大连理工大学选修课——机器学习笔记(3):KNN原理及应用
KNN原理及应用
机器学习方法的分类
基于概率统计的方法
- K-近邻(KNN)
- 贝叶斯模型
- 最小均值距离
- 最大熵模型
- 条件随机场(CRF)
- 隐马尔可夫模型(HMM)
基于判别式的方法
- 决策树(DT)
- 感知机
- 支持向量机(SVM)
- 人工神经网络(NN)
- 深度学习(DL)
聚类算法
- 基于划分的聚类
- K-Means、K-MEDOIDS、CLARANS
- 层次聚类
- BIRCH、CURE、CHAMELEON
- 密度聚类
- DBSCAN、OPTICS、DENCLUE
增强学习方法
- 随机森林
- 增强算法(Boosting)
- 极端梯度提升(Xgboost)
- 梯度增强决策树(GBDT)
回归分析方法
- 回归分析方法
- 非线性回归(逻辑回归)
概率密度及累积分布函数
概率密度函数
-
随机变量x出现的可能性,在某个确定的取值点附近的输出值,记作 p ( x ) p(x) p(x)。
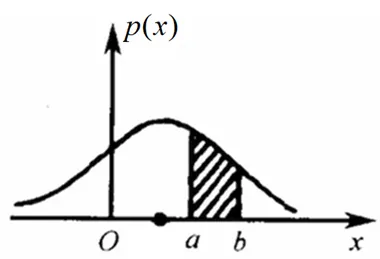
累计分布函数
-
随机变量 x 的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。
也称为概率分布函数,记作 P X ( x ) P_X(x) PX(x)。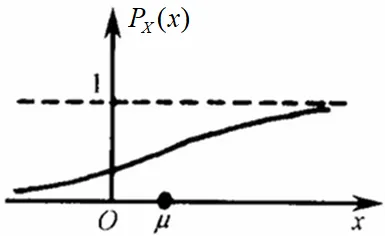
高斯分布
最常见的概率分布模型,也称为正态分布
二维:
p ( x ) = 1 2 π e x p ( − ( x − μ ) 2 2 σ 2 ) p(x)=\frac{1}{\sqrt{2\pi}exp(-\frac{(x-\mu)^2}{2\sigma^2})} p(x)=2πexp(−2σ2(x−μ)2)1
多维数据:
p X ( x 1 , ⋯ , x d ) = 1 ( 2 π ) d ∣ ∑ ∣ e ( x − μ ) T ∑ − 1 ( x − μ ) p_X(x_1,\cdots,x_d)=\frac{1}{\sqrt{(2\pi)^d|\sum|e^{(x-\mu)^T\sum^{-1}(x-\mu)}}} pX(x1,⋯,xd)=(2π)d∣∑∣e(x−μ)T∑−1(x−μ)1
贝叶斯决策
以分类为例
对于数据样本x,有M个类别,记作 C 1 , C 2 , ⋯ , C m C_1,C_2,\cdots,C_m C1,C2,⋯,Cm
- x属于各个类别的概率(后验概率):
- p ( C 1 ∣ x ) , p ( C 2 ∣ x ) , ⋯ , p ( C m ∣ x ) p(C_1|x),p(C_2|x),\cdots,p(C_m|x) p(C1∣x),p(C2∣x),⋯,p(Cm∣x)
- 判断样本x属于类别 C i C_i Ci:
- i = a r g M a x ( p ( C m ∣ x ) ) i=argMax(p(C_m|x)) i=argMax(p(Cm∣x))
后验概率的计算
- 经典的贝叶斯概率公式:
- P ( C i ∣ x ) = P ( x ∣ C i ) P ( C i ) P ( x ) = P ( x ∣ C i ) P ( C i ) ∑ P ( x ∣ C m ) P ( C m ) P(C_i|x)=\frac{P(x|C_i)P(C_i)}{P(x)}=\frac{P(x|C_i)P(C_i)}{\sum P(x|C_m)P(C_m)} P(Ci∣x)=P(x)P(x∣Ci)P(Ci)=∑P(x∣Cm)P(Cm)P(x∣Ci)P(Ci)
- P ( C i ) = N i N P(C_i)=\frac{N_i}{N} P(Ci)=NNi
- P ( x ∣ C i ) P(x|C_i) P(x∣Ci)可以叫做先验概率、先验密度、似然。
基于KNN的概率密度估计方法
后验密度 p ( C i ∣ x ) p(C_i|x) p(Ci∣x)的估算
-
基于假设:
-
相似的输入应该有相似的输出。
-
局部的分布模型只受到邻近实例样本的影响。
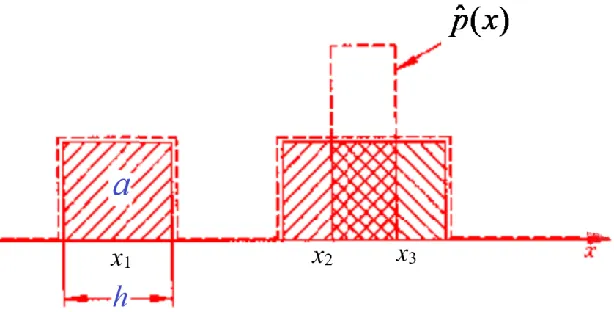
