数据结构学习篇——哈希
哈希的概念与结构
- 若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
- 对不同的关键字可能得到同一散列地址,即 k 1 ≠ k 2 k1≠k2 k1=k2,而 f ( k 1 ) = f ( k 2 ) f(k1)=f(k2) f(k1)=f(k2),这种现象称为冲突(英语:Colision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数 f ( k ) f(k) f(k)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
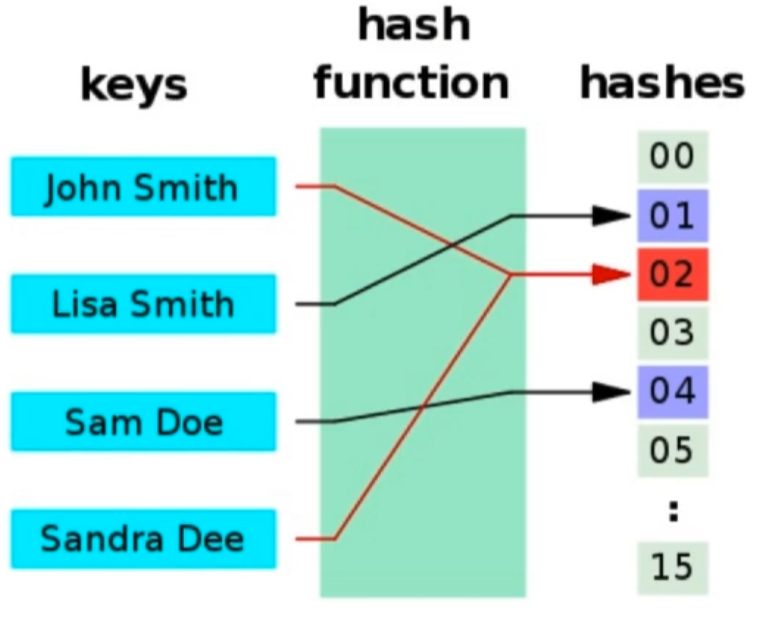
哈希表的两个关键
- 散列函数
直接定址法
数字分析法
平方取中法
折叠法
随机数法
除留余数法 - 冲突解决
开放定址法
拉链法
双散列
再散列
实现一个HashMap
思路:实现HashMap首先确定结构为数组+链表,桶排序用的就是这个结构。其次保存数据时需要先对桶的下标做一个哈希运算,这里采用除留余数法。然后遇到哈希冲突时,采用了拉链法形成一个列表结构依次往下新增。整体来说,里面基于链表的处理比较多。
public class MyHashMap<K,V> implements IMap<K,V>{Node<K,V>[] buckets;int capacity;int size;public MyHashMap() {this.capacity = 16;this.buckets = new Node[capacity];this.size = 0;}@Overridepublic void clear() {for (int i = 0; i < buckets.length; i++) {buckets[i] = null;}}@Overridepublic boolean containsKey(K key) {int index = hash(key);if (buckets[index] == null) {return false;} else {Node<K, V> p = buckets[index];//相当于在链表中找keywhile (p != null) {K k1 = p.key;//借用java机制,hashcode和equals都来自于Object,用户可以改写这两个方法——制定对象相等的规则if (k1 == key || (k1.hashCode() == key.hashCode() && k1.equals(key))) {return true;}p = p.next;}}return false;}@Overridepublic boolean containsValue(V value) {for (int i = 0; i < buckets.length; i++) {Node<K, V> p = buckets[i];while (p != null) {if (Objects.equals(p.value, value))return true;p = p.next;}}return false;}@Overridepublic V get(K key) {int index = hash(key);if (buckets[index] != null){Node<K,V> p = buckets[index];while (p != null){K pkey = p.key;if (key == pkey || (key != null && pkey != null &&key.hashCode() == pkey.hashCode() && Objects.equals(key,pkey))){return p.value;}if (p.next == null){break;}p = p.next;}}return null;}@Overridepublic boolean isEmpty() {return size == 0;}@Overridepublic void put(K key, V value) {int index = hash(key);Node<K, V> node = new Node<>(key, value);if (buckets[index] == null){buckets[index] = node;}else {Node<K,V> p = buckets[index];while (p != null){K pkey = p.key;if (key == pkey || (key != null && pkey != null &&key.hashCode() == pkey.hashCode() && Objects.equals(key,pkey))){p.value = node.value;break;}if (p.next == null){p.next = node;size++;break;}p = p.next;}}}private int hash(K key) {if (key == null) return 0; // 或者根据设计决定如何处理 null 键//位运算正数return (key.hashCode() & 0x7FFFFFFF) % capacity;}@Overridepublic void putAll(IMap<? extends K, ? extends V> map) {}@Overridepublic V remove(K key) {int index = hash(key);if (buckets[index] != null){Node<K,V> p = buckets[index];Node<K,V> pre = p;while (p != null){K pkey = p.key;if (key == pkey || (key != null && pkey != null &&key.hashCode() == pkey.hashCode() && Objects.equals(key,pkey))){//移除if (p == pre) {buckets[index] = pre.next;} else {pre.next = p.next;}size--;return p.value;}pre = p;p = p.next;}}return null;}@Overridepublic int size() {return size;}@Overridepublic V[] values() {return null;}private class MapInterator implements Iterator<Node> {int i = 0;Node p = buckets[0];@Overridepublic boolean hasNext() {while (this.i < capacity && p == null) {this.i++;if (this.i == capacity)p = null;elsep = buckets[this.i];}//i是一个非空的桶,p是链表头return p != null;}@Overridepublic Node next() {Node res = p;p = p.next;return res;}}public class Node<K,V>{K key;V value;Node next;public Node(K key, V value) {this.key = key;this.value = value;}@Overridepublic String toString(){return "BSTNode{" + "key=" + key + ", value=" + value + '}';}}@Overridepublic Iterator<Node> iterator() {return new MapInterator();}
}
以上实现基于固定长度的数组,没有实现扩容。以下为JAVA对HashMap的优化:
- HashMap的负载因子为0.75,桶中元素超过这个值时会进行扩容,且元素重新计算哈希值。
- 链表元素超过8个会变成红黑树。
- 哈希函数的优化,key.hashCode()是一个32位的int值,做了位运算后再取模。
常见的哈希算法
常见的如:取模、加每个字符、位运算二进制、乘素数等。目的都是让桶中的值分散更均匀,尽量避免冲突影响性能。
public class HashFunctions {/*取余法*/static int hash1(Object x, int prime) {return x.hashCode() % prime;}/*加法*/static int additiveHash(Object key, int prime) {String objStr = key.toString();int hash = objStr.length(), i = 0;//遍历每个字符for (; i < objStr.length(); i++)hash += objStr.charAt(i);return (hash % prime);}/*利用位运算*/static int rotatingHash(String key, int prime) {int hash = key.length(), i = 0;for (; i < key.length(); ++i)hash = (hash << 4) ^ (hash >> 28) ^ key.charAt(i);return (hash % prime);}/*乘法*/static long bernstein(String key, int prime) {long h = 0;long seed = 31;//素数for (int i = 0; i != key.length(); ++i) {h = seed * h + key.charAt(i);}return h % prime;}
}