Golang 并发编程
引言
因为服务器开发使用的是 go 语言,工作中业务中遇到并发的场景也很常见,这篇文档主要介绍一下 go 语言中与并发相关的内容
定义
并发
并发(Concurrency)是指在同一时间段内处理多个任务的能力。它并不意味着多个任务同时运行,而是多个任务可以交替进行,共享系统资源以提升程序的响应性和资源利用率。在现代软件开发中,并发编程已经成为提升程序性能和用户体验的重要手段,尤其在处理 I/O 密集型或高并发访问的场景下,能够有效降低资源占用和响应延迟。
Golang 原生支持
协程与通道
在 Go 语言中,并发是语言的核心特性之一。Go 天生支持并发,其并发模型不同于传统的线程/锁机制,它引入了一种更轻量、更安全的方式 Goroutine 与 Channel。
- Goroutine 是 Go 的轻量级线程,由 Go 运行时调度管理,使用极少的内存开销即可创建成千上万个 Goroutine,以便安全地执行内存清理操作。STW 会让所有业务逻辑短暂停止运行,导致请求处理变慢甚至出现延迟抖动,特别是在高并发或对响应时间要求严格的场景中会影响用户体验。
- **写屏障(Write是 Goroutine 之间通信的桥梁,Go 倡导"不要通过共享内存来通信,而要通过通信来共享内存"。
得益于这种设计,Go 的并发模型更加简洁、直观,程序员可以专注于业务逻辑的编写,而无需过多考虑线程安全和复杂的锁机制。
本文将围绕 Go 的并发编程展开,介绍其核心概念、使用方式以及常见的并发模式,帮助你构建出高性能、可维护的并发应用程序。
协程
Goroutine 也被称为协程,只需要在函数调用前加上 go 关键字,即可创建一个新的 Goroutine:
package mainimport ("fmt""time"
)func sayHello() {fmt.Println("Hello from goroutine")
}func main() {go sayHello() // 启动一个新的 goroutinetime.Sleep(time.Second) // 主程序等待一段时间,以便 goroutine 执行完fmt.Println("Main function ends")
}
注意:
- 同时 go 语法对于当前代码块是异步的操作,不会阻塞当前线程的操作
- main 函数结束后,所有 Goroutine 会一并退出,因此需要确保主程序等待它们完成(例如通过 WaitGroup 或 Channel 等方式)。所以一般的 go 项目会有个阻塞操作在主线程
通道
在 Go 中,Channel 是用来在多个 Goroutine 之间传递数据的管道。它是并发安全的,支持阻塞式通信,让我们能非常自然地实现 Goroutine 间的协作。
func worker(id int, ch chan int) {for task := range ch {fmt.Printf("Worker %d processing task %d\n", id, task)}
}func main() {ch := make(chan int)go worker(1, ch)go worker(2, ch)for i := 0; i < 5; i++ {ch <- i}close(ch)
}
输出可能为
Worker 1 processing task 0
Worker 2 processing task 1
Worker 1 processing task 2
Worker 2 processing task 3
Worker 1 processing task 4
📌 补充知识点
| 特性 | 说明 |
|---|---|
| 无缓冲 Channel | make(chan T),发送和接收都会阻塞,直到对方准备好(同步通信) |
| 有缓冲 Channel | make(chan T, n),最多可存 n 个元素,发送方先入队,不会立即阻塞 |
| close(chan) | 关闭 Channel,接收方仍可读取剩余数据,但不能再发送 |
| range chan | 可以使用 for range 遍历 channel,直到其被关闭 |
| select | 类似 switch 的语法,可以监听多个 channel 的操作 |
总结
- Channel 是 Go 中用于 Goroutine 通信的核心机制,提供安全、同步的数据传递。
- 通过 Channel 可以轻松实现任务分发、协作同步、信号通知等并发模式。
- 搭配 select、range、close 等关键字,可以构建非常灵活的并发逻辑。
- 其他语言通过共享内容来进行通信,而 go 语言通过 channel 通信来共享内存。
疑问
看完上面,可能初学 go 的同学就会有个疑问,goroutine 是基于的那个线程的,那么 go 程序都运行在一个线程上吗?它是怎么分配资源调度线程的呢?
