HRScene:首个覆盖多场景高分辨率图像理解的综合性基准数据集
2025-04-25,由宾夕法尼亚州立大学和亚马逊网络服务的研究团队创建了 HRScene 数据集,这是一个用于高分辨率图像(HRI)理解的统一基准数据集。该数据集整合了 25 个真实世界的数据集和 2 个合成诊断数据集,涵盖了从微观到遥感的丰富场景,分辨率从 1024×1024 到 35,503×26,627。HRScene 的创建填补了高分辨率图像理解领域的空白,为评估视觉语言模型在高分辨率图像处理上的有效性提供了重要工具。
一、研究背景
高分辨率图像(HRI)理解是指处理像素数量极多的图像,例如病理图像和农业航拍图像,这些图像的像素数可能超过 100 万。随着视觉语言模型(VLMs)的发展,自动处理高分辨率图像成为了一个有前景的方向。然而,目前缺乏一个全面的基准来评估 VLMs 在高分辨率图像理解上的表现。
目前遇到的困难和挑战:
1、缺乏统一基准:现有的 VLMs 评估基准大多集中在低分辨率图像上,平均分辨率通常低于 1k,无法满足高分辨率图像理解的需求。
2、场景覆盖不足:现有的高分辨率数据集往往专注于特定场景(如长距离图像)或特定分辨率(如 8k),缺乏全面性和多样性。
3、模型性能瓶颈:尽管 VLMs 声称能够处理高分辨率图像,但在实际应用中,如何有效利用高分辨率图像的区域信息仍然是一个挑战。
数据集地址:HRScene|高分辨率图像理解数据集|视觉语言模型数据集
二、让我们一起看一下HRScene
HRScene 是一个涵盖 25 个真实世界场景和 2 个合成诊断数据集的高分辨率图像理解基准,分辨率范围从 1024×1024 到 35,503×26,627 。
