大连理工大学选修课——机器学习笔记(5):EMK-Means
EM&K-Means
无监督学习
-
什么是无监督学习
- 模型从无标签的数据中自动发现隐藏的模式或结构
- 聚类是最常用的方法
-
为什么要研究无监督学习
- 标记样本代价太大
- 分类模式不断变化,标记易过时
-
数据的分布
- 参数方法
- 高斯分布、伯努利分布、多指分布等
- 非参数方法
- 局部模型,在足够小的区域做分布模型假设
- 半参数方法
- 数据在空间聚集成不同的分组/簇
- 簇内的模型分布相同,簇之间可以不同
- 参数方法
-
混合密度
p ( x ) = ∑ i = 1 k p ( x ∣ G i ) P ( G i ) p(x)=\sum_{i=1}^kp(x|G_i)P(G_i) p(x)=∑i=1kp(x∣Gi)P(Gi)
- 对不同的区域采用不同的分组
- p(x|Gi):成分密度;P(Gi):混合比例;共k个分组。
实践中常采用混合分布模型:
- 不同的类具有不同的概率模型,采用不同的协方差矩阵
- 概率参数可以通过最大似然估计计算。
-
无监督学习的问题描述
- 没有类别信息
- 完成以下两个任务
- 估计类别的标记
- 估计给定实例所属簇的概率参数
-
无监督学习的方法
- 聚类
- 根据数据对象的相似性大小,把数据分为不同的类
- 常用作分类的预处理
- 聚类
-
常用的聚类分析方法
- 划分方法
- 对于指定K个组的数据分组任务通过迭代的方法来实现
- 每次迭代,把数据集划分为K个分组,每一轮的划分质量都比上一轮更好
- 基于距离准则
- 采用启发式算法,得到局部最优解
- 常用方法
- K-means
- 对于指定K个组的数据分组任务通过迭代的方法来实现
- 划分方法
-
其它聚类方法
- 层次方法
- 基于密度的方法
- 谱聚类
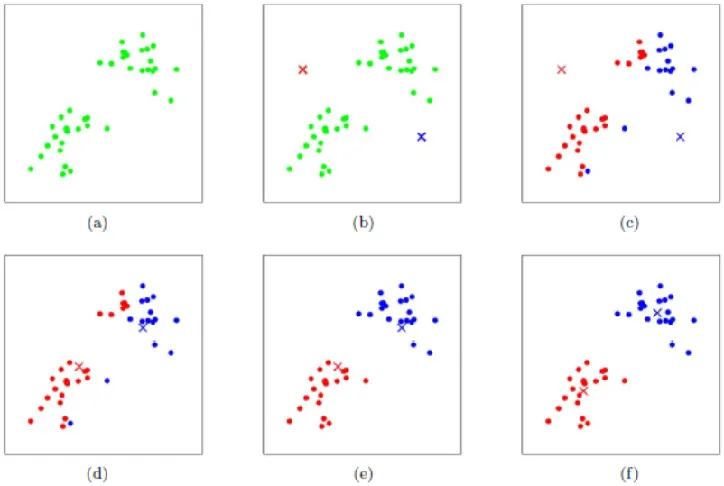
K-Means
从一个实例问题讲起
-
色彩量化问题
- 从连续空间向离散空间映射,例如,将24位真彩色(1600万种色)映射到256色彩空间
-
问题
- 如何保证图像清晰度
- 如何让失真度尽可能小
-
处理思路
- 按照色彩相似度,把色彩分为256个簇
- 通过聚类实现
-
K-Means聚类算法过程
- 色彩空间为三维,每个像素点为三维向量
- 随机选择K个像素的色彩向量作为聚类初值
- 初值为聚类中心mi,k = 256,按照与聚类中心的相似程度,把所有像素分为K个簇。
-
分组方法:最小距离法
与聚类中心距离近(相似度大)的像素聚成一个簇
∣ ∣ x t − m i ∣ ∣ = m i n ∣ ∣ x t − m j ∣ ∣ ||xt − mi|| = min||xt − mj|| ∣∣xt − mi∣∣ = min∣∣xt − mj∣∣
-
数据重构
-
重构误差公式
∗ E ( { m i } i = 1 k ∣ X ) = ∑ l ∑ i b i l ∣ ∣ x t − m i ∣ ∣ 2 ∗ *E(\{m_i\}_{i = 1}^k|X) = ∑_l∑_ib_i^l||x^t − m_i||^2* ∗E({mi}i = 1k∣X) = ∑l∑ibil∣∣xt − mi∣∣2∗
-
对于每个数据点,找到最近的聚类中心
-
误差计算:计算其与所属的聚类中心的距离平方相加,作为误差。
-
-
极小化误差函数
