第二章-科学计算库NumPy
第二章-科学计算库NumPy
Numpy 作为高性能科学计算和数据分析的基础包,是其他重要数据分析工具的基础, 掌握 NumPy 的功能及其用法, 将有助于后续其他数据分析工具的学习.
2.1 认识 NumPy 数组对象
NumPy 中最重要的一个特点就是其 N 维数组对象, 即 ndarray(别名 array) 对象, 该对象具有矢量算术能力和复杂的广播能力, 可以执行一些科学计算. 不同于 Python 标准库, ndarray 对象拥有对高维数组的处理能力, 这也是数值计算中缺一不可的重要特性.
ndarray 对象中定义了一些重要的属性, 具体如下.
| 属性 | 具体说明 |
|---|---|
| ndarray.ndim | 维度个数,也就是数组轴的个数, 比如一维, 二维, 三维等 |
| ndarray.shape | 数组的维度, 这是一个整数的元组, 表示每个维度上数组的大小. 例如, 一个 n 行 m 列的数组, 它的 shape 属性为 (n,m) |
| ndarray.size | 数组元素的总个数, 等于 shape 属性中元组元素的乘积 |
| ndarray.dtype | 描述数组中元素类型的对象, 既可以使用标准的 Python 类型创建或指定, 也可以使用 NumPy 特有的数据类型来指定, 比如 numpy.int32, numpy.float64等 |
| ndarray.itemsize | 数组中每个元素的字节大小. 例如, 元素类型为 float64的数组有 8(64/8) 个字节, 这相当于 ndarray.dtype.itemsize |
值得一提的是, ndarray 对象中存储元素的类型必须是相同的.
具体代码如下.
import numpy as np # 导入 numpy 工具包
data = np.arange(12).reshape(3,4) # 创建一个 3 行 4 列的数据
data
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
type(data)
numpy.ndarray
data.ndim # 数组维度的个数, 输出结果 2, 表示二维数组
2
data.shape # 数组的维度, 输出结果(3,4), 表示 3 行 4 列
(3, 4)
data.size # 数组元素的个数, 输出结果 12, 表示总共有 12 个元素
12
data.dtype # 数组元素的类型, 输出结果是 dtype('int64')# 表示元素类型都是 int64
dtype('int32')
2.2 创建 NumPy 数组
创建 ndarray 对象的方式有若干种, 其中最简单的方式就是使用 array() 函数, 在调用该函数时传入一个 Python 现有的类型即可, 比如列表, 元组. 例如, 通过 array() 函数分别创建一个一维数组和二维数组, 具体代码如下.
import numpy as np
data1 = np.array([1,2,3]) # 创建一个一维数组
data1
array([1, 2, 3])
data2 = np.array([[1,2,3],[4,5,6]]) # 创建一个二维数组
data2
array([[1, 2, 3],[4, 5, 6]])
除了可以使用 array() 函数创建 ndarray 对象外, 还有其他创建数组的方式, 具体分为以下几种:
- 通过 zeros() 函数创建元素值都是 0 的数组, 示例代码如下.
np.zeros((3,4))
array([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])
- 通过调用 ones() 函数创建元素值都是 1 的数组, 示例代码如下.
np_ones = np.ones((3,4))
np_ones
#np_ones.dtype # dtype('float64')
array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])
- 通过 empty() 函数创建一个新的数组, 该数组只分配了内存空间, 它里面填充的元素都是随机的, 且数据类型默认为 float64, 示例代码如下
np.empty((5,2))
array([[6.23042070e-307, 4.67296746e-307],[1.69121096e-306, 1.05695507e-307],[1.89146896e-307, 7.56571288e-307],[3.11525958e-307, 1.24610723e-306],[1.29061142e-306, 5.53353523e-322]])
- 通过 arange() 函数可以创建一个等差数组, 它的功能类似于 range(), 只不过 arange() 函数的返回结果是数组, 而不是列表, 示例代码如下.
np.arange(1,20,5) # 从 1 到 20, 步差为 5
array([ 1, 6, 11, 16])
读者可能注意到, 有些数组元素的后面会跟着一个小数点, 而有些元素后面没有, 比如 1 和 1., 产生这种现象, 主要是因为元素的数据类型不同所导致的.
值得一提的是, 在创建 ndarray 对象时, 我们可以显式的声明数组元素的类型, 示例代码如下.
np.array([1,2,3,4],float)
array([1., 2., 3., 4.])
np.ones((2,3),dtype='float64')
array([[1., 1., 1.],[1., 1., 1.]])
关于 ndarray 对象数据的更多介绍, 将在下面进行讲解.
2.3 ndarray 对象的数据结构
2.3.1 查看数据结构
如前面所述, 通过 “ndarray.dtype” 可以创建一个表示数据类型的对象. 要想获取数据类型的名称, 则需要访问 name 属性进行获取, 示例代码如下.
data_one = np.array([[1,2,3],[4,5,6]])
data_one.dtype.name
'int32'
注意:在默认情况下, 64 位 Windows 系统输出的结果为 int32, 64 位 Linux 或 MacOS 系统输出结果为 int64, 当然也可以通过 dtype 来指定数据类型的长度.
