瑞芯微芯片算法开发初步实践
文章目录
- 一、算法开发的一般步骤
- 1.选择合适的深度学习框架
- 2.对于要处理的问题进行分类,是回归问题还是分类问题。
- 3.对数据进行归纳和整理
- 4.对输入的数据进行归一化和量化,保证模型运行的效率和提高模型运行的准确度
- 5.在嵌入式处理器上面运行模型,对嵌入式处理器的整体性能提出了要求
- 6.将通用的算法模型转换成适配嵌入式处理器的模型文件
- 7.对模型的运行效率进行优化
- 二、瑞芯微芯片部署初步尝试
- 总结
一、算法开发的一般步骤
1.选择合适的深度学习框架
(1)TensorFlow 是一个开源的机器学习框架,由 Google Brain 团队开发并维护。它广泛应用于深度学习、数据分析、自然语言处理、计算机视觉等领域,是目前最流行的机器学习框架之一。
TensorFlow 的名字来源于其核心数据结构——张量(Tensor)。张量是一个多维数组,可以表示从标量(0维)到向量(1维)、矩阵(2维)以及更高维度的数据结构。TensorFlow 通过构建一个**计算图(Graph)来描述张量之间的数学运算,然后通过会话(Session)**执行这些运算。
张量(Tensor):数据的载体,是 TensorFlow 中最基本的数据结构。
计算图(Graph):描述张量之间的运算关系,类似于程序的流程图。
会话(Session):用于执行计算图中的运算。
操作(Operation):计算图中的节点,表示对张量的运算。
支持多种语言:TensorFlow 提供了 Python、C++、Java 等多种语言的 API,方便不同开发者使用。
平台无关性:可以在 CPU、GPU、TPU(张量处理单元)等多种硬件上运行,支持桌面、服务器和移动设备。
工具和库:支持与其他工具(如 Keras、TensorBoard 等)无缝集成,方便模型开发和可视化。
(2)PyTorch 是一个开源的机器学习库,广泛用于计算机视觉、自然语言处理等人工智能领域。它由 Facebook 的人工智能研究团队开发,并于 2016 年首次发布。以下是关于 PyTorch 的详细介绍:
动态计算图:
PyTorch 使用动态计算图(Dynamic Computational Graph),允许用户在运行时动态修改计算图的结构。这种灵活性使得调试和开发更加直观,尤其是在处理复杂的模型或动态输入时。
易用性:
PyTorch 提供了简洁直观的 API,类似于 NumPy 的操作方式,使得新手可以快速上手。同时,它也支持自动求导(Autograd)功能,简化了梯度计算的过程。
强大的社区支持:
PyTorch 拥有一个活跃的开源社区,提供了大量的预训练模型、教程和工具。这使得开发者可以快速找到解决方案,并利用社区的力量进行学习和开发。
与 Python 深度集成:
PyTorch 完全基于 Python,与 Python 生态系统无缝对接。它可以与 NumPy、SciPy 等科学计算库以及各种深度学习框架(如 TensorFlow)协同工作。
高效性能:
PyTorch 提供了高效的 GPU 支持,能够充分利用 NVIDIA 的 CUDA 技术加速计算。同时,它也支持分布式训练,适用于大规模数据集和复杂模型的训练。
灵活的扩展性:
PyTorch 允许用户自定义操作和模块,通过扩展 C++ 和 CUDA 代码来实现高性能的自定义功能。
(3)国内有华为的昇思框架。
华为昇思(MindSpore)是华为推出的一个全场景深度学习框架,旨在实现易开发、高效执行和全场景覆盖。
1.主要信息:
昇思MindSpore是一个面向全场景的AI计算框架,支持终端、边缘计算和云端的全场景需求。它具备以下特点:
易开发:提供友好的API和低难度的调试体验。
高效执行:支持高效的计算、数据预处理和分布式训练。
全场景覆盖:支持云、边缘和端侧的多种应用场景。
安全可信:具备企业级的安全特性,保护数据和模型的安全。
2.主要功能
分布式并行能力:支持一行代码自动并行执行,能够训练千亿参数的大模型。
图算深度融合:优化AI芯片的算力,提升计算效率。
动静图统一:兼顾灵活开发与高效运行。
AI + 科学计算:支持生物分子、电磁、流体等领域的科研应用。
多种编程范式:支持面向对象、函数式等多种编程方式。
2.对于要处理的问题进行分类,是回归问题还是分类问题。
回归:预测连续的数值型输出,例如房价、温度、股票价格等。其目标是建立自变量与因变量之间的数学关系(线性或非线性),实现对未知数据的数值估计。
分类:预测离散的类别标签,例如垃圾邮件识别(二分类)或水果图片分类(多分类)。其核心是通过决策边界将数据划分到预定义的类别中。
3.对数据进行归纳和整理
- 数据收集
明确数据来源:确定算法需要的数据类型和来源,例如传感器数据、图像、文本、数据库等。
数据量评估:评估所需数据的规模,确保数据量足够支持算法的训练和验证。
数据完整性检查:初步检查数据是否完整,是否存在缺失值或异常值。 - 数据清洗
去除重复数据:检查并删除重复的数据记录,避免对模型训练造成偏差。
处理缺失值:
删除缺失值:如果缺失数据较少,可以直接删除包含缺失值的记录。
填充缺失值:使用均值、中位数、众数或插值方法填充缺失值。
修正错误数据:检查数据中的异常值或错误数据,并进行修正或删除。
4.对输入的数据进行归一化和量化,保证模型运行的效率和提高模型运行的准确度
标准化:将数据转换为均值为0、标准差为1的分布。
归一化:将数据缩放到指定范围(如 [0, 1] 或 [-1, 1])。
5.在嵌入式处理器上面运行模型,对嵌入式处理器的整体性能提出了要求
目前一般可以运行算法的芯片都是核心数比较多,或者加入了自家的算法处理单元,比如NPU或者GPU。
6.将通用的算法模型转换成适配嵌入式处理器的模型文件
比如瑞芯微芯片提供了rknn-Toolkit2。
RKNN-Toolkit2 工具在 PC 平台上提供 C 或 Python 接口,简化模型的部署和运行。用户可以通过该工具轻松完成以下功能:模型转换、量化、推理、性能和内存评估、量化精度分析以及模型加密。RKNN 软件栈可以帮助用户快速的将 AI 模型部署到 Rockchip 芯片。整体的框架如下:
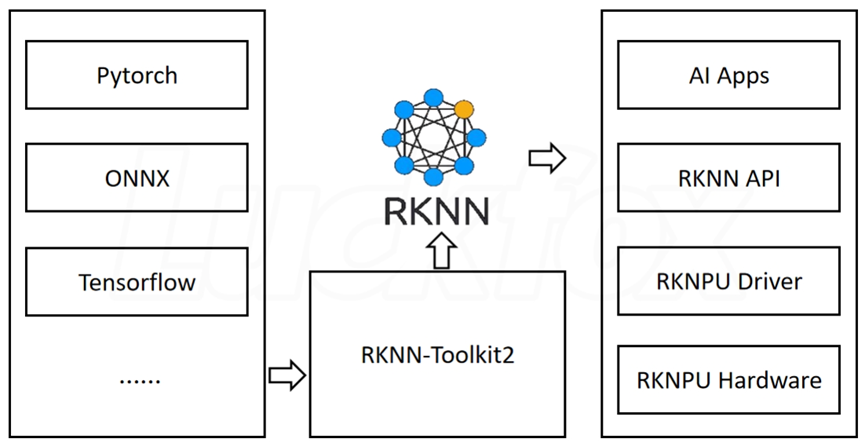
为了使用 RKNPU,用户需要首先在计算机上运行 RKNN-Toolkit2 工具,将训练好的模型转换为 RKNN 格式模型,之后使用 RKNN C API 或 Python API 在开发板上进行部署。
7.对模型的运行效率进行优化
可以使用硬件优化,比如采用多核心多线程的方式,提高模型的并行处理能力。还有就是对于算子进行优化。对数据进行精度的降低,但是对于运行效率可以提高。
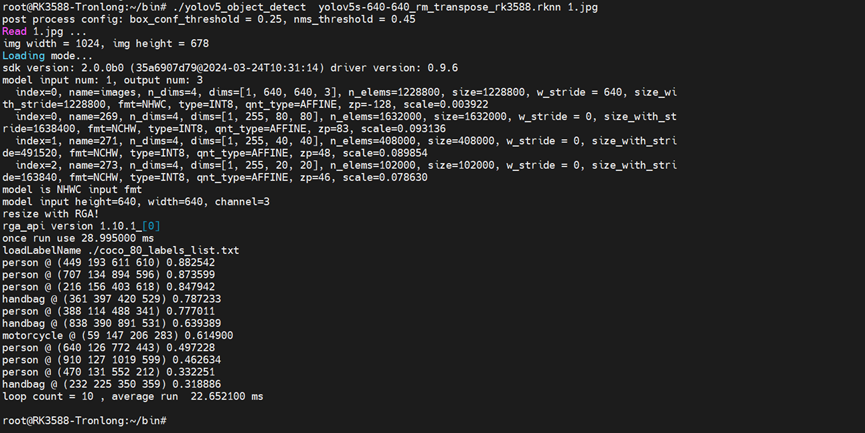
二、瑞芯微芯片部署初步尝试


总结
以上就是对于嵌入式处理器中部署和运行算法程序的一般开发思路。目前算法学习涉及到的知识面比较多,有卷积、神经网络,梯度,学习率,激活函数,损失函数,均值算法等。需要一个部分一个部分地去走通整个工程,这样对于算法的学习有一个全面的了解。