- 通过求导可知,各个分组的均值向量是误差最小聚类中心。
-
重复进行迭代,直至聚类中心不再改变,或者低于某一个阈值。
K-medoids(K-中心聚类)
- K-Means的初值是实际存在的样本点。
- 但迭代过程的聚类中心是虚拟的样本点(Means)
- K-Medoids就是在聚类过程中,仍然选择真实的样本点。
- 选择与Means最近的样本点为代表点。
聚类算法的评价
CHI指标
s ( k ) = t r ( B k ) t r ( W k ) m − k k − 1 s(k)=\frac{tr(B_k)}{tr(W_k)}\frac{m-k}{k-1} s(k)=tr(Wk)tr(Bk)k−1m−k
-
m:训练集样本数
-
k:簇数目
-
BK:簇间的协方差矩阵
-
WK:簇内协方差矩阵
-
tr:矩阵的迹
S越大,聚类效果越好
轮廓系数
S ( i ) = b ( i ) − a ( i ) m a x { a ( i ) , b ( i ) } S(i)=\frac{b(i)-a(i)}{max\{a(i),b(i)\}} S(i)=max{a(i),b(i)}b(i)−a(i)
-
a ( i ) a(i) a(i): i i i向量到簇内其它所有点的平均距离。
-
b ( i ) b(i) b(i): i i i向量到簇外其它所有点的最小距离。
-
介于 [ − 1 , 1 ] [-1,1] [−1,1]
-
将所有点的轮廓系数求平均,是聚类结果的总轮廓系数。
S越大,聚类效果越好
K-Means优缺点
- 优点
- 原理简单,实现容易,易收敛
- 聚类效果较优
- 算法可解释度强
- 缺点
- 对于非凸数据集难收敛
- 对于不平衡数据效果不佳
- 聚类结果为局部最优
- 噪声敏感
处理大数据
K-Means算法复杂度与维度成正比
数据规模很大,维度很高时,算法会很慢
解决方案
抽样
Mini Batch K-Means
- 按比例抽取小规模样本做k-means
- 多次抽样,检查聚类效果
提高算法效率
- 距离优化算法
- 设法减少计算距离的次数,不要每个点都计算一边
- elkan K-Means
-
利用两边之和大于第三边,两边之差小于第三边
-
例如: d ( x , c 1 ) = 5 , d ( c 1 , c 2 ) = 10 d(x,c_1)=5,d(c_1,c_2)=10 d(x,c1)=5,d(c1,c2)=10
则不用计算 d ( x , c 2 ) d(x,c_2) d(x,c2),可知 d ( x , c 2 ) d(x,c_2) d(x,c2)大于等于5。
-
EM算法
-
改变数据划分的方法
例如,采用完全版本的贝叶斯学习和预测思想
-
模型的输出从硬标签改为软标签。
直接输入后验概率(连续变量),称为软标签
过程简介
假设数据由k个高斯分布混合生成,每个高斯分布表示一个潜在的子群或簇。我们不知道样本点x属于哪个簇,因此需要 P ( G i ) P(G_i) P(Gi)表示该点属于某个簇的概率。
目标:估计模型参数 m i , S i , P ( G i ) m_i,S_i,P(G_i) mi,Si,P(Gi)
挑战:存在隐变量Z(样本所属簇的标签),直接最大化似然函数困难。
似然函数:
-
不完全似然(未观测到隐变量Z(数据点所属的高斯分布))