上述代码中, 使用 dtype 属性查看 data_one 对象的类型, 输出的结果为 int32. 从数据类型的命名方式上可以看出, Numpy 的数据类型是有一个类型名(如 int, float)和元素位长的数字组成.
如果在创建数组时, 没有显式的指明数据的类型, 可以根据列表或元组中的元素类型推导出来. 默认情况下, 通过 zeros(), ones(), empty() 函数创建的数组中的数据类型为 float64.
以下是 Numpy 中常用的数据类型.
| 数据类型 | 含义 |
|---|---|
| bool | 布尔类型, 值为 True 或 False |
| int8, uint8 | 有符号和无符号的 8 位整数 |
| int16, uint16 | 有符号和无符号的 16 位整数 |
| int32, uint32 | 有符号和无符号的 32 位整数 |
| int64, uint64 | 有符号和无符号的 64 位整数 |
| float16 | 半精度浮点数(16位) |
| float32 | 半精度浮点数(32位) |
| float64 | 半精度浮点数(64位) |
| complex64 | 复数, 分别用两个 32 位浮点数表示实部和虚部 |
| complex128 | 复数, 分别用两个 64 位浮点数表示实部和虚部 |
| object | Python对象 |
| string_ | 固定长度的字符串类型 |
| unicode | 固定长度的 unicode 类型 |
每一个 Numpy 内置的数据类型都有一个特征码, 它能唯一的标识一种数据类型, NumPy 内置特征码如下.
| 特征码 | 含义 |
|---|---|
| b | 布尔型 |
| i | 有符号整型 |
| u | 无符号整型 |
| f | 浮点型 |
| c | 复数类型 |
| O | Python 对象 |
| S,a | 字节字符串 |
| U | unicode 字符串 |
| V | 原始数据 |
2.3.2 转换数据类型
ndarray 对象的数据类型可以通过 astype() 方法进行转换, 示例代码如下.
data = np.array([[1,2,3],[4,5,6]])
print(data.dtype)
data
int32array([[1, 2, 3],[4, 5, 6]])
float_data = data.astype(np.float64) # 转换数据类型为 float64
print(float_data.dtype)
float_data
float64array([[1., 2., 3.],[4., 5., 6.]])
上述示例中, 将数据类型 int64 转换为 float64, 即整型转换为浮点型. 若希望将数据的类型由浮点型转换为整型, 则需要将小数点后面的部分截掉(不会四舍五入), 具体示例代码如下.
float_data = np.array([1.2,2.3,3.5])
float_data
array([1.2, 2.3, 3.5])
int_data = float_data.astype(np.int64) # 不会四舍五入
int_data
array([1, 2, 3], dtype=int64)
如果数组中的元素是字符串类型的, 且字符串中的每个字符都是数字,也可以使用 astype() 方法将字符串转换为数值类型, 具体示例如下.
str_data = np.array(['1','2','3'])
int_data = str_data.astype(np.int64)
int_data
array([1, 2, 3], dtype=int64)
2.4 数组运算
NumPy 数组不需要遍历循环, 即可对每个元素执行批量的算术运算操作, 这个过程叫做矢量化运算. 不过, 如果两个数组的大小(ndarray.shape)不同, 则它们进行算术运算时会出现广播机制. 除此之外, 数组还支持使用算术运算符与标量进行运算.
2.4.1 矢量化运算
在 NumPy 中, 大小相等的数组之间的任何算术运算都会应用到元素级, 即只用位置相同的元素之间, 所得的运算结果组成一个新的数组. 接下来, 同意一张示意图来描述什么是矢量化运算.
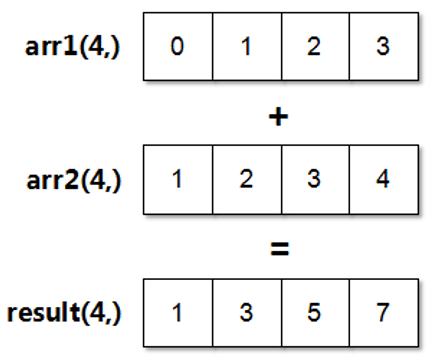
由上述图片可知, 数组 arr1 与 arr2 对齐以后, 会让相同位置的元素相加得到一个新的数组 result. 其中, result 数组中的每个元素为操作数相加的结果, 并且结果的位置跟操作数的位置是相同的.
大小相等的数组之间的算术运算, 示例代码如下.
data1 = np.array([[1,2,3],[4,5,6]])
data2 = np.array([[1,2,3],[4,5,6]])
data1 + data2 # 数组相加
array([[ 2, 4, 6],[ 8, 10, 12]])
data1 * data2 # 数组相乘
array([[ 1, 4, 9],[16, 25, 36]])
data1 - data2 # 数组相减
array([[0, 0, 0],[0, 0, 0]])
data1 / data2 # 数组相除
array([[1., 1., 1.],[1., 1., 1.]])