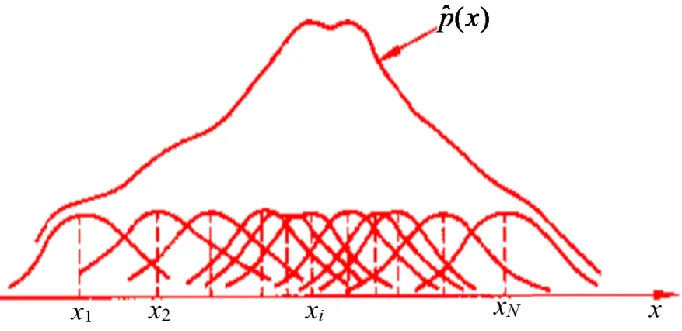
-
-
随机变量x落入区域R的概率:
P = ∫ R p ( x ) d x P=\int_Rp(x)dx P=∫Rp(x)dx
-
从规模为N 的样本集中抽取 k 个样本落入区域 R 的概率 符合随机变量的二项分布,可以写成:
P k = C N k P k ( 1 − P ) N − k , C N k = N ! k ! ( N − k ) ! P_k=C_N^kP^k(1-P)^{N-k},\quad C_N^k=\frac{N!}{k!(N-k)!} Pk=CNkPk(1−P)N−k,CNk=k!(N−k)!N!
-
具体操作方法
- 从随机变量 x 出发,向四周扩展,逐渐扩大区域 R。
- 直至区域里面包进来 k 个样本( x 最近邻的样本)
- 此时,周边区域的大小为 V R V_R VR,分布有( k +1 )个样本。
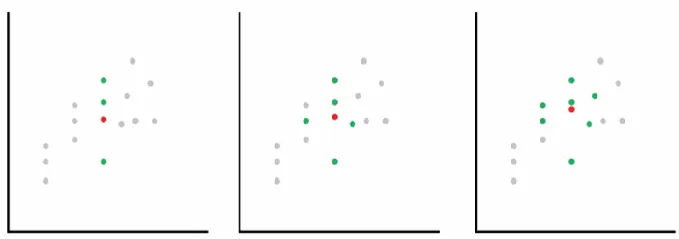
-
具体操作方法的理论:
目标是估计给定数据点x的后验密度 p ( C ∣ x ) p(C|x) p(C∣x)。
E [ k ] = N P k ≈ N P ^ \begin{align} E[k]=NP\\ k\approx N{\hat{P}} \end{align} E[k]=NPk≈NP^
式 ( 1 ) (1) (1)说明,在区域R内,期望的最近邻点数k等于总样本数N乘以概率P。
式 ( 2 ) (2) (2)说明,实际观测到的最近邻点数k近似等于NP。
由 ( 2 ) (2) (2)可得:
P ^ ≈ k N \begin{align} \hat{P}\approx\frac{k}{N} \end{align} P^≈Nk
概率P可理解为密度函数 p ( x ) p(x) p(x)在区域R内的积分,近似为 p ( x ) p(x) p(x)乘以区域体积 V V V:
P = ∫ R p ( x ) d x = p ( x ) V \begin{align} P=\int_{R}p(x)dx=p(x)V \end{align} P=∫Rp(x)dx=p(x)V
由式 ( 3 ) ( 4 ) (3)(4) (3)(4)可得:
k N ≈ P ^ = ∫ R p ^ ( x ) d x ≈ p ^ ( x ) V \begin{align} \frac{k}{N}\approx\hat{P}=\int_R\hat{p}(x)dx\approx\hat{p}(x)V \end{align} Nk≈P^=∫Rp^(x)dx≈p^(x)V
得:
p ^ ( x ) = k / N V \begin{align} \hat{p}(x)=\frac{k/N}{V} \end{align} p^(x)=Vk/N
在计算后验概率的时候,没有必要计算体积V:
( 6 ) (6) (6)等价于 ( 7 ) (7) (7):
p ^ ( x ) = k N V k ( x ) \begin{align} \hat{p}(x)=&\frac{k}{NV_k(x)}\\ \end{align} p^(x)=NVk(x)k
其中, k k k是 x x x的邻域内所有样本的数量, N N N为总样本数, V k ( x ) V_k(x) Vk(x)是邻域的体积。
当我们关注某个特别的类 C i C_i Ci时,公式 ( 7 ) (7) (7)中的换位特别的类 C i C_i Ci的样本数 k i k_i ki,总样本数 N i N_i Ni。
于是得到公式 ( 8 ) (8) (8),即类别条件概率密度估计:
p ^ ( x ∣ C i ) = k i N i V k ( x ) \begin{align} \hat{p}(x|C_i)=&\frac{k_i}{N_iV_k(x)} \end{align} p^(x∣Ci)=NiVk(x)ki
基于频率,易得表示类别 C i C_i Ci的先验概率估计:
p ( C i ) = N i N \begin{align} p(C_i)=\frac{N_i}{N} \end{align} p(Ci)=NNi