L ( θ ∣ X ) = ∑ i l o g ∑ j = 1 k P ( G j ) ⋅ p ( x i ∣ G j ) L(\theta|X)=\sum_i log\sum_{j=1}^kP(G_j)\cdot p(x^i|G_j) L(θ∣X)=i∑logj=1∑kP(Gj)⋅p(xi∣Gj)
P ( G i ) : P(G_i): P(Gi):第j个高斯分布的权重
p ( x i ∣ G j ) p(x^i|G_j) p(xi∣Gj):第j个高斯分布生成数据点 x i x^i xi的概率密度
外层 ∑ \sum ∑:连乘转加法,避免下溢
内层 ∑ \sum ∑:对所有可能的隐变量求和,表示 x i x^i xi可能由任意高斯分布生成。
该式直接优化困难,无法求解我们需要的三个参数。
-
完全数据似然(已经知道属于哪类):
假设已经知道数据点所属的高斯分布,那么似然函数就不需要 P ( G i ) P(G_i) P(Gi),可以简化为下式:
L C = ( θ ∣ X , Z ) = ∑ i l o g p ( x i , z i ∣ θ ) L_C=(\theta|X,Z)=\sum_ilog\ p(x^i,z^i|\theta) LC=(θ∣X,Z)=i∑log p(xi,zi∣θ)
由于对数内部无求和,可求解。
现实情况可能为不完全似然,即不知道样本属于哪类,因此需要通过EM方法迭代求解。
-
初值
- 高斯分布的参数
- **均值向量 m i m_i mi😗*每个高斯分布的均值(簇中心)
- **协方差矩阵 ∑ i ( S i ) \sum_i(S_i) ∑i(Si):**描述簇的形状和分布
- 混合系数 P ( G i ) P(G_i) P(Gi):每个高斯分布的权重
- 高斯分布的参数
-
E步
目标:根据当前参数,计算每个 x i x^i xi属于各个 G i G_i Gi的概率。
计算隐变量的后验概率(数据点x属于第i个高斯分布的概率)
γ i ( x ) = P ( G i ) ⋅ N ( x ∣ m i , ∑ i ) ∑ j = 1 k P ( G j ) ⋅ N ( x ∣ m j , ∑ j ) \gamma_i(x)=\frac{P(G_i)\cdot N(x|m_i,\sum_i)}{\sum_{j=1}^kP(G_j)\cdot N(x|m_j,\sum_j)} γi(x)=∑j=1kP(Gj)⋅N(x∣mj,∑j)P(Gi)⋅N(x∣mi,∑i)
N为高斯分布概率密度函数
数学形式:
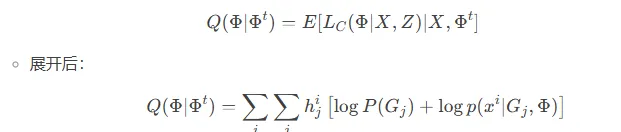
-
M步
目标:基于E步的隐变量分布,更新三个参数。
更新参数,最大化对数似然函数

-
混合系数 P ( G i ) P(G_i) P(Gi):
P ( G i ) = ∑ x γ i ( x ) N P(G_i)=\frac{\sum_x\gamma_i(x)}{N} P(Gi)=N∑xγi(x)
(N为总样本数)
-
-
迭代与收敛:
-
循环执行 E 步和 M 步,直至似然对数变化小于阈值或收敛:
L ( θ ∣ X ) = ∑ l o g ∑ j = 1 k P ( G j ) ⋅ p ( x i ∣ G j ) L(\theta|X)=\sum log\sum_{j=1}^kP(G_j)\cdot p(x^i|G_j) L(θ∣X)=∑logj=1∑kP(Gj)⋅p(xi∣Gj)
-