2.4.2 数组广播
数组在进行矢量化运算时, 要求数组的形状是相等的. 当形状不相等的数组执行算术运算的时候, 就会出现广播机制, 该机制会对数组进行扩展, 使数组的 shape 属性一致, 这样就可以进行矢量化运算了. 示例如下.
arr1 = np.array([[0],[1],[2],[3]])
arr1.shape
(4, 1)
arr2 = np.array([1,2,3])
arr2.shape
(3,)
arr1 + arr2
array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])
上述代码中, 数组 arr1 的 shape 是 (4,1), arr2 的 shape 是 (3,), 这两个数组要是进行相加, 按照广播机制就会对数组 arr1 和 arr2 都进行扩展, 使得数组 arr1 和 arr2 的 shape 都变成 (4,3).
具体数组广播机制实现如图所示.
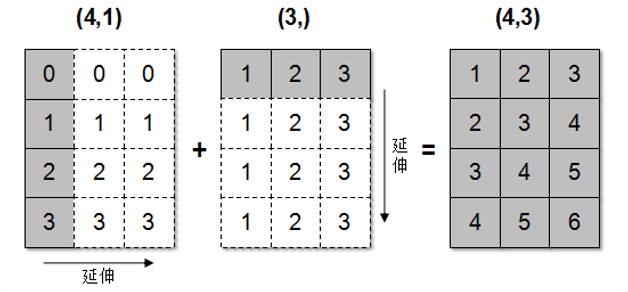
注意: 广播机制实现了对两个或两个以上数组的运算, 即使这些数组的 shape 不是完全相同的, 需要满足如下的条件:
- 数组维度全部相同
- 其中一个数组的某一个维度为 1.
广播机制需要扩展维度小数组, 使得它与维度最大的数组的 shape 值仙童, 以便使用元素级函数或运算符进行运算.
arr3 = np.array([[0,1],[2,3],[4,5],[6,7]])
print(arr3.shape)
arr3
(4, 2)array([[0, 1],[2, 3],[4, 5],[6, 7]])
arr4 = np.array([[1],[2]])
print(arr4.shape)
arr4
(2, 1)array([[1],[2]])
arr3 + arr4 # 相加报错, 两个维度都不相同
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[52], line 1
----> 1 arr3 + arr4ValueError: operands could not be broadcast together with shapes (4,2) (2,1)
arr5 = np.array([[1,2],[2,3],[3,4]])
print(arr5.shape)
arr5
(3, 2)array([[1, 2],[2, 3],[3, 4]])
arr3 + arr5 # error
# 第一维度:4 和 3 → 不相等且都不为 1 → 无法广播。
# 第二维度:2 和 2 → 相等 → 可以广播。
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[54], line 1
----> 1 arr3 + arr5ValueError: operands could not be broadcast together with shapes (4,2) (3,2)
2.4.3 数组与标量间的运算
大小相等的数组之间的任何算术运算都会将运算应用到元素级, 同样, 数组与标量的算术运算也会将那个标量值传播给各个元素. 当数组进行相加, 相减, 乘以或除以一个数字时, 这些被称为标量运算. 标量运算会产生一个与数组具有相同数量的行和列的新矩阵, 其原始矩阵的每个元素都被相加, 相减, 乘以或者相除.
数组和标量之间的运算, 示例代码如下.
import numpy as np
data1 = np.array([[1,2,3],[4,5,6]])
data1 + 10
array([[11, 12, 13],[14, 15, 16]])
data1 - 10
array([[-9, -8, -7],[-6, -5, -4]])
data1 * 10
array([[10, 20, 30],[40, 50, 60]])
data1 / 10
array([[0.1, 0.2, 0.3],[0.4, 0.5, 0.6]])
2.5 ndarray 的索引和切片
ndarray 对象支持索引和切片操作, 且提供了比常规 Python 序列更多的索引功能, 除了使用整数进行索引以外, 还可以使用整数数组和布尔数组进行索引.
2.5.1 整数索引和切片的基本使用
ndarray 对象的元素可以通过索引和切片来访问和修改, 就像 Python 内置的容易对象一样, 下面是一个一维数组, 从表面上来看, 该数组使用索引和切片的方式与 Python 列表的功能相差不大, 具体代码如下.
import numpy as np
arr = np.arange(8)
arr
array([0, 1, 2, 3, 4, 5, 6, 7])
arr[5] # 获取索引(下标)为 5 的元素
5
arr[3:5] # 获取索引从 3~5 的元素, 但不包括 5
array([3, 4])
arr[1:6:2] # 获取索引从 1~6 的元素, 步长为 2
array([1, 3, 5])
不过, 对于多维数组, 索引和切片的使用方式与列表就大不一样了. 在二维数组中, 每个索引位置上的元素不再是一个标量了, 而是一个一维数组, 具体代码示例如下.
