读论文笔记-LLaVA:Visual Instruction Tuning
读论文笔记-LLaVA:Visual Instruction Tuning
《Visual Instruction Tuning》
研究机构:Microsoft Research
发表于2023的NeurIPS
Problems
填补指令微调方法(包括数据、模型、基准等)在多模态领域的空白。
Motivations
- 人工智能的核心目标就是构建一种通用的助手,能够识别多模态的指令,与人类意图保持一致,从而完成现实生活中的任务。
- 有指令跟随能力的视觉模型交互性、适应性差:在视觉模型中,语言指令一般隐含在模型中,或是作为图像的描述,只在把视觉信号映射成文本语义上有很大作用。
- 指令跟随的语言模型已经小有所成,可以进一步扩展:大语言模型已经展现出来了作为通用助手的通用接口的能力,指令显示地表达且能够指导模型解决目标任务,对其扩展到视觉语言范畴可以为通用视觉助手的产生铺路。
- 现有多模态模型并没有直接在视觉语言指令数据上微调,且用在纯文本任务上效果会下降。
Methods
Key1:填补数据集的空白——GPT辅助的视觉语言指令数据生成
受利用GPT进行文本标注的影响,作者用ChatGPT/GPT4这种多模态语言模型来生成指令跟随数据。但由于GPT4在当时还没有开放多模态接口,所以用的是纯文本版本。
- 对于现有的图像数据集(COCO),把图像用captions和bbox这两种符号表示替代,作为输入的图片内容sample_content or sample context;
- 利用3种system_content or messages构造3类输入-输出范式:每类范式中都先有少量人工标注的样例(根据sample content/context和指定的范式,生成的response),作为上下文学习的示例喂给模型;
- 让模型对所有queries(只有sample content/context)进行扩展,扩展出3种形式的指令-回复范式: conversation(对图中的物体提问,只提有确定答案的问题)、detailed description(提问并产生详细的描述)、complex reasoning(提出需要深度推理的问题,产生逻辑性强的回答)。

以生成对话的跟随数据集为例,喂给GPT4的提示词是:system_content(指定用户和助手身份,以及生成数据的要求)+sample contents+sample responses(这里的response就是QA对)+query(新的content)。
给GPT4的提示词+query示例:


最终,作者构造了LLaVA-Instruct-158K的视觉语言指令跟随样本(58K对话+23K详细描述+77K的复杂推理)
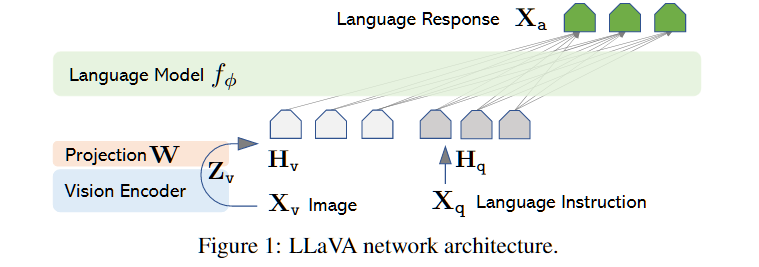
Key2:构造视觉指令微调模型LLaVA
- 用预训练好的Vicuna作为LLM:在开源的语言模型中具有最好的指令跟随能力。
- 用预训练的CLIP的视觉编码器ViT-L/14处理图像+线性投影(W)到词嵌入的空间: X v − > Z v = g ( X v ) − > H v = W ∗ Z v X_v->Z_v=g(X_v)->H_v=W*Z_v Xv−>Zv=g(Xv)−>Hv=W∗Zv
-
在第一阶段(特征对齐预训练阶段):用CC595K数据,冻结图像编码器和LLM,只训练线性投影层W,使得条件概率最大。相当于为LLM学习一个兼容的视觉分词器,让图像特征 H v H_v Hv与词嵌入对齐。训练1个epoch,bs=128。
CC595K:是CC3M数据集过滤成595K之后,以文中最开始提到的一种低成本方法构造的’Human: Q V stop Assistant: Captions stop’形式。这种方法生成的指令和回应样本缺乏多样性和深度推理能力。
-
第二阶段(端到端微调):用LLaVA-Instruct-158K和Science QA基准,冻结视觉编码器,微调线性投影层和LLM。前者用于构造多模态 chatbot,后者就构造Science QA的模型。训练3个epoch,bs=32,对Science QA来说12epoch。
Science QA:每一个问题都会提供一段文本或图像,每一个回答要么是自然语言的推理过程要么是多选题的答案。因此,把问题+文本/图像作为指令,推理过程+答案作为回应。
Key3:构造2个定性评估模型能力的基准
- LLaVA-Bench(COCO):从COCO-Val-2014中选择30张图像,并生成3类的指令跟随数据。
- LLaVA-Bench(In-the-Wild):24张图像包含室内、室外场景,绘画,素描等风格,每个图像由人工详细描述,每个图像有一系列问题,共60个问题。需要模型有很广泛的知识面,并且能够处理高分辨率图像。
Experiments
-
