基于AutoDL V100微调DeepSeek Coder 6.7B (2)
1.工具准备
- transformers:用于加载和训练大模型。
- peft:用于低秩适配(LoRA)训练方法。
- datasets:加载JSON数据集。
Transformers:
AutoTokenizer:自动加载与模型对应的 分词器(Tokenizer),用于将文本转化为模型输入(input_ids等)。
AutoModelForCausalLM:加载支持“因果语言建模(Causal Language Modeling)”的预训练模型。
TrainingArguments:配置训练参数,如 batch size、learning rate、日志保存间隔等。
Trainer:Hugging Face 提供的高层封装的训练器,支持微调、评估、保存模型等功能。
DataCollatorForLanguageModeling:对训练数据进行批处理(collate),用于语言建模任务。
BitsAndBytesConfig:配置 模型量化参数,比如是否启用4bit、使用哪种量化方式(如 NF4)。
Peft:
prepare_model_for_kbit_training:在使用量化模型训练前,对模型进行预处理。
LoraConfig:定义 LoRA 微调的配置参数。
get_peft_model:将 LoRA 模块集成到原始模型中,只训练极少量 LoRA 参数,其余参数保持冻结。这样可以在不破坏预训练能力的基础上,快速微调模型以适应新任务。
TaskType:定义你的微调任务类型,这里使用SEQ_2_SEQ_LM(序列到序列任务,用于翻译、摘要等)
任务类型 (TaskType) | 说明 | 常用模型示例 |
|---|---|---|
CAUSAL_LM | 因果语言建模(自回归),用于文本生成任务 | GPT、DeepSeek、LLaMA、Mistral |
SEQ_2_SEQ_LM | 序列到序列任务(编码器-解码器),用于翻译、摘要等 | T5、BART、FLAN-T5 |
TOKEN_CLS | Token 级别分类,如命名实体识别 NER | BERT、RoBERTa |
SEQ_CLS | 序列分类任务,如情感分析、文本分类 | BERT、RoBERTa |
QUESTION_ANSWERING | 提问-回答任务,如阅读理解(SQuAD) | BERT、RoBERTa |
IMAGE_CLASSIFICATION | 图像分类任务 | ViT、ConvNeXt 等视觉模型 |
MULTIPLE_CHOICE | 多选题任务,如 SWAG、RACE | BERT、RoBERTa |
OBJECT_DETECTION | 目标检测(用于视觉模型) | YOLO、DETR 等 |
VISION2TEXT | 图文生成,如图像字幕生成(Image Captioning) | BLIP、ViLT |
FEATURE_EXTRACTION | 特征提取(不常用) | 任意模型提取中间层表示 |
2.模型准备
(1)模型量化:
模型量化是指将模型中使用的数值精度从高精度降低为低精度的方法,以减少模型的计算需求和内存占用,常用于部署大模型到资源受限的设备或加速推理/训练过程。
| 类型 | 精度 | 特点 | 适用场景 |
|---|---|---|---|
| FP16 | 16-bit float | 减少内存使用,支持GPU原生计算 | 微调、推理 |
| INT8 | 8-bit int | 内存和速度显著下降,准确率略损 | 推理部署、移动设备 |
| 4-bit(NF4) | 4-bit float-like | 极限压缩,结合QLoRA使用,保留准确性 | 参数高效微调(QLoRA) |
在这里为了降低训练成本选择使用NF4
bnb_config = BitsAndBytesConfig(load_in_4bit=True, #开启四位量化bnb_4bit_quant_type="nf4", #使用NormalFloat4量化格式(高精度)bnb_4bit_use_double_quant=True, #启用double quantization(二次压缩,更有空间)bnb_4bit_compute_dtype=torch.float16 # 前向计算时使用 float16 精度(兼顾精度与速度)
)加载Tokenizer(分词器):将自然语言文本编码为模型输入的token(input_ids)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
参数说明:
model_path:模型文件夹或HuggingFace模型名。
trust_remote_code:允许加载自定义模型或 tokenizer 结构(DeepSeek 等大模型常用)。
加载并量化模型
model = AutoModelForCausalLM.from_pretrained(model_path,quantization_config=bnb_config, # 应用上面定义的 4-bit 量化配置device_map="auto", # 自动将模型切分分配到可用设备(多卡/单卡)trust_remote_code=True # 信任远程自定义代码(必须对非标准结构模型)
)
参数说明:
model_path:模型文件夹。
quantization_config:使用设置好的量化配置。
device_map:自动将模型加载到 GPU,适用于多个 GPU 或 AutoDL 的环境。
trust_remote_code:(同上)
准备模型进行QLoRA微调
model = prepare_model_for_kbit_training(model)
第五步:配置模型行为(防OOM、启用梯度检查点)
model.config.use_cache = False
model.config.gradient_checkpointing = True
use_cache=false:禁用生成缓存,防止训练时出现 CUDA OOM(显存溢出)错误。
gradient_checkpointing=Ture:启梯度检查点(节省显存),以牺牲部分计算时间换取更低显存占用。
(2)LoRA 微调的配置参数
使用peft当中的Lora_config工具定义LoRA配置。