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]]) # 创建二维数组
arr2d
array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
arr2d[1] # 获取索引为 1 的元素
array([4, 5, 6])
此时, 如果我们想通过索引的方式来获取二维数组的单个元素, 就需要通过形如 "arr[x,y]", 以逗号分割的索引来实现. 其中, x 表示行号, y 表示列号. 示例代码如下.
arr2d[0,1] # 获取第 0 行第 1 列的元素
2
下面, 通过一张图来描述数组 arr2d 的索引方式, 如下图所示.
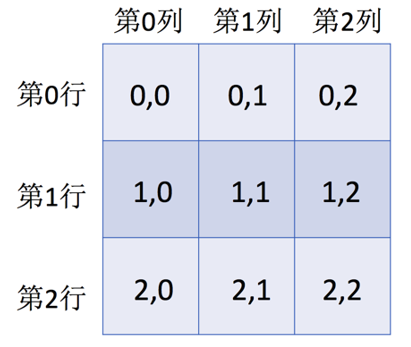
从图中可以看出, arr2d 是一个 3 行 3 列的数组, 如果我们想获取数组的单个元素, 必须同时指定这个元素的行索引和列索引. 例如, 获取索引位置为第 1 行第 1 列的元素, 我们可以通过 arr2d[1,1] 来实现.
相比一维数组, 多维数组的切片方式花样更多, 多维数组的切片是沿着行或列的方向选取元素的, 我们可以传入一个切片, 也可以传入多个切片, 还可以将切片与整数索引混合使用.
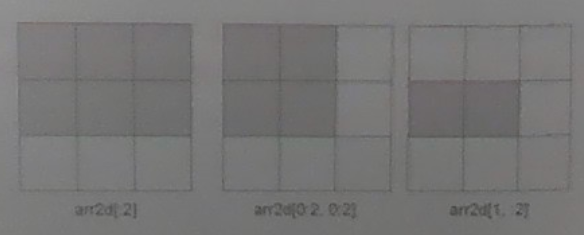
# 多维数组传入一个切片
arr2d[:2]
array([[1, 2, 3],[4, 5, 6]])
# 多维数组传入两个切片
arr2d[0:2,0:2]
array([[1, 2],[4, 5]])
# 切片与整数索引混合使用
arr2d[1,:2]
array([4, 5])
上述多维数组切片操作的相关示意图如下.
2.5.2 花式(数组)索引的基本使用
花式索引是 Numpy 的一个术语, 是指将整数数组或列表作为索引, 然后根据索引数组或索引列表的每个元素作为目标数组的下标再进行取值.
- 当使用一维数组或列表作为索引时, 如果使用索引要操作的目标是一维数组, 则获取的结果是对应下标的元素;
- 如果要操作的目标是一个二维数组, 则获取的结果就是对应下标的一行数据.
例如, 创建一个 4 行 4 列的二维数组, 示例代码如下.
import numpy as np
demo_arr = np.empty((4,4)) # 4 行 4 列的空数组
for i in range(4): # 遍历 4 行demo_arr[i] = np.arange(i,i+4) # 每一行一个数组从 [i ~ i+4)
demo_arr
array([[0., 1., 2., 3.],[1., 2., 3., 4.],[2., 3., 4., 5.],[3., 4., 5., 6.]])
将 [0,2] 作为索引, 分别获取 demo_arr 中索引 0 对应的一行数据以及索引 2 对应的一行数据, 示例代码如下.
demo_arr[[0,2]] # 获取索引为 [0,2] 的元素行
array([[0., 1., 2., 3.],[2., 3., 4., 5.]])
上述操作的相关示意图如下.

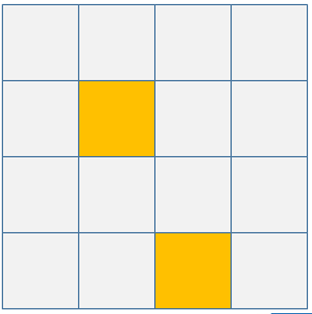
如果使用两个花式索引操作数组时, 即两个列表或数组, 则会将第 1 个作为行索引, 第 2 个作为列索引, 通过二维数组索引的方式, 选取其对应位置的元素, 示例代码如下.
demo_arr[[1,3],[1,2]] # 获取索引为 (1,1) 和 (3,2) 的元素
array([2., 5.])
上述操作的相关示意图如下.
2.5.3 布尔型索引的基本使用
布尔型索引指的是将一个布尔数组作为数组索引, 返回的数据是布尔数组中 True 对应位置的值.
