读论文笔记-CoOp:对CLIP的handcrafted改进
读论文笔记-Learning to Prompt for Vision-Language Models
Problems
现有基于prompt engineering的多模态模型在设计合适的prompt时有很大困难,从而设计了一种更简单的方法来制作prompt。
Motivations
- prompt engineering虽然促进了视觉表示的学习,实现了zero-shot迁移到其他任务上,但设计合适的prompt耗时费力。
- NLP领域提供了用连续提示词来改善离散prompt的方法,但也有无法解释到底学到了什么词的缺陷。
Methods
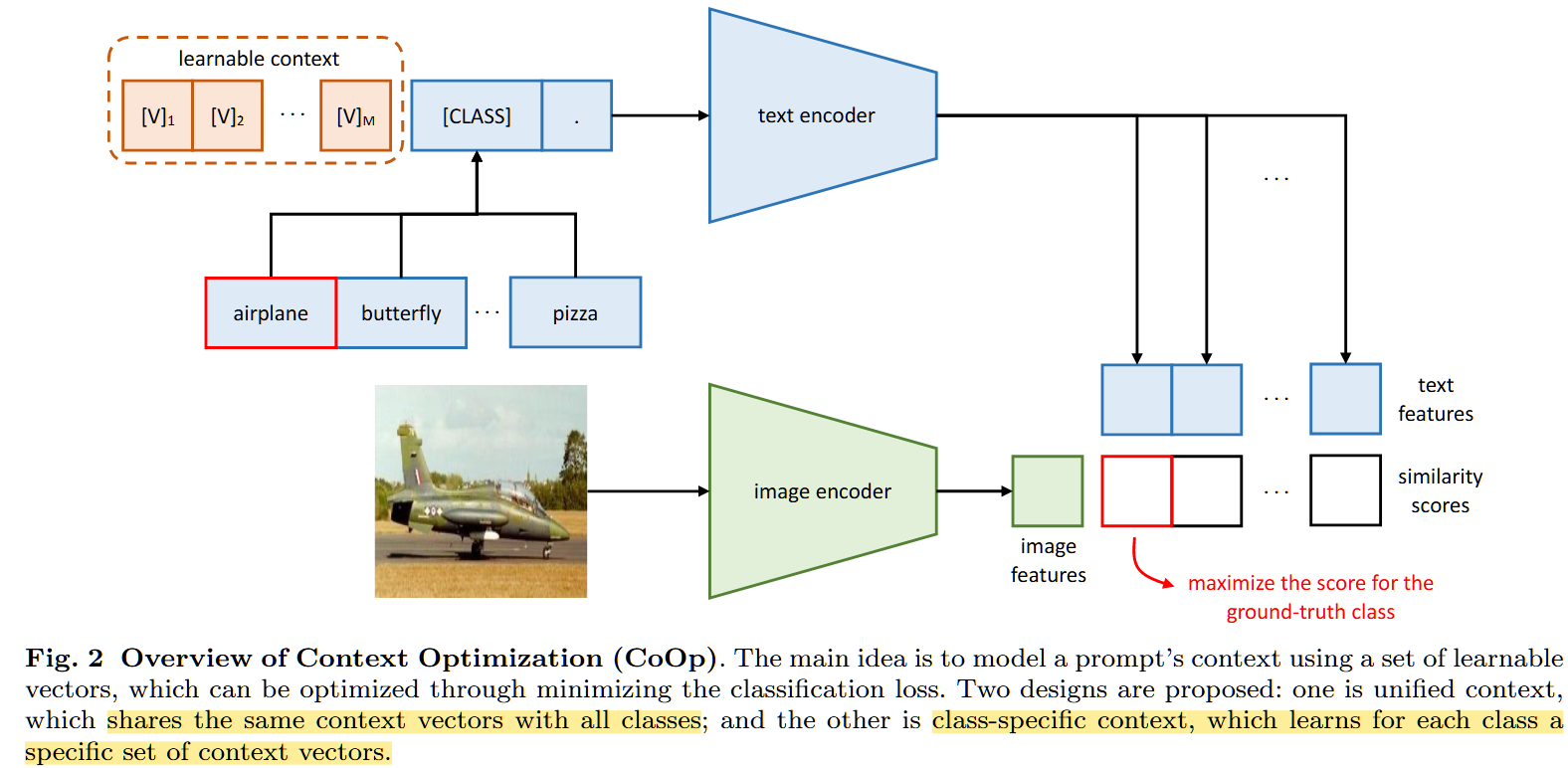
Key:初始化连续向量建模上下文,并通过大量数据进行学习,实现prompt的自动学习。提出统一上下文unified context和特定类别上下文specific context两种prompt。
- unified context的形式:
t = [ v ] 1 [ v ] 2 [ v ] 3 . . . [ v ] M [ C L A S S ] t=[v]_1[v]_2[v]_3...[v]_M[CLASS] t=[v]1[v]2[v]3...[v]M[CLASS]
[ v ] M [v]_M [v]M是与词嵌入相同维度的向量,个数M是一个超参数, [ C L A S S ] [CLASS] [CLASS]是类别标签对应的词嵌入向量,也可以放在中间。可学习向量和类别对应的词向量是concatenate从而形成提示词t的。 - specified context的形式:
t = [ v ] 1 i [ v ] 2 i [ v ] 3 i . . . [ v ] M i [ C L A S S ] t=[v]_1^i[v]_2^i[v]_3^i...[v]_M^i[CLASS] t=[v]1i[v]2i[v]3i...[v]Mi[CLASS]
