Qwen3术语解密
今天Qwen3 正式发布并将 8 款「混合推理模型」开源,作为工程同学,在阅读学习文章的时候其实有很多的专业术语没搞明白,这里借助大模型和网上资料自己整理了一部分分享给大家,希望能帮到同样有需求的同学
MoE模型与Dense模型
稠密模型(Dense Model)
- 类比:像一位全科医生,无论患者是感冒还是骨折,都必须亲自处理所有细节。
- 定义:传统神经网络结构,所有参数(神经元)在每次推理时全部激活,无论输入是什么。
- 特点:
-
- 统一处理:输入一句话或一张图片,整个模型的所有参数都参与计算。
- 参数与计算量成正比:参数越多,计算量越大。
- 例子:
-
- Qwen3-32B:每次推理必须调用全部320亿参数,适合通用任务,但计算成本高。
- 优点:结构简单,训练稳定。
- 缺点:规模越大,计算资源消耗越高。
混合专家模型(MoE, Mixture of Experts)
- 类比:像一家医院,患者挂号后自动分配到专科医生(呼吸科、骨科等),每个专家只解决自己擅长的问题。
- 定义:将大模型拆分成多个“小专家”,每次推理动态选择部分专家参与计算。
- 特点:
-
- 分而治之:模型总参数很大(如2350亿),但每次只激活部分参数(如220亿)。
- 高效灵活:不同任务调用不同专家(例如数学专家、编程专家)。
- 例子:
-
- Qwen3-235B-A22B:总参数2350亿,但每次激活220亿,计算量相当于一个220亿参数的稠密模型。
- 优点:
-
- 大容量、低计算成本(类似“召之即来,挥之即去”)。
- 适合处理多样化任务(如代码、数学、多语言)。
- 缺点:
-
- 训练复杂,需设计专家协作机制(路由算法)。
对比表格
| 特性 | 稠密模型 | MoE模型 |
| 参数激活方式 | 全部激活 | 按需激活部分专家 |
| 计算效率 | 低(参数越多越慢) | 高(只计算需要的部分) |
| 适用场景 | 通用任务、资源充足 | 多样化任务、资源有限 |
| 例子 | Qwen3-32B(320亿全激活) | Qwen3-235B(激活220亿) |
MoE模型如何知道激活哪部分参数?
在MoE(混合专家)模型中,“应该激活哪部分参数”其实就是“每次推理时,如何选择要用哪些专家子网络”。
- 谁来决定激活哪些参数?
- 门控网络(Gating Network):
-
- MoE模型里有一个专门的“小网络”,叫做门控网络(gating network)。
- 它会根据当前输入内容,自动决定本次推理应该激活哪些“专家”。
- 每个“专家”其实就是一组参数(一个子网络)。
- 选择过程是怎样的?
-
- 输入数据(比如一句话、一个图片特征等)先经过门控网络。
- 门控网络输出一个分数/概率分布,表示每个专家子网络的“适用程度”。
- 只激活分数最高的前N个专家(比如Top-2、Top-4等,具体数量由模型设计决定)。
- 本次推理只用这些被选中的专家,其余专家不参与计算。
- 为什么这样做?
-
- 不同专家擅长不同类型的任务或知识领域,门控网络会根据输入内容,动态选择最合适的专家组合。
- 这样既能保证模型的多样性和能力,又能大幅降低推理时的计算量。
- 举个简单例子
- 假设有10个专家子网络:
-
- 输入一句“写一段Python代码”,门控网络可能激活“擅长编程”的专家。
- 输入一句“翻译成英文”,门控网络可能激活“擅长翻译”的专家。
- 每次只激活2~4个专家,其余的休息。
大模型的预训练与后训练
预训练(Pre-training)
类比:像婴儿学说话 + 学生上课学知识
- 目标:让模型掌握语言规则、基础知识和通用逻辑。
- 过程:
-
- 海量数据输入:模型“阅读”36万亿token的文本(相当于数千万本书),涵盖119种语言、代码、数学公式等。
- 分阶段学习:
-
-
- 阶段1:学基础语言(如单词拼写、语法),上下文长度4K(相当于短文章)。
- 阶段2:重点学数理化、编程等知识密集型内容(类似学生分科学习)。
- 阶段3:扩展上下文到32K(能处理长篇小说或复杂代码文件)。
-
- 效果:模型学会“草莓(strawberry)怎么拼写”“代码循环怎么写”,但还不擅长解题或深度推理。
后训练(Post-training)
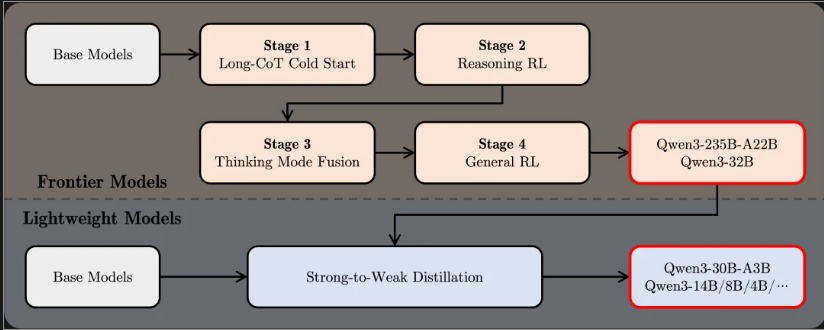
类比:像运动员针对性训练 + 医生实习积累经验
