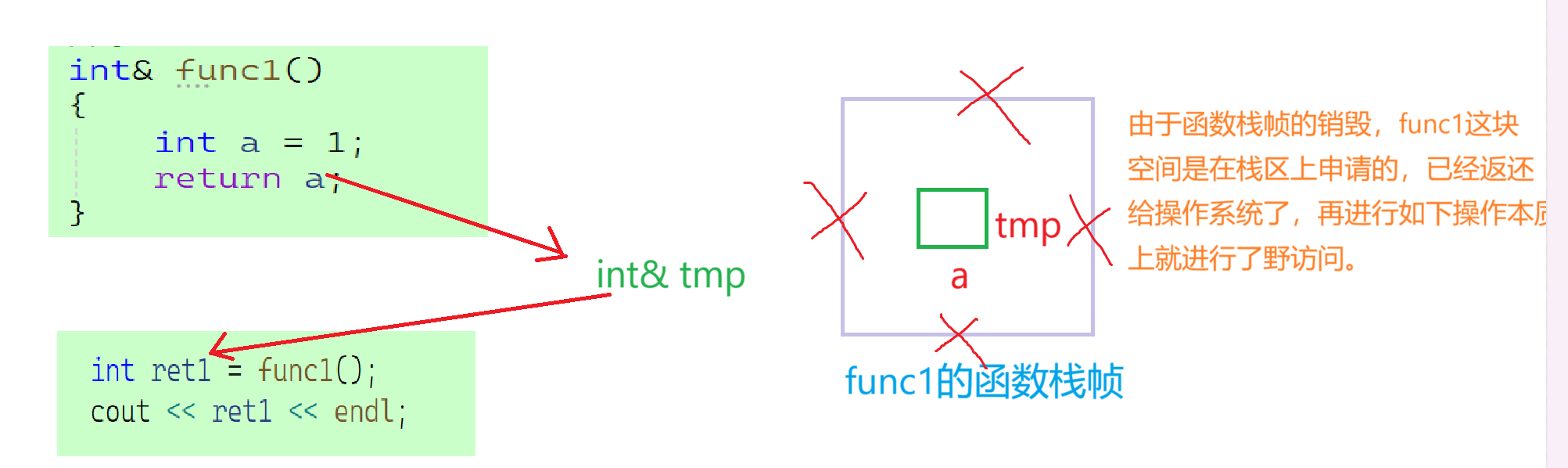
传引用返回的实质:这里函数栈帧虽然被销毁但是传引用返回实际上返回的是返回值的别名,将这个别名直接返回给
了接收值,所以根本上就没有进行返回值的拷贝,也没有存储在临时变量之中这一说法。
注意:因为我们的顺序表是在堆区上申请的一块空间,所
以函数栈帧栈区的销毁并不影响堆区上存储的别名。
综上:由这三种传值方式的区别加以印证了引用做返回值类型,可以减少拷贝,提高效率。
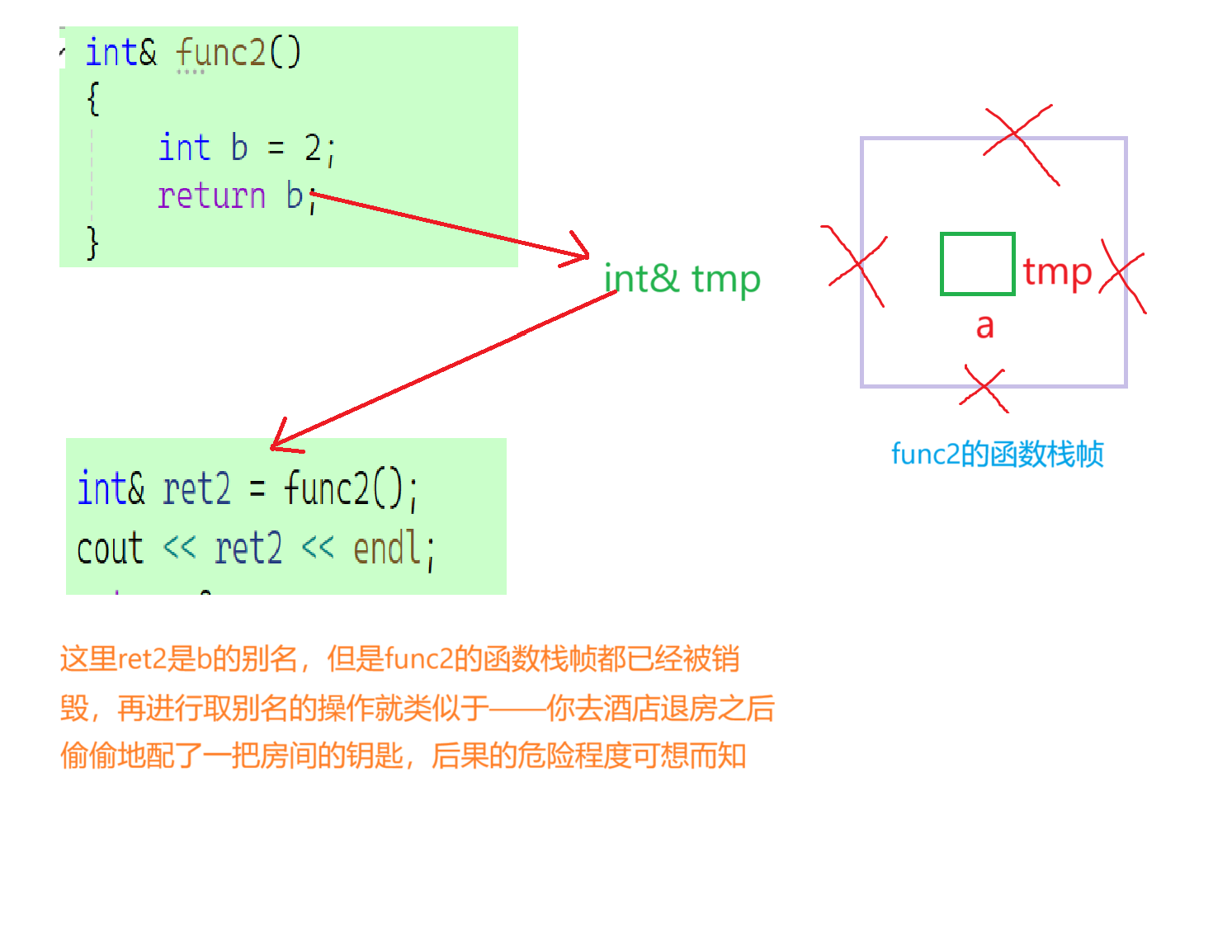
2.4.4 传引用返回的误用
但是如果申请的空间就是在栈区上,那么你可就大错特错了。如下:
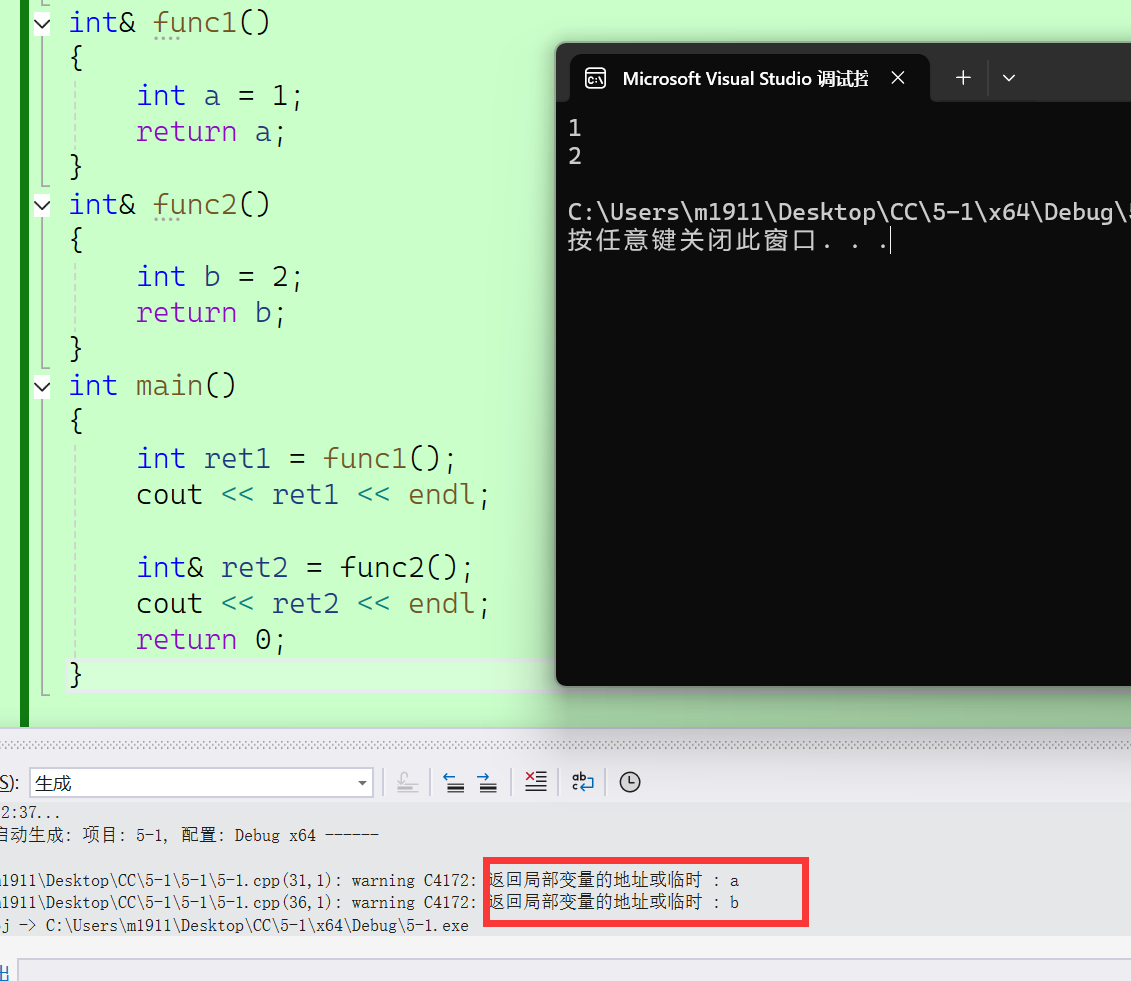
虽然此处编译通过但是存在非常大的潜在危险。
危险一:
危险二:
2.5 const引用
2.5.1 const引用的概念
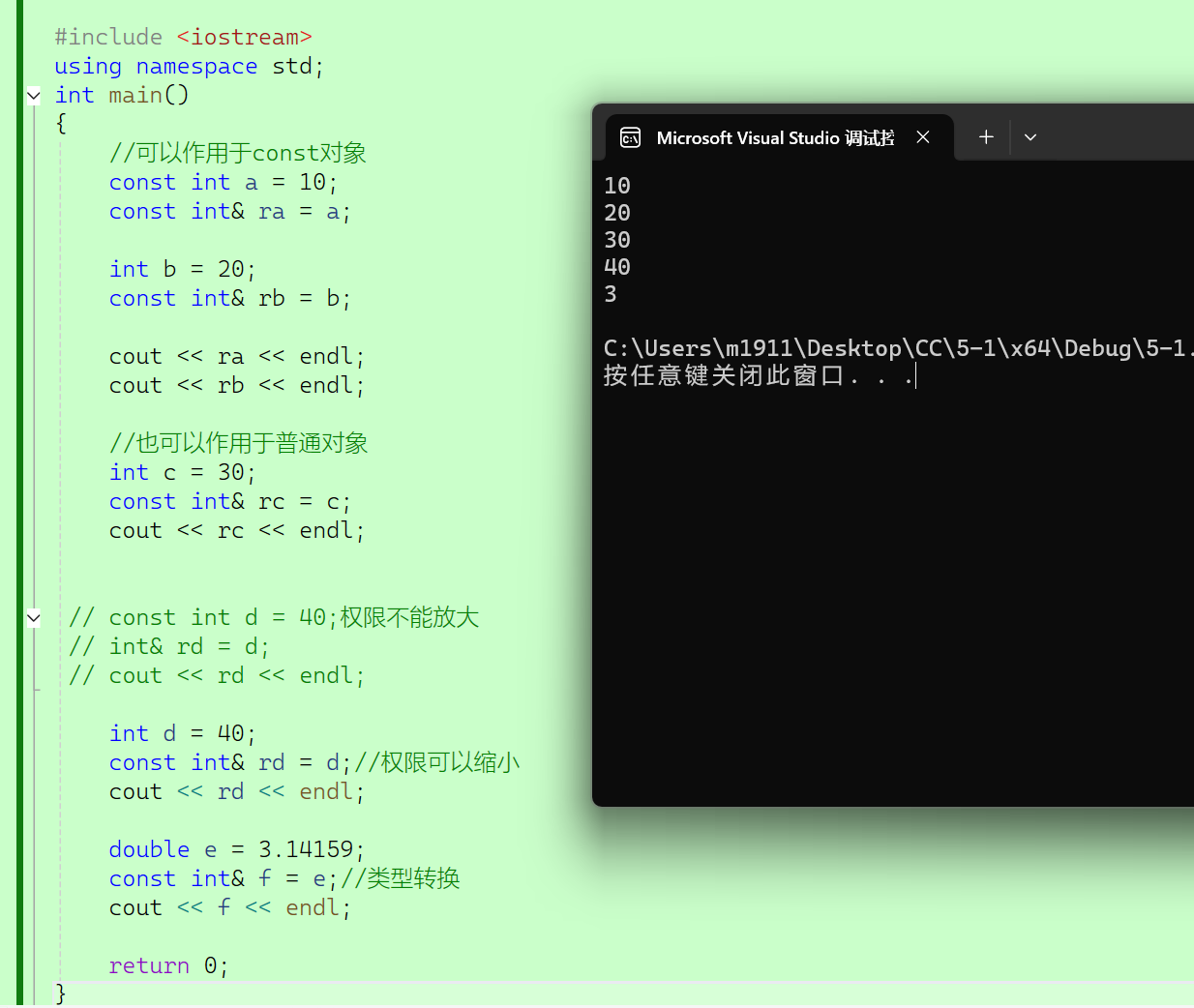