对于不同的类别所使用的可学习向量都是不同的。
网络结构:和CLIP类似,利用text encoder处理每个类别的prompt t i t_i ti,就是基于一个Transformer的结构,从[EOS]token中得到能表示视觉概念的分类权重 g ( t i ) g(t_i) g(ti)。image encoder可以是ResNet或ViT,得到特征f。计算相似度、预测概率:
p ( y = i ∣ x ) = e x p ( c o s ( g ( t i ) , f ) / t ) ∑ j = 1 K e x p ( c o s ( g ( t j ) , f ) / t ) p(y=i|x)=\frac{exp(cos(g(t_i),f)/t)}{\sum_{j=1}^Kexp(cos(g(t_j),f)/t)} p(y=i∣x)=∑j=1Kexp(cos(g(tj),f)/t)exp(cos(g(ti),f)/t)
训练过程:encoders都是冻结参数的,使用的是交叉熵损失函数(是图文对比学习方法,我理解的就是余弦相似度+交叉熵损失=对比学习损失),反向传播更新context的参数。
Experiments
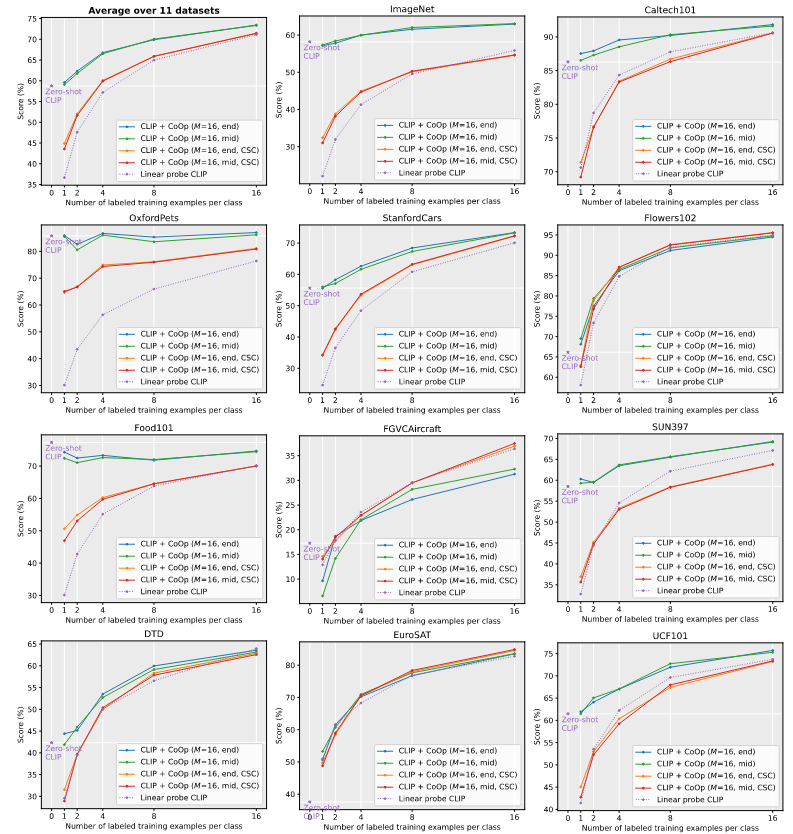
- 比较在少样本学习设置下,模型的小样本学习能力:
- 数据集:和CLIP一样的1个图像分类数据集,组成了一个综合的benchmark;
- 模型结构:vision encoder用的ResNet50,对上下文使用的是均值为0,标准差为0.02的高斯分布初始化,用SGD优化器,使用余弦退火和warmup的技巧。
- 比较的基线模型:零样本的CLIP和线性探针的CLIP