- 目标:让模型从“知识库”变成“问题解决专家”,适应具体任务需求。
- 过程:
-
- 长思维链冷启动:教模型“分步骤解题”(如数学题先列公式再计算)。
- 强化学习探索:模拟考试+老师批改,模型通过试错学会最优解法(类似学生刷题提分)。
- 模式融合:整合“深度思考”和“快速回答”两种模式,用户可自由切换(像医生问诊时,简单问题速答,复杂病情详细分析)。
- 通用能力强化:在20多个领域(如指令遵循、工具调用)反复优化,纠正错误行为(如避免胡编乱造)。
- 效果:模型不仅能回答“草莓有几个r”,还能解释“为什么是2个r”(通过思考模式逐步推理)。
| 阶段 | 预训练 | 后训练 |
| 学习方式 | 自学(无监督) | 教练指导(有监督/强化学习) |
| 目标 | 掌握语言和常识 | 适应任务,精准输出 |
| 类比 | 学课本知识 | 实习、专项培训 |
| 成果 | 知道“草莓的拼写” | 能数出“草莓有2个r” |
大模型的思考模式
思考模式
形象比喻:一位戴眼镜的老教授,在黑板前边写边推导,嘴里念念有词:“已知A,所以B,因此C……”
- 特点:
-
- 逐步推理:拆解复杂问题,分步骤输出中间结论(例如数学证明、代码调试)。
- 深度分析:像侦探破案,先假设、验证,再给出最终答案。
- 适用场景:
-
- 数学题:“如何证明勾股定理?”
- 代码优化:“这段Python循环为何运行缓慢?”
- 逻辑推理:“如果明天下雨,演唱会取消的概率是多少?”
- 用户指令:代码中设置
enable_thinking=True,或在提问时添加 /think 触发。
示例输出:
嗯,用户问“草莓(strawberry)有几个字母r”?
首先,我需要正确拼写“strawberry”:s-t-r-a-w-b-e-r-r-y。
然后逐个字母检查:第3个是r,第9个也是r。
所以答案是2个r。 答案:草莓(strawberry)中有2个字母r。非思考模式
形象比喻:一位语速极快的客服,秒回问题:“您好!答案马上给您!”
- 特点:
-
- 即问即答:跳过中间步骤,直接输出最终结果。
- 节省资源:计算时间短,适合对实时性要求高的场景。
- 适用场景:
-
- 简单事实:“今天北京天气如何?”
- 快速检索:“《哈利波特》作者是谁?”
- 格式化回复:“把这句话翻译成英文。”
- 用户指令:代码中设置
enable_thinking=False,或在提问时添加 /no_think 触发。
示例输出:
答案:草莓(strawberry)中有2个字母r。如何判断问题复杂度
大模型判断问题复杂度,类似医院分诊台护士快速评估患者病情。核心思路是多维度信号综合决策,而非单一标准。以下是大模型的常用“分诊术”:
- 问题类型识别
-
- 数学/逻辑类:含“证明”“求解”“计算”等关键词,自动触发深度思考。
例:“已知x²+2x+1=0,求x的值” → 概率90%启用思考模式。 - 事实查询类:含“多少”“哪里”“是谁”等关键词,倾向快速回答。
例:“北京人口多少?” → 直接调用知识库。
- 数学/逻辑类:含“证明”“求解”“计算”等关键词,自动触发深度思考。
- 文本结构分析
-
- 长度与复杂度:长问题(>50字)或含多子问题,可能需分步推理。
例:“如何优化这段Python代码?(附20行代码)” → 拆解变量、循环、算法。 - 特殊符号:数学公式、代码片段、逻辑符号(如∵、∴)暗示复杂度。
- 长度与复杂度:长问题(>50字)或含多子问题,可能需分步推理。
- 上下文关联度
-
- 多轮对话依赖:若当前问题依赖前文推理结果,自动延续思考模式。
例:
用户:“证明勾股定理。” → 思考模式分步推导。
用户:“那这个定理适用三维空间吗?” → 延续深度分析。
- 多轮对话依赖:若当前问题依赖前文推理结果,自动延续思考模式。
- 用户显式指令
-
- 指令标签:如“/think”“详细说明”强制启用思考模式,“/no_think”“简答”切快速模式。
- 系统预设:某些接口默认模式(如API默认快速,调试工具默认深度)。
从用户侧来说我们也有一些方法来帮助大模型更好的识别:
- 清晰表述问题类型
-
- 差示范:“关于三角形的东西?” → 模型困惑。
- 好示范:“请证明等边三角形的高与边长关系。” → 明确触发数学模式。
- 结构化输入
-
- 用Markdown分隔问题与上下文:
【背景】现有Python代码(见附件)运行缓慢。
【问题】如何优化循环部分的性能?