1、可以引用一个cosnt对象,但是必须用const引用。const引用也可以作用于普通对象。
2、const引用中对象的访问权限可以缩小但是不能扩大。
3、在类型转换的时候会产生临时对象存储中间值,为了避免权限放大也要加上常引用。
2.5.2 const引用的用法
#include <iostream>
using namespace std;
int main()
{//可以作用于const对象const int a = 10;const int& ra = a;int b = 20;const int& rb = b;cout << ra << endl;cout << rb << endl;//也可以作用于普通对象int c = 30;const int& rc = c;cout << rc << endl;// const int d = 40;权限不能放大// int& rd = d;// cout << rd << endl;int d = 40;const int& rd = d;//权限可以缩小cout << rd << endl;double e = 3.14159;const int& f = e;//类型转换cout << f << endl;return 0;
}
2.6 inline
1、内联函数是C++中的一个特性,它允许程序员建议编译器在每个函数调用点直接插入函数的代码,而不是进行常规的函数调用。这是通过在函数声明前添加inline关键字来实现的。内联函数的主要目的是为了减少函数调用时的开销,特别是在函数体较小且被频繁调用的情况下。
2、当编译器处理内联函数时,它会尝试将函数的代码直接插入到每个调用点。这意味着函数的执行不需要跳转到另一个内存位置,也不需要进行常规的栈操作(如参数传递、返回地址保存等),从而节省了这些操作所需的时间。然而,内联仅仅是对编译器的一个建议,编译器可能会因为各种原因(如函数体过大或包含复杂的控制流语句)而决定不内联某个函数。
3、优点包括减少函数调用的开销,提高程序的运行效率,以及优化内存访问的局部性。然而,内联函数也有其缺点,如可能增加可执行程序的大小,导致物理内存不足,以及当内联函数定义改变时,需要重新编译整个程序。