HRScene 数据集由 10 位研究生级标注人员重新标注,覆盖了从微观到放射学图像、街景、长距离图像和望远镜图像等多种场景。它包括真实世界的物体图像、扫描文档和多图像合成。此外,两个诊断评估数据集通过将目标图像与答案图像和干扰图像组合而成,用于评估模型对高分辨率图像区域的利用能力。
数据集构建:
1、全面性:覆盖多种真实世界场景,包括日常图片、城市规划、文档扫描、艺术品、多子图像、遥感、医学诊断和研究理解等。
2、多样性:包含不同类型的数据,如单图像和多图像数据,专家和非专家级别的问答,以及小目标检测和全局图像理解任务。
3、易用性:每个任务的数据量适中,便于验证和使用。
数据集特点:
1、高分辨率:所有数据集的分辨率均高于 1k,部分数据集的分辨率高达数千万像素。
2、多样化场景:涵盖从微观到望远镜图像的多种场景。
3、诊断性测试:包含两个合成诊断数据集,用于评估模型在高分辨率图像中的区域利用能力和抗干扰能力。
数据集使用:
HRScene 数据集分为验证集、测试迷你集和标准测试集。
验证集包含 750 个样本,用于模型调试;
测试迷你集包含 1000 个样本,适用于快速评估;
标准测试集包含 5323 个样本,用于最终评估。
测试集的答案标签不会公开,以确保公平性。
基准测试:
在对 28 种流行的 VLMs 进行评估后,结果显示当前 VLMs 在真实世界任务上的平均准确率仅为 50% 左右,暴露出高分辨率图像理解的巨大挑战。
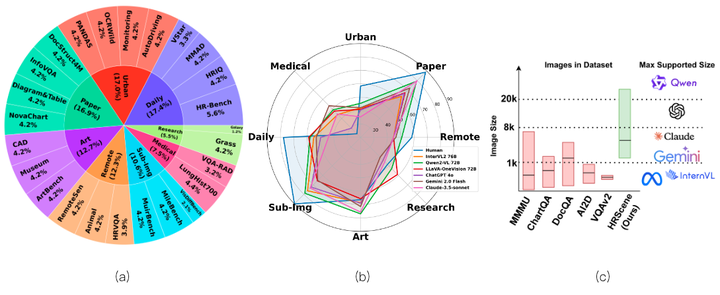
(a) HRScene 的概述分类。 (b) 一些 VLMs 在 HRScene 上的性能。 (c) 主流 VLMs 评估的基准与 HRScene 的比较。
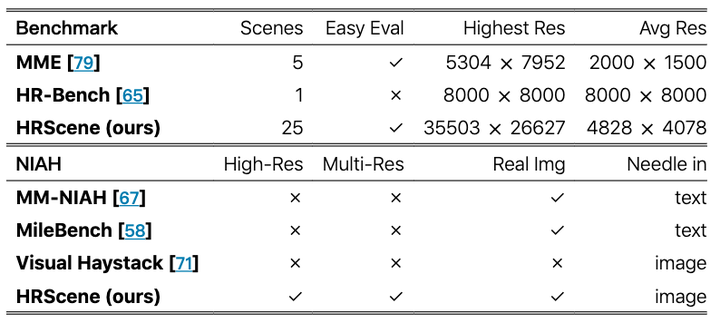
与现有现实世界基准和多模态 NIAH 诊断的比较
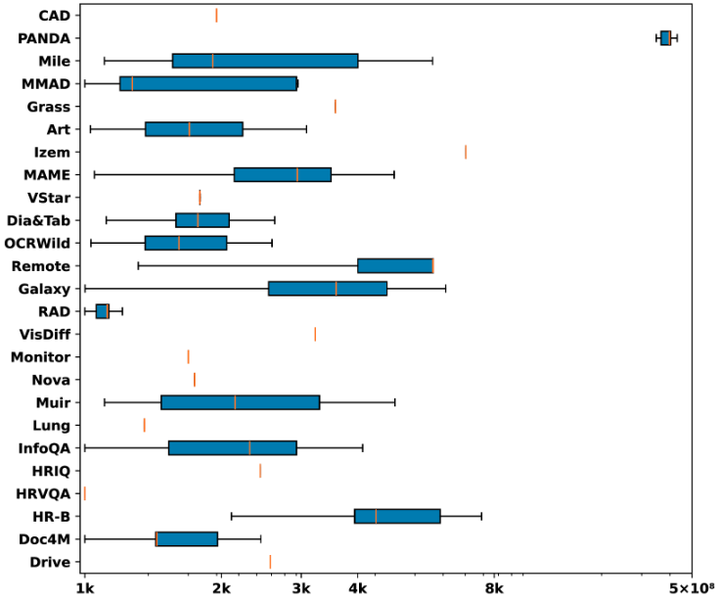