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,bias="none",task_type=TaskType.SEQ_2_SEQ_LM
)
LoRA原理:
模型在Transformer的过程公式为:
其中y为输出,W为大模型参数矩阵,x为大模型的输入。
因此W是一个的矩阵。
LoRA是通过冻结W使输出为
其中BA分别为为的矩阵。那么训练所需要调整的参数就从
,被降低到
。
这段代码中的r就是A和B的秩;lora_alpha是放大因子,用于对 LoRA 分支的输出进行线性缩放;Target_modules=["q_proj","v_proj"]表示在注意力模块“query”和“value”投影层插入LoRA结构;LoRA_dropout正则化防止过拟合,只对LoRA分支起作用;bias表示bias是否参与训练;task_type训练任务类型,这里使用Peft的TaskType.SEQ_2_SEQ_LM
加载lora_config
model = get_peft_model(model, lora_config)(3)格式化训练样本
构造对话模板:
def format_prompt(example):return f"<|user|>\n{example['instruction']}\n<|assistant|>\n{example['output']}"
将一条样本中的 "instruction"(用户提问)和 "output"(模型期望输出)按照对话形式拼接,形成最终的训练输入 prompt。
分词并设置标签
def tokenize(example):prompt = format_prompt(example)result = tokenizer(prompt, truncation=True, padding="max_length", max_length=512)result["labels"] = result["input_ids"].copy()return result
首先构造对话模板之后使用Transformer的AutoTokenizer对Prompt分词并编码。
| 参数 | 含义 | 对训练的影响 |
|---|---|---|
truncation=True | 超出最大长度时截断 | 🔹 防止超长输入导致报错 🔹 但可能 丢失重要信息 |
padding="max_length" | 填充到固定长度 | 🔹 提高 batch 对齐效率 🔹 太多 padding 会浪费显存,降低有效 token 比例 |
max_length=512 | 最长 token 数 | 🔹 控制模型处理的最大上下文范围 🔹 过短可能截断回答,过长显存压力大 |
return_tensors="pt" | 返回 PyTorch 张量 | 用于直接输入模型(微调常设在 Trainer 内处理) |
return_attention_mask=True | 是否返回 attention mask | 🔹 让模型忽略 padding 区域,非常重要,否则会学错位置 |
通常一个token对应一个中文字符或者更多。512个token通常对应500-600个中文字符,对应一篇法律文书摘要通常是足够的。
将原本的数据token化处理并移除原始字段,并作为用于模型训练的tokenized数据集。
tokenized_dataset = dataset.map(tokenize, remove_columns=dataset.column_names)
3.模型训练参数
training_args = TrainingArguments(output_dir="../lora/output",per_device_train_batch_size=1,gradient_accumulation_steps=16,num_train_epochs=4,learning_rate=2e-4,fp16=True,bf16=False,logging_steps=10,save_steps=200,save_total_limit=2,report_to="none",
)模型训练原理简述:
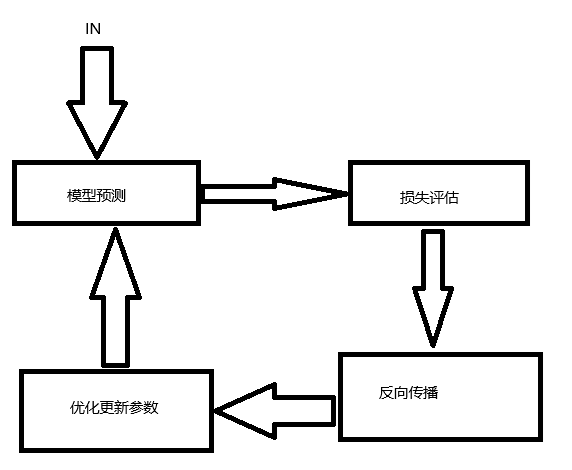
损失评估:计算模型预测结果与真实结果之间的差距,不同类型的任务对应不同的损失函数,在文本摘要生成任务中,模型的目标是根据输入一段简洁、准确的文字。这个任务属于序列到序列生成(Seq2Seq)或自回归语言建模(Causal LM),损失函数通常用于衡量生成文本与参考摘要的差异。交叉熵损失(Cross Entropy Loss)。模型按 token 逐个生成摘要,预测每个位置上的 token 的概率分布,交叉熵用于评估预测概率与真实 token 的偏差:
反向传播:在经历了模型预测,并根据预测结果以及损失函数计算出损失后,需要对不同的权重计算损失函数的梯度。再通过修改学习率更新权重,进而优化模型训练的参数。
参数解释:
per_device_train_batch_size:每个设备每一批载入多少条数据。越小越节省资源。
gradient_accumulation_steps=k:每k步更新一次权重,常用于显存较小的环境,比如训练大模型时节省显存。越大越节省资源。
num_train_epochs:训练轮数,指完整的遍历数据的次数。过大可能过拟合且消耗资源,过下训练结果较差但节省资源。
learning_rate:学习率,用于更新权重,过大容易过大过小都容易浪费计算资源(过大步长过长越过最低点,太小靠近损失最低点过慢)
fp/bp16:启用混合精度训练,使用 16 位浮动精度(bfloat16/float16)来加速训练。
logging_steps (k):每k步打印一次训练日志。
save_steps(k):每k步保存一次模型,(避免训练中断时丢失进度。)
save_total_limit (2):设置最多保留的检查点数。
report_to ("none"):指定训练日志报告的目标平台。
数据处理器:
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False
) data_collator是用于处理和批处理输入数据的工具,特别是在训练语言模型时。
DataCollatorForLanguageModeling 是 Hugging Face Transformers 库中用于语言模型训练的一个类。它会将一个批次的文本样本合并成一个批次并进行适当的处理,尤其是对于处理输入文本(例如将其转换为模型的输入格式)非常重要。