4、内联函数适用于函数体较小(通常不超过10行)的函数,尤其是那些被频繁调用的函数。例如,一个简单的数学计算或访问器(getter/setter)函数可能是内联的良好候选。然而,不应该内联包含循环、switch语句或递归调用的函数,因为这可能导致代码膨胀,从而降低程序的效率。
2.7 nullptr
2.7.1 nullptr的概念
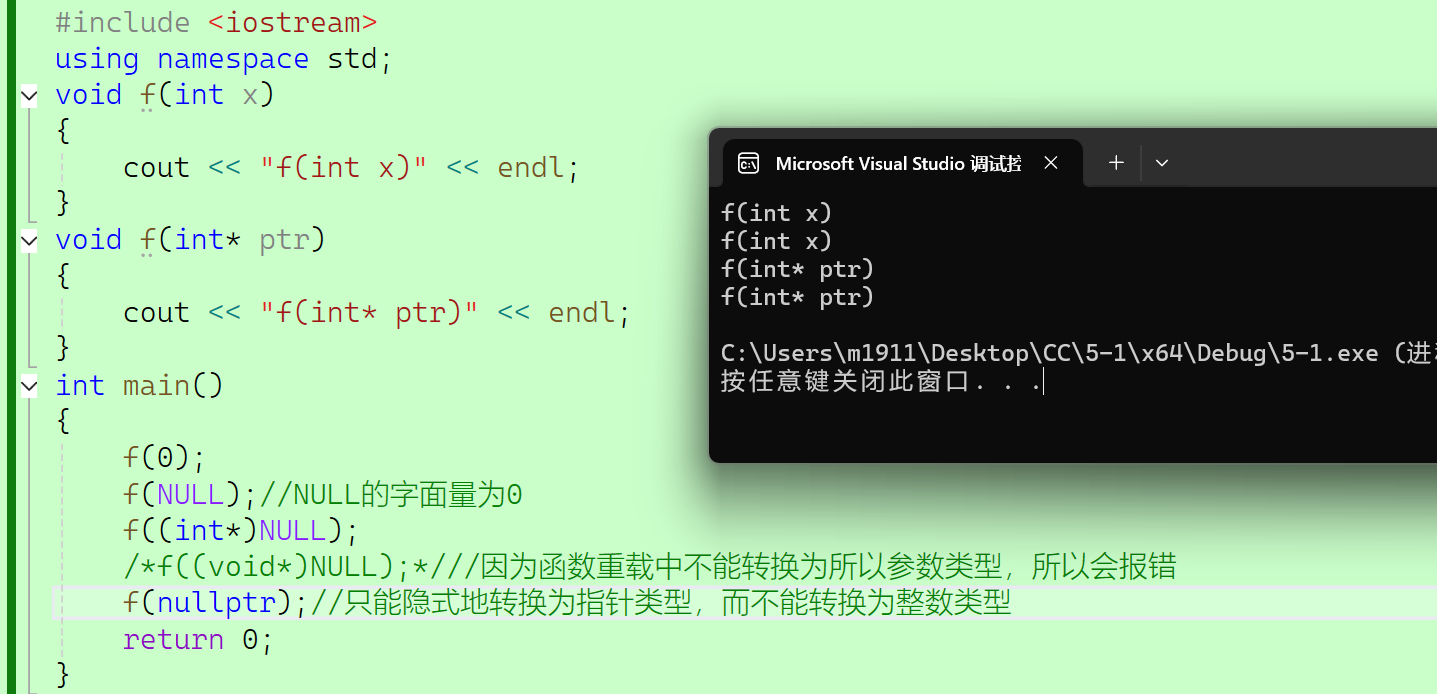
1、在C语言中我们经常会用到NULL,NULL实际上是一个宏。
2、在C++中NULL可能被定义为字面常量0,或者C中被定义为无类型(void*)的常量,但是不可否认对空值进行解引用时,会遇到一些不必要的麻烦。
3、C++语法规定nullptr是一个特殊的关键字,是一种特殊类型的字面量,可以转换成其他任意类型的指针类型。所以使用nullptr定义空指针就可以避免类型转换的问题,因为nullptr只能隐式地转换为指针类型,而不能转换为整数类型。
2.7.2 nullptr的用法
#include <iostream>
using namespace std;
void f(int x)
{cout << "f(int x)" << endl;
}
void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}
int main()
{f(0);f(NULL);//NULL的字面量为0f((int*)NULL);/*f((void*)NULL);*///因为函数重载中不能转换为所以参数类型,所以会报错f(nullptr);//只能隐式地转换为指针类型,而不能转换为整数类型return 0;
}
三、总结
好啦到目前为止,C++入门基础的所有语法就全部讲解完毕了。这就意味着我们已经两只脚都跨入了C++的门槛,以后的知识也会逐一递增。另外今天的知识分享确实有很大的难度,希望大家静下心来,好好沉淀,为以后成为一个C++大拿打下坚实的基础。
学习如磨刀,虽苦却利,持之以恒,必成大器。