每个数据集的分辨率分布
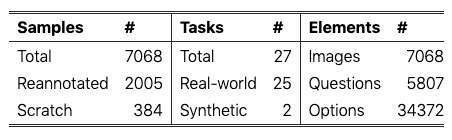
HRScene 的一般统计信息。
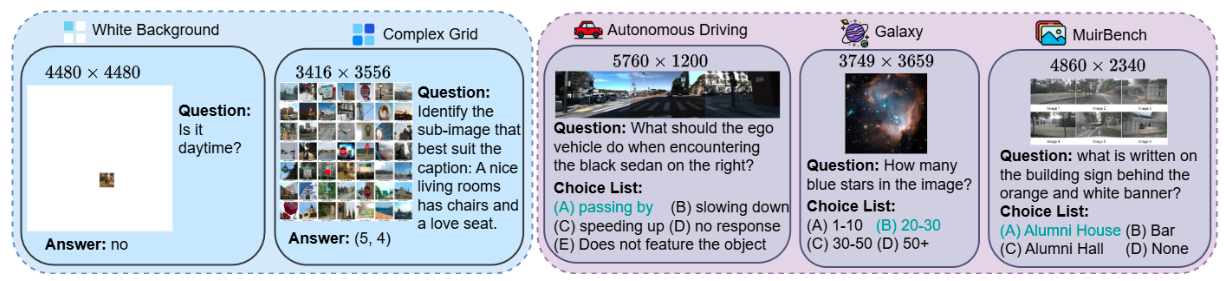
HRScene 的一些示例。蓝色的是诊断数据集,紫色的是真实世界数据集。
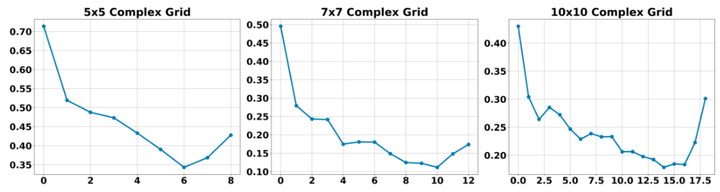
所有数据集点和所有 18 个 VLM 的平均区域性能。
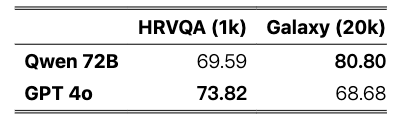
表 5:在两个数据集上 Qwen 72B 和 GPT 4o 的细粒度比较。
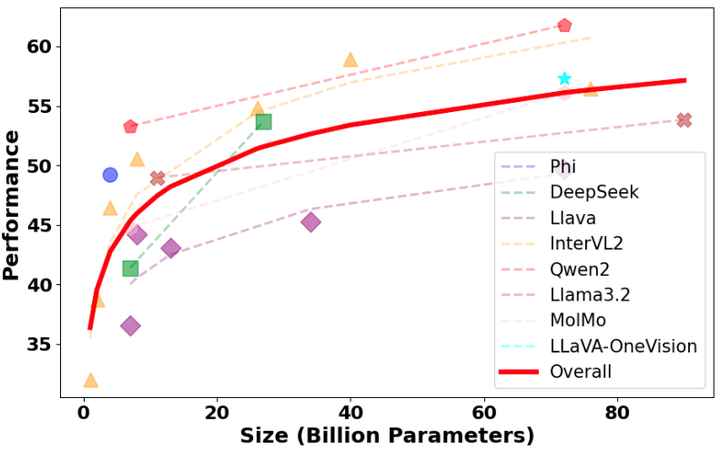
图 6:模型性能与模型参数大小的关系。
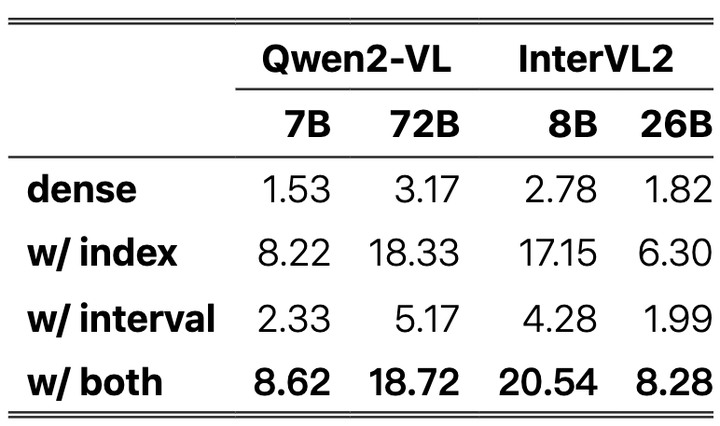
不同图像组合方法的消融研究。
三、展望HRScene应用场景
1、日常图片
比如你用高分辨率相机拍的照片,HRScene 可以帮助模型理解照片中的内容,比如识别照片中的物体、场景和活动。
2、城市规划
包括自动驾驶场景,模型需要识别街景中的车辆、行人和交通标志,帮助自动驾驶系统做出决策。
3、文档扫描:
对于复杂的文档图像,HRScene 可以测试模型是否能够准确识别文档中的文字、图表和布局。
4、艺术品理解:HRScene 包含了多种艺术风格的绘画作品,模型需要识别绘画的风格、主题和细节。
更多免费的数据集,请打开:遇见数据集
遇见数据集-让每个数据集都被发现,让每一次遇见都有价值。遇见数据集,领先的千万级数据集搜索引擎,实时追踪全球数据集,助力把握数据要素市场。![]() https://www.selectdataset.com/
https://www.selectdataset.com/