GMP 调度模型
什么是协程
在 Go 中,Goroutine 是一种比线程更小的调度单位,可以简单地理解为 Go 实现的“轻量级线程”,是 Go 并发的基本执行单元。可以把 Goroutine 看作 Go 自己实现的"协程",是用户态的线程,而不像操作系统线程那样直接由内核管理。
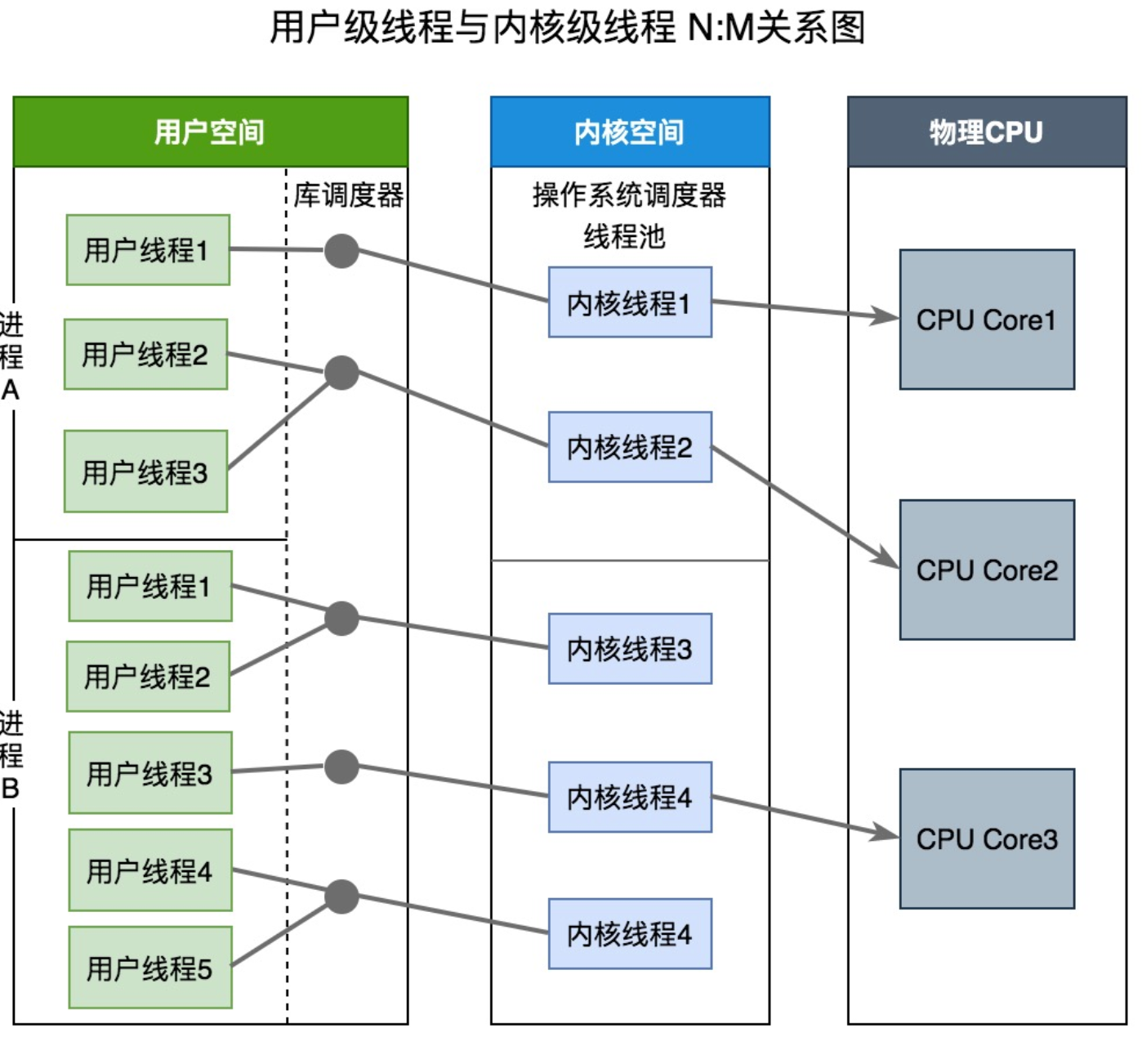
什么是 GMP
- G:goroutine协程,基于协程建立的用户态线程
- M:machine,它直接关联一个 os 内核线程,用于执行 G
- P:processor 处理器,P 里面一般会存当前 goroutine 运行的上下文环境(函数指针,堆栈地址及地址边界),P 会对自己管理的 goroutine 队列做一些调度
在Go中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上
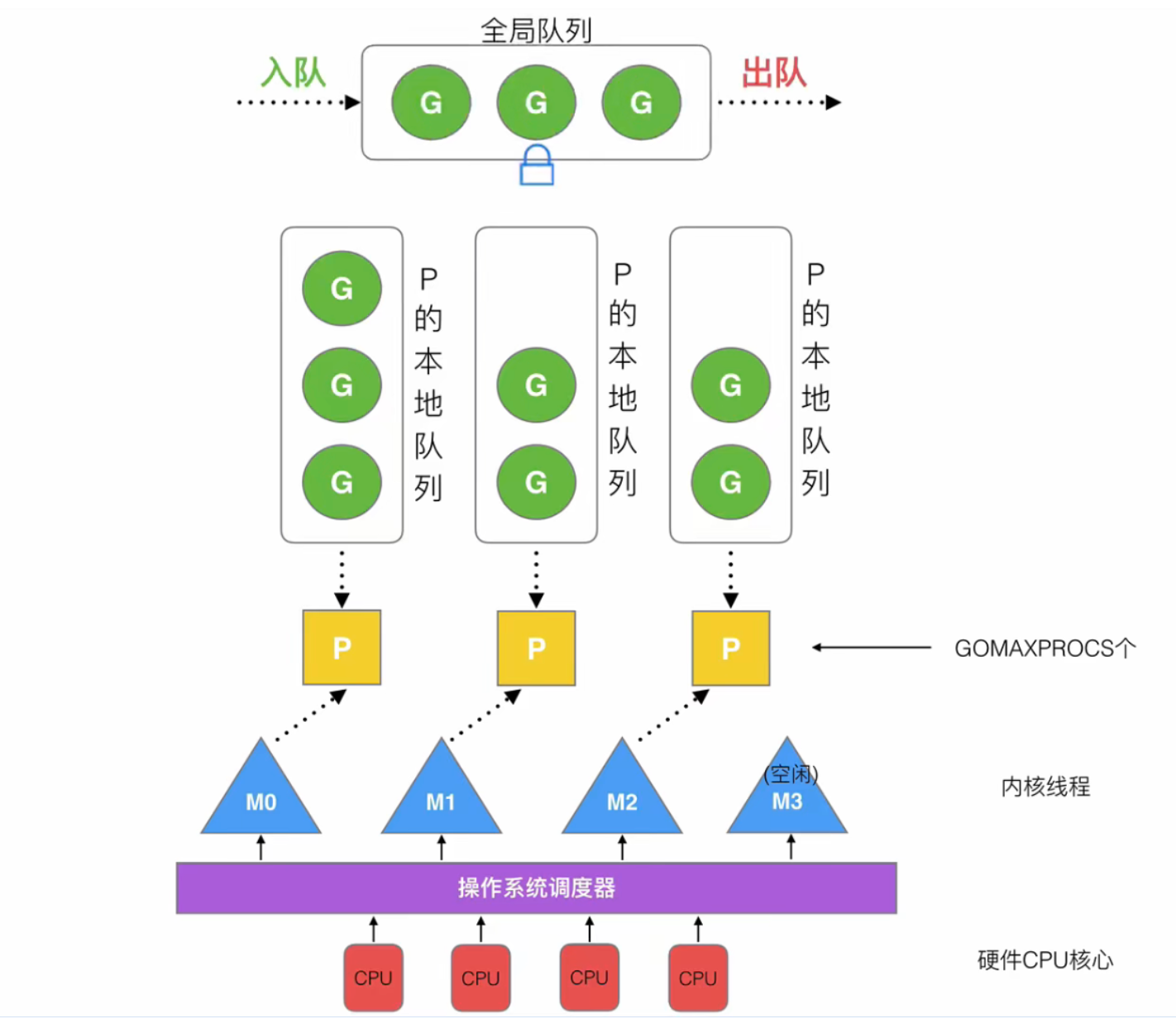
- 全局队列(Global Queue):存放等待运行的 G
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建G 时,G 优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS (可配置) 个
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列一半放到自己 P 的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去
P和M的数量问题
- P的数量:环境变量
$GOMAXPROCS;在程序中通过runtime.GOMAXPROCS()来设置- M的数量:GO语言本身限定一万 (但是操作系统达不到);通过
runtime/debug包中的SetMaxThreads函数来设置;有一个 M 阻塞,会创建一个新的 M;如果有 M 空闲,那么就会回收或者休眠M 与 P的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是1,也有可能会创建很多个M出来
GMP 调度流程