假设现在有一组存储了学生姓名的数组, 以及一组存储了学生各科成绩的数组, 存储学生成绩的数组中, 每一行成绩对应的是一个学生的成绩. 如果我们想筛选某个学生对应的成绩, 可以通过比较运算符, 先产生一个布尔型数组, 然后利用布尔型数组作为索引, 返回布尔值 True 对应位置的数据. 示例代码如下:
# 存储学生姓名的数组
student_name = np.array(["Tom","Lily","Jack","Rose"])
student_name
array(['Tom', 'Lily', 'Jack', 'Rose'], dtype='<U4')
# 存储学生成绩的数组
student_score = np.array([[79,88,80],[89,90,92],[83,78,85],[78,76,80]])
student_score
array([[79, 88, 80],[89, 90, 92],[83, 78, 85],[78, 76, 80]])
# 对 student_name 和字符串 "Jack" 通过运算符产生一个布尔型数组
student_name == "Jack"
array([False, False, True, False])
# 将布尔数组作为索引应用与存储成绩的数组 student_score,
# 返回的数据是 True 值对应的行
student_score[student_name == "Jack"]
array([[83, 78, 85]])
布尔索引的相关示意图如下.
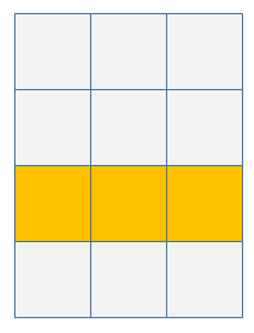
需要注意的是, 布尔型数组的长度必须和被索引的轴长度一致.
此外, 我们还可以将布尔型数组跟切片混合使用, 示例代码如下:
student_score[student_name == "Jack", :1]
array([[83]])
值得一提的是, 使用布尔型索引获取值的时候, 除了可以使用 "==" 运算符, 还可以使用诸如 "!=", "-" 来进行否定, 也可以使用 "&"和"|"等符号来组合多个布尔条件.
2.6 数组的转置和轴对称
数组的转置是指将数组中的每个元素按照一定的规则进行位置变换. NumPy 提供了 transpose() 方法和 T 属性两种实现形式. 其中, 简单的转置可以使用 T 属性, 它其实就是进行轴对换而已. 例如, 现在有个 3 行 4 列的二维数组, 那么使用 T 属性对数组转置后, 形成的是一个 4 行 3 列的新数组, 示例代码如下.
arr = np.arange(12).reshape(3,4)
arr
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
arr.T # 使用 T 属性对数组进行转置
array([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
对于高纬度的数组而言, transpose() 方法需要得到一个由轴编号组成的元组, 才能对这些轴进行转置. 假设现在有个数组 arr, 具体代码如下:
arr = np.arange(16).reshape((2,2,4)) # 2 面 2 行 4 列
arr
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 8, 9, 10, 11],[12, 13, 14, 15]]])
arr.shape
(2, 2, 4)
上述数组 arr 的 shape 是 (2,2,4), 表示是一个三维数组, 也就是说有三个轴, 每个轴都对应着一个编号, 分别是 0, 1, 2.
如果希望对 arr 进行转置操作, 就需要对它的 shape 中的顺序进行调换. 也就是说, 当使用 transpose() 方法对函数的 shape 进行变换时, 需要以元组的形式传入 shape 的编号, 比如 (1,2,0).如果调用 transpose() 方法时传入 "(0,1,2)" ,则数组的 shape 不会发生任何变化.
下面是 arr 调用 transpose(1,2,0) 的示例, 具体代码如下
arr.transpose(1,2,0) # 使用 transpose() 方法对数组进行转置
array([[[ 0, 8],[ 1, 9],[ 2, 10],[ 3, 11]],[[ 4, 12],[ 5, 13],[ 6, 14],[ 7, 15]]])
转换过程如图:

如果我们不输入任何参数, 直接调用 transpose() 方法, 则其执行的效果就是将数组进行转置, 作用等价于 transpose(2,1,0). 具体结果如下图所示.

在某些情况下, 我们可能只需要转换其中的两个轴, 这时我们可以使用 ndarray 提供的 swapaxes() 方法实现, 该方法需要接收一对轴编号, 示例代码如下.
arr
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 8, 9, 10, 11],[12, 13, 14, 15]]])
arr.swapaxes(1,0) # 使用 swapaxes 方法插入一对小括号对数组进行转置
array([[[ 0, 1, 2, 3],[ 8, 9, 10, 11]],[[ 4, 5, 6, 7],[12, 13, 14, 15]]])
多学一招: 轴编号
在 NumPy 中维度(dimensions)叫做轴(axes), 轴的个数叫做秩(rank). 例如, 3D 空间中有个点的坐标[1,2,1]是一个秩为 1 的数组, 因为它只有一个轴. 这个轴有 3 个元素, 所以我们说它长度为 3.