由 ( 7 ) ( 8 ) ( 9 ) (7)(8)(9) (7)(8)(9)可得:
P ^ ( C i ∣ x ) = k i k \begin{align} \hat{P}(C_i|x)=\frac{k_i}{k} \end{align} P^(Ci∣x)=kki
后验概率 P ( C i ∣ x ) P(C_i|x) P(Ci∣x)简化为x的最近邻中属于 C i C_i Ci的比例 k i k \frac{k_i}{k} kki。
KNN分类方法
由上推理可知:
k = k 1 + k 2 + k 3 P ^ ( C 1 ∣ x ) = k 1 k P ^ ( C 2 ∣ x ) = k 2 k P ^ ( C 3 ∣ x ) = k 3 k \begin{align} k=k_1+k_2+k_3\\ \hat{P}(C_1|x)=\frac{k_1}{k}\\ \hat{P}(C_2|x)=\frac{k_2}{k}\\ \hat{P}(C_3|x)=\frac{k_3}{k}\\ \end{align} k=k1+k2+k3P^(C1∣x)=kk1P^(C2∣x)=kk2P^(C3∣x)=kk3
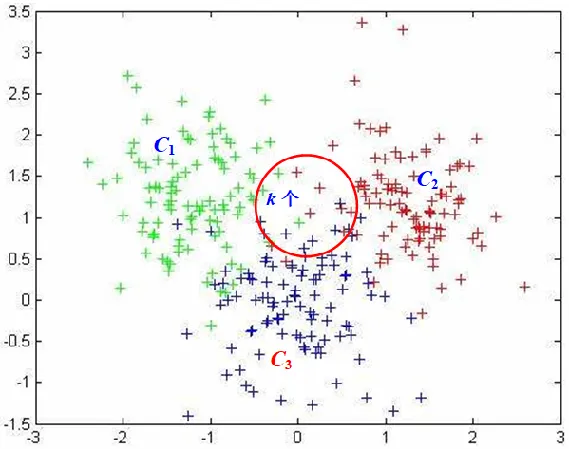
算法描述
如果一个样本在特征空间中的 k 个最邻近 (即最相似)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
- 特点:
- KNN算法的预测风险基本与贝叶斯模型一样,理论上非常低的错误风险。
- 没有明显的训练过程。
- 算法的复杂度很高。
- 需要记录所有的训练样本。
- 需要计算与所有训练样本的距离。
时间复杂度
- KNN的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 设:训练样本规模M,测试样本规模N,选择k个最近邻。
- 时间复杂度为: O ( k × M × N ) O(k\times M\times N) O(k×M×N)
- 若 M > = N M>=N M>=N: O ( n 2 ) O(n^2) O(n2)
训练样本的有效性
不是所有样本都有用
→KNN的决策边界仅由靠近类别边界的样本决定,而远离边界的样本(如类别内部的点)对分类结果无影响
优化思路:相容子集
定义:相容子集是训练集的一个最小子集,能够保持与原训练集完全相同的分类决策边界。
目标:仅保留边界附近的样本(相容子集),减少计算量,同时保持模型准确性。
实现:贪心算法。
KNN的距离计算方法
通常采用欧氏距离公式:
d a b = ∑ k = 1 n ( x 1 k − x 2 k ) 2 \begin{align} d_{ab}=\sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2} \end{align} dab=k=1∑n(x1k−x2k)2
如果要考虑量纲影响,可以进行归一化:
d = ∑ k = 1 n ( x 1 k − x 2 k s k ) \begin{align} d=\sqrt{\sum_{k=1}^{n}(\frac{x_{1k}-x_{2k}}{s_k})} \end{align} d=k=1∑n(skx1k−x2k)
式 ( 15 ) (15) (15)中, s k s_k sk称为归一化因子
采用马氏距离:
-
某一样本集的样本 Xi与Xj,样本集的协方差矩阵 S, 这两个多维向量Xi与Xj之间的马氏距离:
D ( X i , X j ) = ( X i − X j ) T S − 1 ( X i − X j ) \begin{align} D(X_i,X_j)=\sqrt{(X_i-X_j)^TS^{-1}(X_i-X_j)} \end{align} D(Xi,Xj)=(Xi−Xj)TS−1(Xi−Xj)
——当S为单位阵,式 ( 16 ) (16) (16)等价于 ( 14 ) (14) (14),为对角阵,式 ( 16 ) (16) (16)等价于 ( 15 ) (15) (15)。