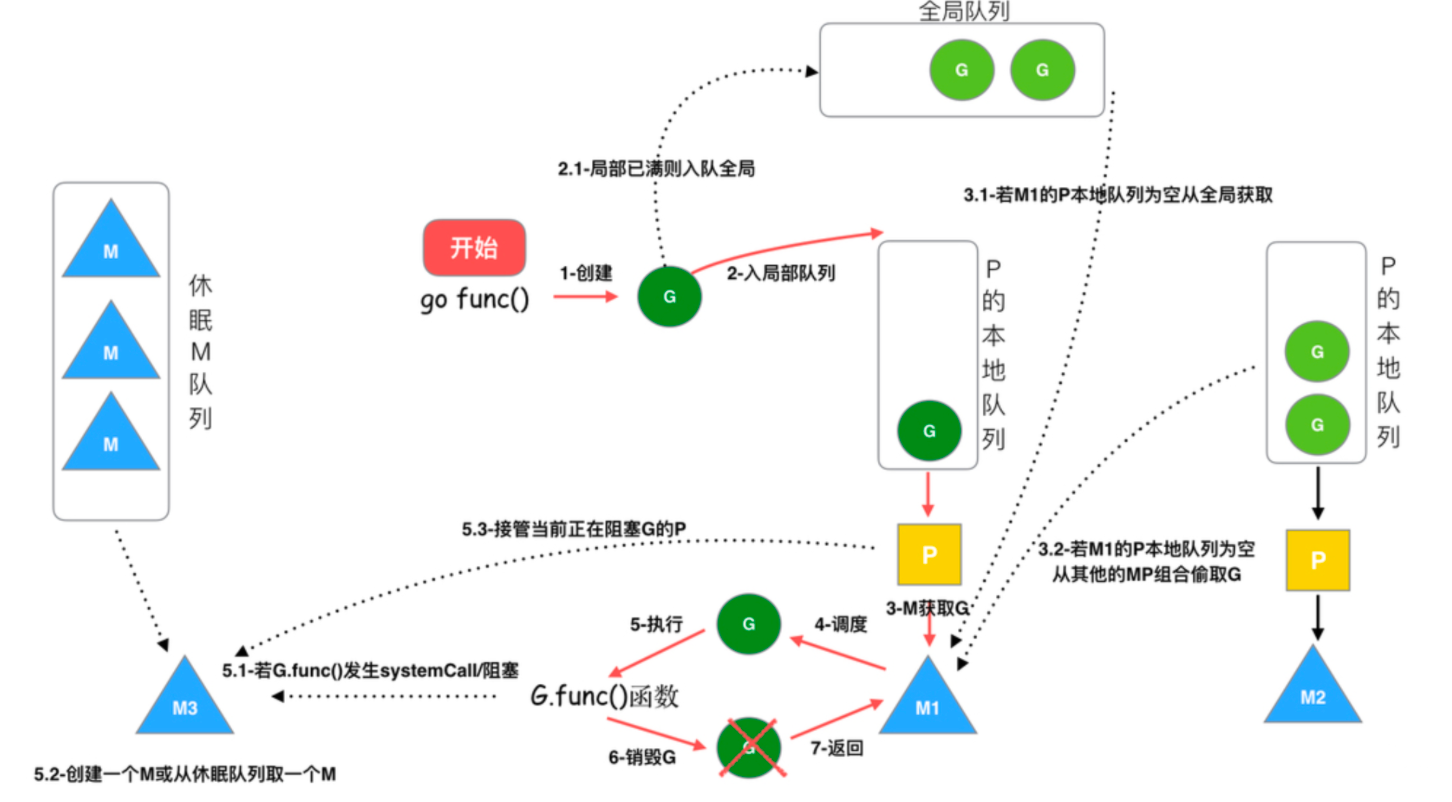
- 我们通过 go func() 来创建一个 goroutine
- 有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G会先保存在P的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中
- G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行
- 一个 M 调度 G 执行的过程是一个循环机制
- 当M执行某一个 G 时候如果发生了 syscall 或者其他阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个 P
- 当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的P执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中
如何充分发挥作用的
Go 能实现高并发,是因为它用 Goroutine(用户态协程)+ GMP 调度器,将大量的轻量任务映射到少量线程上高效运行,实现了资源复用、低开销切换、自动调度,而配合 CSP 模型的通信方式,大大降低了并发编程的复杂度。
接下来解释下对于资源复用、低开销切换、自动调度三个词的理解,以及如何在 GMP 中体会出来
如何理解资源复用:
Golang:
- 很多个 Goroutine(G)复用一个线程(M)
- 一个线程可以顺序执行多个 G,当前 G 阻塞后,线程马上执行下一个 G,不会闲着
在 GMP 中体现为:P 中有一个 Goroutine 队列,每个 P 会将自己的任务交给绑定的 M(线程)执行,执行完一个 G1,立马切换下一个 G2,同一个线程就像流水线工人一样不停轮转
传统模型:
- 每个任务需要创建一个线程(系统资源大)
- 每个线程都需要独占栈内存、文件描述符、调度上下文等资源
如何理解低开销切换:
Golang:
- Go 自己管理(运行时调度器在用户态完成切换)
- Goroutine 的栈是可增长的,初始仅 2KB,比线程动辄几 MB 要小很多