- 对比角度:(1)与使用handcrafted prompt的模型相比(CLIP),在特定任务、细粒度数据集和场景、行为识别的数据集上有更好的效果,但在pest\food这两个数据上提升不明显且有过拟合倾向(作者认为这是因为有脏数据);(2)与线性探针CLIP专门对比:大部分都显著好于,在2个细粒度和特定任务上相当,其中CSC方法能完全超越线性探针模型;(3)比较通用类别和特定类别上下文:通用类别更适合对通用物体、场景和行为上的检测,特定类别上下文适合细粒度的数据集且需要更大的训练数据。
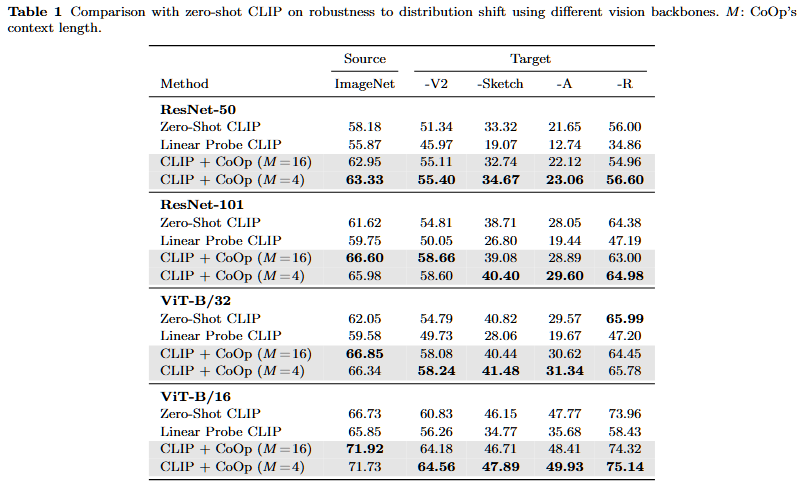
- 在有Domain gap设定下,模型的泛化能力:
- 数据集:源域数据是ImageNet,目标域数据是4个风格不同的ImageNet变体;
- 模型结构:vision encoder是ResNet50/101, ViT-B32/16;
- 结果:CoOp能显著提升模型的泛化能力,而线性探针模型不擅长有域迁移domain shift的场景
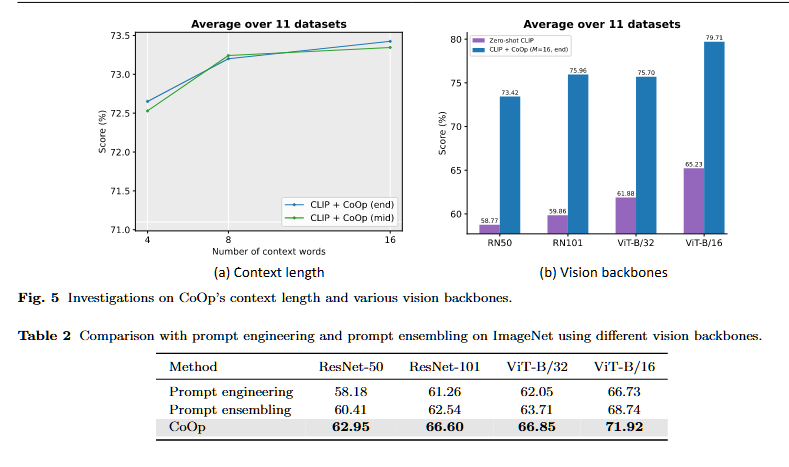
- 超参数选择
- 不同上下文长度(M的大小):更长有更好的效果,当M很大时,[CLASS]在中间位置有更好的效果。但性能好会面对鲁棒性下降。
- 不同vision encoders:更好的vision encoders,CoOp效果更好。
- 与Prompt Ensembling对比:设计连续可学习prompt效果更好。
- 与其他微调方法相比:与原始CLIP、使用线性探针(就是一个线性层,这里可以理解成提取CLIP的特征后输入线性层,训练线性层进行分类)、添加image encoder微调、在text encoder后添加变形层微调、在文本输出添加偏置项的方法进行比较,CoOp的优化上下文方法是最好的色;

- 上下文初始化方法:对CoOp上下文随机初始化和使用CLIP的hand-crafted比较,发现效果差不多,都是很好的上下文,不过后续对CoOp上下文通过学习优化会有更好的效果。
- 对上下文的解释:暂时无法给出解释,因为用距离度量向量的语义是不准确的。