使用模块中的`XPath`语法提取非结构化数据
想要在代码中使用Xpath进行处理,就需要模块lxml
模块安装
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
lxml的使用
- 使用
lxml转化为Element对象
from lxml import etreetext = ''' <div> <ul> <li class="item-1"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> '''# 利用etree.HTML,将字符串转化为Element对象, Element对象具有XPath的方法
html = etree.HTML(text)
print(type(html))# 将Element对象转化为字符串
handled_html_str = etree.tostring(html).decode()
print(handled_html_str)
- 使用
lxml中的XPath语法提取数据
提取a标签属性和文本
from lxml import etreetext = ''' <div> <ul> <li class="item-1"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> '''html = etree.HTML(text)# 获取href的列表和title的列表
href_list = html.xpath("//li[@class='item-1']/a/@href")
title_list = html.xpath("//li[@class='item-1']/a/text()")for title, href in zip(title_list, href_list):item = dict()item["title"] = titleitem["href"] = hrefprint(item)
以上代码必须确保标签中的数据是一一对应的,如果有些标签中不存在指定的属性或文本则会匹配混乱。
from lxml import etreetext = ''' <div> <ul><li class="item-1"><a>first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul> </div> '''html = etree.HTML(text)# 获取href的列表和title的列表
href_list = html.xpath("//li[@class='item-1']/a/@href")
title_list = html.xpath("//li[@class='item-1']/a/text()")for title, href in zip(title_list, href_list):item = dict()item["title"] = titleitem["href"] = hrefprint(item)
输出结果为:
/Users/poppies/python_envs/base/bin/python3 /Users/poppies/Documents/spider_code/1.py
{'title': 'first item', 'href': 'link2.html'}
{'title': 'second item', 'href': 'link4.html'}
XPath分次提取
前面我们取到属性,或者是文本的时候,返回字符串 但是如果我们取到的是一个节点,返回什么呢?
返回的是element对象,可以继续使用xpath方法
对此我们可以在后面的数据提取过程中:先根据某个xpath规则进行提取部分节点,然后再次使用xpath进行数据的提取
示例如下:
from lxml import etreetext = ''' <div> <ul><li class="item-1"><a>first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul> </div> '''html = etree.HTML(text)li_list = html.xpath("//li[@class='item-1']")
print(li_list)可以发现结果是一个element对象,这个对象能够继续使用xpath方法
先根据li标签进行分组,之后再进行数据的提取
from lxml import etreetext = ''' <div> <ul><li class="item-1"><a>first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul> </div> '''html = etree.HTML(text)li_list = html.xpath("//li[@class='item-1']")
print(li_list)# 在每一组中继续进行数据的提取
for li in li_list:item = dict()item["href"] = li.xpath("./a/@href")[0] if len(li.xpath("./a/@href")) > 0 else Noneitem["title"] = li.xpath("./a/text()")[0] if len(li.xpath("./a/text()")) > 0 else Noneprint(item)总结
lxml库的安装:pip install lxmllxml的导包:from lxml import etree;lxml转换解析类型的方法:etree.HTML(text)lxml解析数据的方法:data.xpath("//div/text()")- 需要注意
lxml提取完毕数据的数据类型都是列表类型 - 如果数据比较复杂:先提取大节点, 然后再进行小节点操作
8.练习:通过XPath提取豆瓣电影评论
要求
爬取豆瓣电影的评论,地址链接:https://movie.douban.com/subject/1292052/comments?status=P
提示
先在浏览器中使用插件XPath Helper进行XPath语法测试,效果如下:
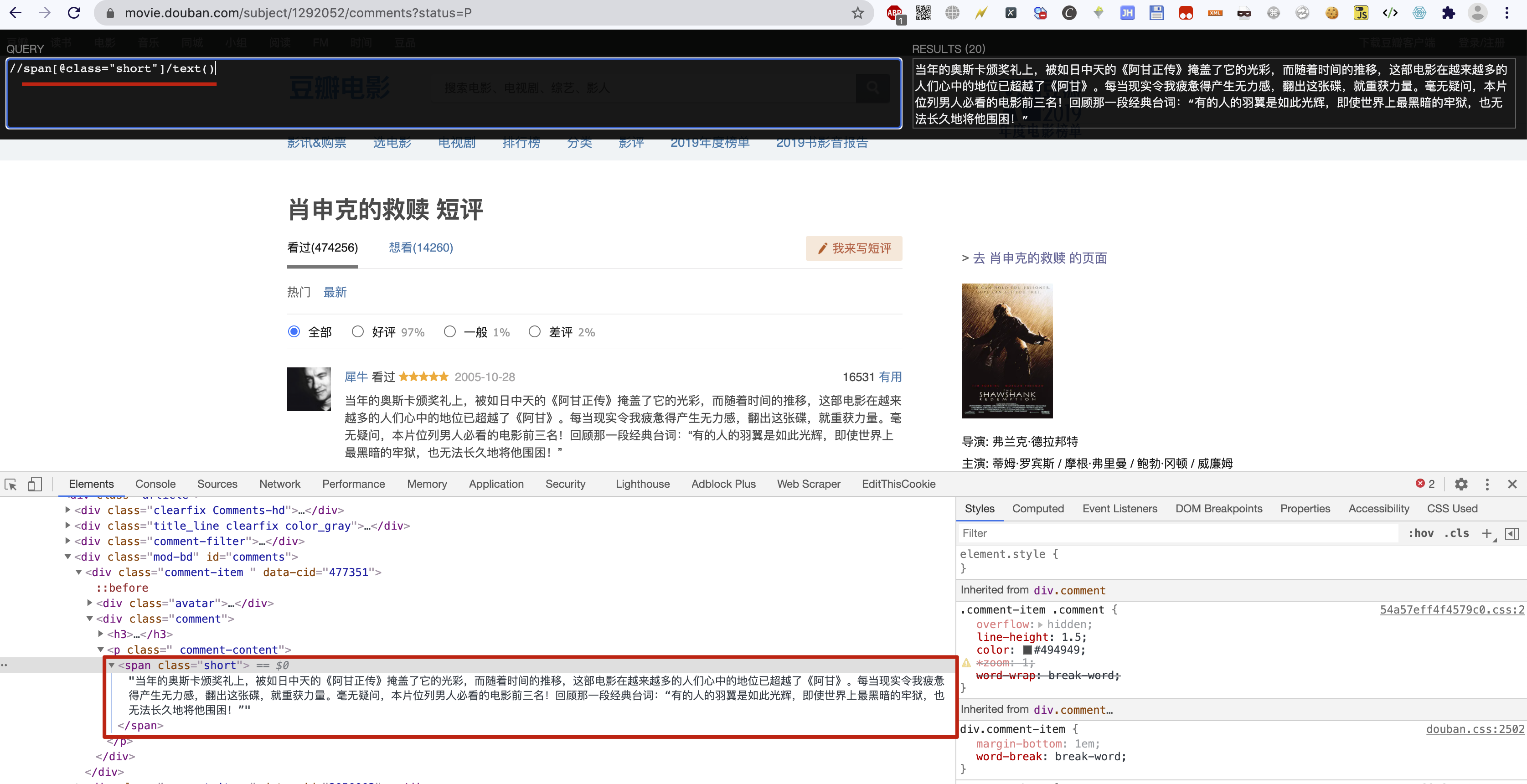
代码示例
import requests
from lxml import etree"""
流程分析:
1. 通过requests发送请求获取豆瓣返回的内容
2. 将返回的内容通过etree.HTML转换为Element对象
3. 对Element对象使用XPath提取数据
"""# 1. 通过requests发送请求获取豆瓣返回的内容
url = "https://movie.douban.com/subject/1292052/comments?status=P"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36",
}
r = requests.get(url=url, headers=headers)# print(r.text)# 2. 将返回的内容通过etree.HTML转换为Element对象
html = etree.HTML(r.text)# 3. 对Element对象使用XPath提取数据
comment_list = html.xpath('//span[@class="short"]/text()')print("提取到的个数:", len(comment_list))for comment in comment_list:print(comment)print('\n')