在下面的示例中, 数组有 2 个轴, 第一个轴的长度为32, 第二个轴的长度为 3.
np.array([[1,0,0],[0,1,2]])
array([[1, 0, 0],[0, 1, 2]])
2.7 NumPy 通用函数
在 NumPy 中, 提供了诸如 "sin", "cos" 和 "exp" 等常见的数学函数, 这些函数叫做通用函数(ufunc). 通用函数是一种针对 ndarray 中的数据执行元素级运算的函数, 函数返回的是一个新的数组. 通常情况下, 我们将 ufunc 中接受的一个数组参数的函数称为一元通用函数. 而接收两个数组参数的称为二元通用函数. 下面是一些常见的一元和二元通用函数.
| 常见一元的通用函数函数 | 描述 |
|---|---|
| abs, fabs | 计算整数, 浮点数或复数的绝对值 |
| sqrt | 计算各元素的平方根 |
| square | 计算各元素的平方 |
| exp | 计算各元素的指数 e 的 x 次方 |
| log, log10, log2, log1p | 分别为自然对数(底数为e), 底数为 10 的 log, 底数为 2 的log, log(1+x) |
| sign | 计算各元素的正负号: 1(正数), 0(零), -1(负数) |
| ceil | 计算各元素的 ceilling 值, 即大于或者等于该值的最小整数 |
| floor | 计算各元素的 floor 值, 即小于等于该值的最大整数 |
| rint | 将各元素四舍五入到最接近的整数 |
| modf | 将数组的小数和整数部分以两个独立数组的形式返回 |
| isnan | 返回一个表示 “哪些值是 NaN” 的布尔型数组 |
| isfinite, isinf | 分别返回表示 “那些元素是有穷的” 或 “哪些元素是无穷” 的布尔型数组 |
| sin, sinh, cos, cosh, tan, tanh | 普通型和双曲型三角函数 |
| arcos,arccosh,arcsion | 反三角函数 |
| 常见二元通用函数 | 描述 |
|---|---|
| add | 数组对应的元素相加 |
| subtract | 从第一个数组中减去第二个数组中的元素 |
| multiply | 数组元素相乘 |
| divide,floor_divide | 除法或向下整除法(舍去余数) |
| maximum, fmax | 元素级的最大值计算 |
| minimum, fmin | 元素级的最小值计算 |
| mod | 元素级取余 |
| copysign | 将第二个数组中的值的符号赋值给第一个数组中的值 |
| greater,greater_equal,less,less-equal,equal,not_equal,logical_and,logical_or,logical_xor | 执行元素级的比较运算, 最终产生布尔型数组, 相当于运算符 >,>=,<,<=,==,!= |
为了更好理解, 接下来, 通过一些代码来演示上述部分函数的用法. 有关一元通用函数的示例代码如下.
import numpy as np
arr = np.array([4,9,16])
# 计算数组元素的平方根
np.sqrt(arr)
array([2., 3., 4.])
# 计算数组元素的绝对值
np.abs(arr)
array([ 4, 9, 16])
# 计算数组元素的平方
np.square(arr)
array([ 16, 81, 256])
有关二元通用函数的示例代码如下
x = np.array([12,9,13,15])
y = np.array([11,10,4,8])
# 计算两个数组的和
np.add(x,y)
array([23, 19, 17, 23])
# 计算两个数组的乘积
np.multiply(x,y)
array([132, 90, 52, 120])
# 两个数组元素级最大值的比较
np.maximum(x,y)
array([12, 10, 13, 15])
# 执行元素级的比较操作
np.greater(x,y)
array([ True, False, True, True])
2.8 利用 NumPy 数组进行数据处理
NumPy 数组可以将许多数据处理任务转换为简洁的数组表达式, 它处理数据的速度要比内置的 Python 循环快了至少一个数量级, 所以, 我们把数组作为处理数据的首选. 接下来, 本章节将讲解如何利用数组来处理数据, 包括条件逻辑, 统计, 排序, 检索数组元素以及唯一化.
2.8.1 将条件逻辑转为数组运算
NumPy 的 where() 函数是三元表达式 x if condition else y 的矢量化版本.
假设有两个数值类型的数组和一个布尔类型的数组, 具体如下:
import numpy as np
arr_x = np.array([1,5,7])
arr_y = np.array([2,6,8])
arr_con = np.array([True,False,True])
现在提出一个需求, 即当 arr_con 的元素值为 True 时, 从 arr_x 数组中获取一个值, 否则从 arr_y 数组中获取一个值. 使用 where() 函数实现的方式如下所示.
result = np.where(arr_con, arr_x, arr_y)
result
array([1, 6, 7])
2.8.2 数组统计运算
通过 NumPy 库中的相关方法, 我们可以很方便的运用 Python 进行数组的统计汇总, 比如, 计算数组极大值, 极小值以及平均值等. 下面是 NumPy 数组中与统计运算相关的方法.
| 方法 | 描述 |
|---|---|
| sum | 对数组中全部或某个轴向的元素求和 |
| mean | 算术平均值 |
| min | 计算数组中的最小值 |
| max | 计算数组中的最大值 |
| argmin | 表示最小值的索引 |
| argmax | 表示最大值的索引 |
| cumsum | 所有元素的累计和 |
| cumprod | 所有元素的累计乘积 |
需要注意的是, 当使用 ndarray 对象调用 cumsum() 和cumprod() 方法后, 产生的结果是一个由中间结果组成的数组.