- Goroutine 切换不会触发内核参与,无需系统调用
在 GMP 中体现为:多个 G 任务都在 P 的本地队列中,P 调度时,只需调整一个结构体指针(G),就能切换任务线程 M 不变,只换运行的 G,这就是 协程级切换,非常便宜
传统模型:
- CPU 上下文切换
- 内核态/用户态切换
- Cache 失效、TLB Flush 等硬件成本
如何理解自动调度:
Golang:
- Goroutine 被放入 P 的本地队列,或者全局队列
- P 空闲时会尝试从其他 P 偷任务(Work Stealing 算法)
- 阻塞的 G 会被挂起,不影响 P 执行其他任务
- Goroutine 数量多时,会动态创建新线程(M)辅助执行
在 GMP 中体现为:你写的是 go someFunc(),就把 G 交给调度器处理了Go 会决定何时运行它、在哪个线程运行,调度器具备 负载均衡、抢占、调度队列 等复杂策略
这里介绍的上下文等细节啥的可能没有那么全面,有兴趣的可以看 github 上的 golang大杀器GMP模型
sync 包相关
| 组件 | 作用描述 | 常见场景 |
|---|---|---|
| sync.Mutex | 互斥锁,保证同一时间只有一个 Goroutine 访问临界区 | 写共享变量 |
| sync.RWMutex | 读写锁,允许多个读同时,但写是排他的 | 高读低写的缓存 |
| sync.WaitGroup | 等待一组 Goroutine 完成 | 并发任务同步 |
| sync.Once | 确保某段代码只执行一次(线程安全) | 单例初始化、懒加载 |
| sync.Cond | 条件变量,多个 Goroutine 等待/广播某个条件变化 | 生产者消费者模型、阻塞调度器 |
| sync.Map | 并发安全的 map(内置锁) | 多线程缓存、统计信息 |
实际场景
Mutex
- 修改共享变量(如计数器、状态位)
- 避免同时写 map(普通 map 并发写会 panic)
var mu sync.Mutexmu.Lock()
// 临界区
mu.Unlock()
RWMutex
RLock() / RUnlock():多个读可以并发进行
Lock() / Unlock():写是排他的,读写之间互斥
