Python-pandas-操作csv文件(读取数据/写入数据)及csv语法详细分享
Python-pandas-操作csv文件(读取数据/写入数据)
提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码和运行结果且前后关联上的去分析和说明(能大量节约您的时间)。
所有文章都不会直接把代码放那里,让您自己去看去理解。我希望我的内容对您有用而努力~
python语法-pandas第三节-附 :本小节是 DataFrame全系列分享(使用.特点.说明.外部文件数据.取值.功能函数.统计函数)的 csv文件操作:读取数据及写入数据
详细的 DataFrame:
DataFrame全系列分享(数据结构.使用.特点.说明.外部文件数据.取值.功能函数.统计函数)
链接: DataFrame全系列分享
【上榜文章】一文搞定,非常详细的Python-Pandas - DataFrame全系列分享。大量案例且晦涩难懂的有大白话解释。详细的扩展内容也额外写了其他更加细节全面的文章链接在里面,来保证DataFrame的全部内容,本文就是其中一个扩展读写数据csv篇
文章目录
- Python-pandas-操作csv文件(读取数据/写入数据)
- 前言
- 一、读取数据
- 二、写入数据
- 其他csv操作函数
- head()方法
- tail()
- info()
- 总结
前言
CSV(Comma-Separated Values),其文件以纯文本形式存储的表格数据(数字和文本)。
CSV是表格格式的数据,有表头(列名),有一行一行的数据。
正好通过Pandas来操作这些数据的时候:DataFrame也是一种表格格式的数据类型
DataFrame系列分析见文件头部链接。
测试本文DataFrame操作csv代码之前,需要准备一个csv文件,如果没有怎么办?谁家好孩子自己创建一个空文件,后缀是csv,然后添数据呀,您可以复制下面代码:
Python文件操作的详细文章为:
链接: Python代码写入/读取文件语法
#快速预览整体 没数据版本代码
import csv#在同层级位置开启一个csv(没有就自动创建一个,有就打开)
#模式为 w(写入) 新行没有空行newline 编码utf-8 指定为别名 f
with open('data.csv','w',newline="",encoding='utf-8') as f:fwrite = csv.DictWriter(f,fieldnames=['id','name','age'])#指定csv列名fwrite.writeheader() #文件里写上表头 listdata = [{},{},{}] #列表里面有三个字典数据 fwrite.writerows(listdata)
#重点:就是把那三个字典 放到csv里面,目前语法csv也只认字典,因为:#writerows方法是需要传递list类型数据的 只能用[{}] 哪怕一个字典数据
#字典类型有key~ key就对应csv的表头
import csvwith open('data.csv','w',newline="",encoding='utf-8') as f:#声明写入器fwrite 传入f变量,且声明列名为:'id','name','age'fwrite = csv.DictWriter(f,fieldnames=['id','name','age'])#写入头部(csv文件就带表头) 这句代码不写,文件第一行就没有表头(影响看,不影响取值/写入。因为是写入器fwrite来决定 列,不是这句写入头部的代码)fwrite.writeheader()listdata = [{'id':1, #对应写入器的列名'name':'bangbangzhi', #三列'age':18 #我字典就三组 k-v},{'id':2, #一定要对应写入器的列名,不然它分不清楚,哪列放什么数据'name':'java','age':19},{'id':3, #您甚至可以把 这个字典的name Python 删了。 'name':'python', #它会在csv里面空一列'age':20 #就是为什么 必须对应上 写入器 列的原因}]fwrite.writerows(listdata)#这个方法 传列表类型,但是我们列表里面有带数据的字典#它就根据字典的key 对应放在csv的对应列里面#如:
运行,控制台没有反应的,毕竟我没有写print().。它会在当前层级位置,生成一个新的csv文件:data.csv
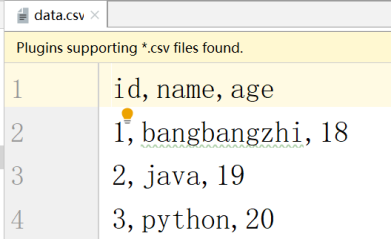
双击打开csv文件(您开发工具如果有csv插件,打开就是一个表格):
一、读取数据
使用pandas来读取csv,方法:
pd.read_csv(参数)
常用参数为:filepath_or_buffer (路径或文件对象),sep (分隔符),header (行标题),names (自定义列名),dtype (数据类型),index_col (索引列)
参数为:
| 参数名字 | 解释 |
|---|---|
| filepath_or_buffer | CSV 文件的路径或文件对象(支持 URL、文件路径、文件对象等) 必需参数 |
| sep | 定义字段分隔符,默认是逗号(,),可以改为其他字符,如制表符(\t) ‘,’ |
| header | 指定行号作为列标题,默认为 0(表示第一行),或者设置为 None 没有标题 0 |
| names | 自定义列名,传入列名列表 None |
| index_col | 用作行索引的列的列号或列名 None |
| usecols | 读取指定的列,可以是列的名称或列的索引 None |
| dtype | 强制将列转换为指定的数据类型 None |