tokenizer用于指定tokenizer,mlm指定是否使用 Masked Language Modeling (MLM),即是否使用遮盖语言建模任务。False:表示这是一个 Causal Language Modeling(因果语言建模)任务。在因果语言建模中,模型的目标是预测下一个单词或 token,通常用于自回归的语言模型。
开始训练:
trainer = Trainer(model=model, #加载模型args=training_args, #加载训练参数train_dataset=tokenized_dataset, #加载训练数据data_collator=data_collator, #加载数据整理器
)trainer.train() #开始训练总结
以上就是模型训练需要的相关知识,总的来说主要需要设置的参数Lora的参数以及训练参数,Lora参数的目的在于在训练的过程中降低GPU负荷。训练参数的目的在于加速训练速度以及影响训练的效果过低和过高都会影响模型训练速度以及模型的训练效果。最终将所有的参数载入到peft的trainer当中进行训练即可。
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"import torch
torch.cuda.empty_cache()
torch.cuda.ipc_collect()from datasets import load_dataset
from transformers import (AutoTokenizer,AutoModelForCausalLM,TrainingArguments,Trainer,DataCollatorForLanguageModeling,BitsAndBytesConfig
)
from peft import (get_peft_model,prepare_model_for_kbit_training,LoraConfig,TaskType
)# ========== 基础配置 ==========
model_path = "model/deepseek-coder-6.7b-base"
data_path = "data/finetune_data.jsonl"# ========== 量化 & 加载模型 ==========
bnb_config = BitsAndBytesConfig(load_in_4bit=True, #开启四位量化bnb_4bit_quant_type="nf4", #使用NormalFloat4量化格式(高精度)bnb_4bit_use_double_quant=True, #启用double quantization(二次压缩,更有空间)bnb_4bit_compute_dtype=torch.float16 # 前向计算时使用 float16 精度(兼顾精度与速度)
)
)tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path,quantization_config=bnb_config,device_map="auto",trust_remote_code=True
)model = prepare_model_for_kbit_training(model)
model.config.use_cache = False
model.config.gradient_checkpointing = True# ========== 配置 LoRA ==========
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,bias="none",task_type=TaskType.SEQ_2_SEQ_LM
)
model = get_peft_model(model, lora_config)# ========== 加载数据 ==========
dataset = load_dataset("json", data_files=data_path)["train"]def format_prompt(example):return f"<|user|>\n{example['instruction']}\n<|assistant|>\n{example['output']}"def tokenize(example):prompt = format_prompt(example)result = tokenizer(prompt, truncation=True, padding="max_length", max_length=512)result["labels"] = result["input_ids"].copy()return resulttokenized_dataset = dataset.map(tokenize, remove_columns=dataset.column_names)# ========== 训练参数 ==========
training_args = TrainingArguments(output_dir="../lora/output",per_device_train_batch_size=1,gradient_accumulation_steps=16,num_train_epochs=4,learning_rate=2e-4,fp16=True,bf16=False,logging_steps=10,save_steps=200,save_total_limit=2,report_to="none",
)# ========== 数据整理器 ==========
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False
)# ========== 开始训练 ==========
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset,data_collator=data_collator,
)trainer.train()# ========== 保存模型 ==========
model.save_pretrained("lora/output")
tokenizer.save_pretrained("lora/output")