Training datasets:新构造的CC595K指令数据+自己构造的视觉语言指令跟随数据LLaVA-Instruct-158K+Science QA
对于对话场景,设置的是多轮对话。在训练时,给模型输送的数据be like: X s y s t e m m e s s a g e + X i n s t r u c t 1 + . . . + X i n s t r u c t t X_{system message}+X_{instruct}^1+...+X_{instruct}^t Xsystemmessage+Xinstruct1+...+Xinstructt,第一个指令包含的是问题和图片 [ X q , X v ] o r [ X v , X q ] [X_q,X_v]or[X_v,X_q] [Xq,Xv]or[Xv,Xq],后面所有指令就只是问题。这里的系统信息与Vicuna-v0一样,模型就负责预测句子之间的停顿和答案。其他两个范式都是单轮对话的。
-
Training objectives:自回归训练。也就是预测第一个答案之后,该答案作为下一次预测的输入,以此类推。
p ( X a ∣ X v , X i n s t r u c t ) = ∏ i = 1 L p θ ( x i ∣ X v , X i n s t r u c t , < i , X a , < i ) p(Xa|Xv, Xinstruct) = ∏_{i=1}^L p_θ(xi|X_v, X_{instruct},<i, X_a,<i) p(Xa∣Xv,Xinstruct)=i=1∏Lpθ(xi∣Xv,Xinstruct,<i,Xa,<i) -
Evaluation tasks:主要验证模型的指令跟随能力和视觉推理能力。补充材料的一些实验也证明了模型的涌现能力:能够识别出训练集中没有的图片。
- Task name:Multimodal chatbot的定性评估;
- Task data:GPT-4使用的样例、OCR识别样例;
- Comapred methods:LLaVA、GPT4、BLIP2、OpenFlamingo
- Results:1)相比于BLIP2\OpenFlamingo,LLaVA并不是描述图像内容而是跟着指令描述了异常之处。2)相比于GPT4,LLaVA描述的更全面。3)即使只让模型描述图片,也能关注到异常之处。图像是out-of-domain的,因此能证明模型的推理能力也很强。
- Task name:Multimodal chatbot的定量评估:A.验证不同训练数据对模型高效性的影响;B.在更具挑战性和新域的数据上,评估模型的泛化能力和性能。
- Task data:LLaVA-Bench(COCO),LLaVA-Bench(In-the-Wild)
- Comapred methods:让GPT4接收图片的文字性描述+问题,输出理论上限的回应。再让他对理论上限回应与LLaVA模型的回应进行对比评分。A.不同训练数据的消融实验:使用不同形式的LLaVA-Instruct训练数据,在COCO标准上验证,用GPT4对生成结果进行有对比的评分并给出评分的解释。B.与BLIP2\OpenFlamingo比较。
- Results:A.用全部指令数据训练得到的模型的效果最好。B.显著好于其他两个模型,相对于拿到答案的GPT4,有81.7%的很好的推理能力。
- Task name:ScienceQA对比实验
- Task data:ScienceQA
- Comapred methods:和Human\GPT3.5\GPT3.5 withoutCOT\LLaMA-Adapter\MM-CoTbase\MM-CoTlarge\GPT-4\LLaVA+GPT4。
- Results:1)LLaVA有媲美SOTA的表现;2)为了探究LLM的极限,先对GPT4进行2-shot上下文学习得到一个指标。再将问题数量提升后发现模型由于图像太少而失败了; 3)当GPT4不能回答时,就用LLaVA的答案。发现平均准确率与LLaVA单独差不多;4) 当GPT4和LLaVA产生不同答案时,让GPT4根据这两个答案产生新的答案,作为一种类似于从其他模型中获得知识进行COT的方法,达到了SOTA。这表明GPT4能够用在模型聚合上,并且能够帮助修正模型错误的知识,并且识别出一些答案不在图片上的任务。
- Task name:ScienceQA消融实验
- Task data:ScienceQA
- Compared methods:比较使用CLIP的visual features的位置,推理和预测的顺序,检验特征对齐微调阶段的重要性,比较模型规模。
- Results:1)使用倒数第二层的视觉特征有更好的效果,可能是因为倒数第二层更关注局部的信息,而最后一层则关注全局和抽象的信息;2)推理和预测的顺序只和收敛速度有关,对最终表现只有微弱贡献;3)进行特征对齐能够保留大量的训练知识;4)模型规模对效果有决定作用。