| skiprows | 跳过文件开头的指定行数,或者传入一个行号的列表 None |
| nrows | 读取前 N 行数据 None |
| na_values | 指定哪些值应视为缺失值(NaN) None |
| skipfooter | 跳过文件结尾的指定行数 0 |
| encoding | 文件的编码格式(如 utf-8,latin1 等) None |
哪来这么多参数?pandas的这个DataFrame本身就可以指定很多指标数据。毕竟最终您读取了csv文件,是要在pandas里面去做数据分析的。没有指定好,后面数据分析的代码没法写,那读csv有什么用,对吧~可以看看文章最开始的那个链接DataFrame介绍 ღ( ・ᴗ・) 比心
import pandas as pd# 读取 CSV 文件,并自定义列名 分隔符 每列的类型
df = pd.read_csv('data.csv', sep=',', header=0, names=['id', 'name', 'age'],dtype={'id': int, 'name': str, 'age': float})
print(df)#names=['id', 'name', 'age']是DataFrame的列名(和csv无关),但是一般都遵守标准命名规范
#所以都是和csv的列一样
#这里列名也是可以看需求改的
标准的DataFrame结构(行索引从0开始~):
行索引是啥?然后怎么操作,怎么取值,emmmmm,哦。: DataFrame全系列分享

二、写入数据
使用pandas来写入csv文件来存储,方法:
pd.to_csv(参数)
我现在演示的代码,csv文件和代码文件同层级,但是数据放到csv里面了,关机开机啥的,csv里面的东西一直在,csv就像txt一样的
参数为:
| 参数名字 | 解释 |
|---|---|
| path_or_buffer | CSV 文件的路径或文件对象(支持文件路径、文件对象) 必需参数 |
| sep | 定义字段分隔符,默认是逗号(,),可以改为其他字符,如制表符(\t) ‘,’ |
| index | 是否写入行索引,默认 True 表示写入索引 True |
| columns | 指定写入的列,可以是列的名称列表 None |
| header | 是否写入列名,默认 True 表示写入列名,设置为 False 表示不写列名 True |
| mode | 写入文件的模式,默认是 w(写模式),可以设置为 a(追加模式) ‘w’ |
| encoding | 文件的编码格式,如 utf-8,latin1 等 None |
| line_terminator | 定义行结束符,默认为 \n None |
| quoting | 设置如何对文件中的数据进行引号处理(0-3,具体引用方式可查文档) None |
| quotechar | 设置用于引用的字符,默认为双引号 " ‘"’ |
| date_format | 自定义日期格式,如果列包含日期数据,则可以使用此参数指定日期格式 None |
| doublequote | 如果为 True,则在写入时会将包含引号的文本使用双引号括起来 True |
import pandas as pd# 准备一些数据
name = ["hello", "python", "bangbangzhi", "emmm"]
bobby = ["eat", "sheep", "play", "what"]
age = [18, 19, 20, 100]
# 字典
dict = {'name': name , 'bobby': bobby, 'age': age}
df = pd.DataFrame(dict)
#随便写一个DataFrame
#至于怎么代码生成DataFrame 万一看不明白啥的~没事。 那个链接指向的文章很全的。
#本篇是 声明DataFrame语法模块内容里面的,,,小小分支 csv数据来源声明DataFrame额外分支篇文章# 保存 dataframe
#主要就演示这句
df.to_csv('site.csv') #还是一样的,当前代码文件的同层级位置生成新的csv
可以再来一个,懒得往上翻嘛:
详细的 DataFrame:
DataFrame全系列分享(数据结构.使用.特点.说明.外部文件数据.取值.功能函数.统计函数)
链接: DataFrame全系列分享
其他csv操作函数
head()方法
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pddf = pd.read_csv('data.csv')#我演示语法 ,数据总共才3行呢,我那个添加数据 字典篇幅不能太多了,哦~
print(df.head()) #返回前5行在控制台
print(df.head(10)) #返回前10行在控制台 #也不用非得print(),没事儿输出前5行干啥,这个方法一般先取出一部分数据,来测试格式
#为数据分析 整篇csv全部内容 做铺垫准备
tail()
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
import pandas as pddf = pd.read_csv('data.csv')print(df.tail()) #返回最后5行在控制台
print(df.tail(10)) #返回最后10行在控制台 #和head很像
info()
方法返回表格的一些基本信息
import pandas as pddf = pd.read_csv('data.csv')
#查看信息
print(df.info())
#能看总行数 每列的名字 和数据类型
总结
(会陆续更新非常多的IT技术知识及泛IT的电商知识,可以点个关注,共同交流。ღ( ´・ᴗ・` )比心)
(也欢迎评论,提问。 我会依次回答~)