- 缓存读取、多读少写的情况
var data = make(map[string]string)
var mu sync.RWMutexfunc read(key string) string {mu.RLock()defer mu.RUnlock()return data[key]
}func write(key, value string) {mu.Lock()defer mu.Unlock()data[key] = value
}
WaitGroup
适合并发多个任务并且需要等待所有完成才往下一步走
- 并发请求多个接口
- 并发执行多个数据处理任务
- 并发日志/指标刷写任务
var wg sync.WaitGroup
wg.Add(1)go func() {defer wg.Done()// 任务
}()wg.Wait() // 阻塞直到 Done 次数等于 Add
Once
保证某段代码(如初始化)只执行一次,线程安全
var once sync.Onceonce.Do(func() {// 初始化逻辑
})
Cond
不太常用,但适用于更底层的阻塞唤醒模型
cond := sync.NewCond(&sync.Mutex{})go func() {cond.L.Lock()cond.Wait() // 等待通知cond.L.Unlock()
}()cond.L.Lock()
cond.Signal() // 通知一个等待的 goroutine
cond.L.Unlock()
Map
sync.Map 是 Go 标准库提供的"线程安全 Map",不需要显式加锁。
- 内部带分段锁/读写优化
- 避免热点锁问题(比你手写 map+RWMutex 性能好)
var m sync.Mapm.Store("key", 123)
val, ok := m.Load("key")
m.Delete("key")
**注意:**假如是分布式的场景需要用到锁限制并发的话,还是使用分布式锁会更加符合一点。
其他
其他线程模型
Rector 与 Proactor 模型
总结
引用
Golang GMP 大杀器
Golang 并发编程https://pkg.go.dev/sync@go1.22.4#pkg-types