下面是一些示例.
arr = np.arange(10)
print(arr)
arr.sum() # 求和
[0 1 2 3 4 5 6 7 8 9]45
arr.mean() # 求平均值
4.5
arr.min() # 求最小值
0
arr.max() # 求最大值
9
arr.argmin() # 最小值的下标
0
arr.argmax() # 最大值的下标
9
arr.cumsum() # 元素的累计和
array([ 0, 1, 3, 6, 10, 15, 21, 28, 36, 45])
arr.cumprod() # 元素的累计乘积
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
2.8.3 数组排序
如果希望对 NumPy 数组中的元素进行排序, 可以通过 sort() 方法实现, 示例代码如下.
arr = np.array([[6,2,7],[3,6,2],[4,3,2]])
arr
array([[6, 2, 7],[3, 6, 2],[4, 3, 2]])
arr.sort()
arr
array([[2, 6, 7],[2, 3, 6],[2, 3, 4]])
从上述代码可以看出, 当调用 sort() 方法后, 数组 arr 中数据按行从小到大进行排序. 需要注意的是, 使用 sort() 方法排序会修改数组本身.
如果希望对任何一个轴上的元素进行排序, 只需要将轴的编号作为 sort() 方法的参数传入即可. 示例代码如下.
arr = np.array([[6,2,7],[3,6,2],[4,3,2]])
arr
array([[6, 2, 7],[3, 6, 2],[4, 3, 2]])
arr.sort(0)
arr
array([[3, 2, 2],[4, 3, 2],[6, 6, 7]])
理解: arr.sort(0) 的直观操作
- 轴0(行方向):想象你 从上到下垂直移动(处理每一列)。
- 轴1(列方向):想象你 从左到右水平移动(处理每一行)。
当执行 arr.sort(0)(沿轴0排序)时:
- 操作方向:从上到下(垂直方向)。
- 具体行为:对 每一列 独立排序(每一列的数字按升序排列)。
原始数组:
列0 列1 列2↓ ↓ ↓
[6, 2, 7] ← 行0
[3, 6, 2] ← 行1
[4, 3, 2] ← 行2沿轴0(列方向)排序后的结果:
列0排序 ↓ 列1排序 ↓ 列2排序 ↓[3, 2, 2] ← 行0[4, 3, 2] ← 行1[6, 6, 7] ← 行2
关键理解
- 为什么叫「沿行方向处理」?
因为你在处理时,沿着行的方向(上下移动),依次处理每一列的数据(比如先处理列0,再处理列1)。
2.8.4 检索数组元素
在 NumPy 中, all() 函数用于判断整个数组中的元素的值是否完全满足条件, 如果满足条件返回 True, 否则返回 False. any() 函数用于判断整个数组中的元素至少有一个满足条件就返回 True, 否则返回 False.
使用 all() 和 any() 函数检索数组元素的示例代码如下.
arr = np.array([[1,-2,-7],[-3,6,2],[4,3,2]])
arr
array([[ 1, -2, -7],[-3, 6, 2],[ 4, 3, 2]])
np.any(arr>0) # arr 的所有元素是否有一个大于 0
True
np.all(arr>0) # arr 的所有元素是否都大于 0
False
2.8.5 唯一化及其他集合逻辑
针对一维数组, NumPy 提供了 unique() 函数来找出数组中的唯一值, 并返回排序后的结果, 示例代码如下.
arr = np.array([12,11,34,23,12,8,11])
np.unique(arr) # 去重
array([ 8, 11, 12, 23, 34])
除此之外, 还有一个 in1d() 函数用于判断数组中的元素是否在另一个数组中存在, 该函数返回的是一个布尔型的数组, 示例代码如下.
np.in1d(arr,[11,12])
array([ True, True, False, False, True, False, True])
NumPy 提供的有关集合的函数还有很多, 下面是数组集合运算的常见函数.
| 函数 | 描述 |
|---|---|
| unique(x) | 计算 x 中的唯一元素, 并返回有序结果 |
| intersect1d(x,y) | 计算 x 和 y 中的公共元素, 并返回有序结果 |
| union1d(x,y) | 计算 x 和 y 的并集, 并返回有序结果 |
| in1d(x,y) | 得到一个表示"x 的元素是否包含 y"的布尔型数组 |
| setdiff1d(x,y) | 集合的差, 即元素在 x 中且不在 y 中 |
| setxor1d(x,y) | 集合的对称差, 即存在于一个数组中但不同时存在于两个数组中的元素 |
2.9 线性代数模块
线性代数是数学运算中的一个重要工具, 它在图形信号处理, 音频信号处理中起非常重要的作用. numpy.linalg 模块中有一组标准的矩阵分解运算以及诸如逆和行列式之类的东西. 例如, 矩阵相乘, 如果通过 “*” 对两个数组相乘, 得到的是一个元素级的乘积, 而不是一个矩阵点积.
NumPy 中提供了一个用于矩阵乘法的 dot() 方法, 该方法的用法示例如下.
import numpy as np
arr_x = np.array([[1,2,3],[4,5,6]])
arr_y = np.array([[1,2],[3,4],[5,6]])
print(arr_x)
print(arr_y)
arr_x.dot(arr_y) # 等价于 np.dot(arr_x,arr_y)
[[1 2 3][4 5 6]]
[[1 2][3 4][5 6]]array([[22, 28],[49, 64]])
矩阵点积的条件是矩阵A的列数等于矩阵B的行数, 假设 A 为 m✕p 的矩阵, B 为 p✕n 的矩阵, 那么矩阵 A 与 B 的乘积就是一个 m✕n 的矩阵 C, 其中矩阵 C 的第 i 行第 j 列的元素可以表示为:
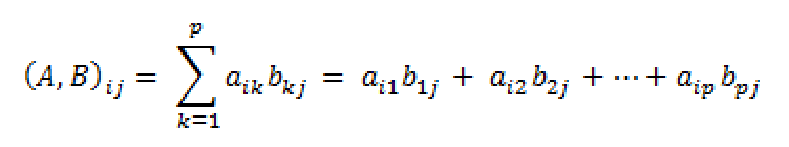
上述矩阵 arr_x 与 arr_y 的乘积如下图所示.
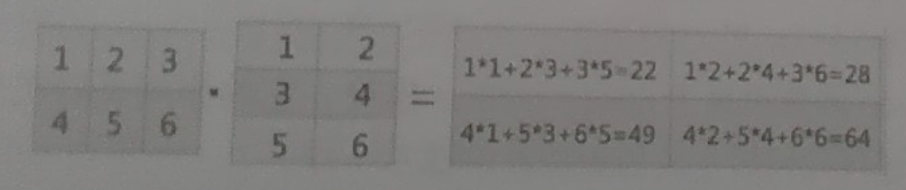
除此之外, linalg 模块中还提供了其他很多有用的函数, 具体如下.
| 函数 | 描述 |
|---|---|
| dot | 矩阵乘法 |
| diag | 以一维数组的形式返回方阵的对角线, 或将一维数组转为方阵 |
| trace | 计算对角线元素和 |
| det | 计算矩阵的行列式 |
| eig | 计算方阵的特征值和特征向量 |
| inv | 计算方阵的逆 |
| qr | 计算 qr 分解 |
| svd | 计算奇异值(SVD) |
| solve | 解线性方程组 Ax=b, 其中 A 是一个方阵 |
| 1stsq | 计算 Ax=b 的最小二乘解 |
2.10 随机数模块
与 Python 的 random 模块相比, NumPy 的 random 模块功能更多, 它增加了一些可以高效生成多种概率分布的样本值的函数. 例如, 通过 NumPy 的 random 模块随机生成了一个 3 行 3 列的数组, 示例代码如下.
import numpy as np
np.random.rand(3,3) # 随机生成一个二维数组
array([[0.15259203, 0.96894671, 0.11222132],[0.49061311, 0.97040608, 0.50455898],[0.04179985, 0.8569699 , 0.8445863 ]])
上述代码中, rand() 函数隶属于 numpy.random 模块, 它的作用是随机生成 N 维浮点数组. 需要注意的是, 每次运行代码后生成的随机数组都不一样.
除此之外, random 模块中还包括了可以生成服从多种概率分布随机数的其他函数. 下面列举了 numpy.random 模块中用于生成大量样本值的函数.
| random 模块的常见函数 | 描述 |
|---|---|
| seed | 生成随机数的种子 |
| rand | 产生均匀分布的样本值 |
| randint | 从给定的上下限范围内随机选取整数 |
| normal | 产生正态分布的样本值 |
| beta | 产生 Beta 分布的样本值 |
| uniform | 产生在 [0,1] 中的均匀分布的样本值 |
在上面的函数中, seed() 函数可以保证生成的随机只具有可预测性, 也就是说产生的随机数相同, 它的语法格式如下:
numpy.random.seed(seed=none)
上述函数中只有一个 seed 参数, 用于指定随机数生成时所用算法开始的整数值. 当调用 seed() 函数时, 如果传递给 seed 参数的值相同, 则每次生成的随机数都是一样的. 如果不传递这个参数值, 则系统会根据时间来自己选择值, 此时每次生成的随机数会因时间差异而不同.
使用 seed() 函数的示例代码如下.
np.random.seed(0) # 生成随机数的种子
np.random.rand(5) # 随机生成包含 5 个元素的浮点数组
array([0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
np.random.seed(0)
np.random.rand(5)
array([0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
np.random.seed()
np.random.rand(5)
array([0.62979455, 0.48687157, 0.23137517, 0.71878505, 0.93389724])
由此可见, seed() 函数使得随机数具有预见性. 当传递的参数值不同或者不传递参数时, 则该函数的作用跟 rand() 函数相同, 即多次生成随机数且每次生成的随机数都不同.
{% note success flat %}
小结
本章主要针对科学计算哭 NumPy 进行了介绍, 包括 ndarray 数组对象的属性和数据类型, 数组的运算, 索引和切片操作, 数组的转置和轴对称个, NumPy 通用函数, 线性代数模块, 随机数模块, 以及使用数组进行数据处理的相关操作.
{% endnote %}