数据一致性巡检总结:基于分桶采样的设计与实现
数据一致性巡检总结:基于分桶采样的设计与实现
背景
在分布式系统中,缓存(如 Redis)与数据库(如 MySQL)之间的数据一致性问题是一个常见的挑战。由于缓存的引入,数据在缓存和数据库之间可能存在延迟、更新失败或逻辑错误,导致数据不一致。这种不一致可能会影响业务的正确性和用户体验。
为了解决这一问题,我们设计并实现了一套基于分桶采样的数据一致性巡检机制。该机制通过分桶采样、分批处理、数据一致性校验、采样结果存储、报警机制以及数据维护机制,能够有效发现缓存与数据库之间的数据不一致问题,同时优化数据存储和查询效率,保障业务的正确性与稳定性。
一、设计思想
- 分桶采样
- 将数据划分为多个桶(
BUCKET_SIZE),每个桶包含一定范围的数据。 - 根据单次需要采样的数量(
sampleCount)和单次拉取数据量(batchSize),计算得到总批次数,通过总批次数(totalBatches)生成唯一索引(generateUniqueIndexes),到不同桶中随机采样数据。 - 分桶采样的优点在于:
- 降低数据重复采样的概率,确保采样数据的独立性。
- 提高采样效率,避免全量扫描数据库。
- 常规的数据库
Rand()函数存在性能问题。
- 将数据划分为多个桶(
- 本地聚合与存储
- 采样数据在本地内存中聚合,通过
ConcurrentHashMap存储采样结果,减少频繁访问 Redis。 - 采样结果通过 Redis 的
SortedSet存储,score为触发采样的时间戳,value中存储的是不一致率以及不一致的订单信息,便于前端页面根据范围查询。
- 采样数据在本地内存中聚合,通过
- 数据一致性校验
- 针对每个订单号,分别校验缓存(Redis)与数据库(DB)中数据一致性。
- 可以排除指定字段校验,例如
datachangeLasttime。 - 校验结果包括:
- 对象级别一致性:校验单个对象(如订单、订单详情)的字段值是否一致。
- 列表级别一致性:校验列表数据(如乘客信息、推荐信息)的条目数量和内容是否一致。
- 报警机制
- 如果发现数据不一致,触发报警机制,通过邮件通知相关人员。
- 报警内容包括:
- 数据库名、表名、不一致率。
- 不一致订单的详细信息(订单号、DB 数据、Redis 数据、不一致类型)。
- 数据维护机制
- 定期将旧数据从热缓存迁移到冷缓存,并清理过期数据。
- 通过冷热数据分离策略,优化存储和查询效率。
- 触发采样的方式
- 定时任务触发:系统通过定时任务定期触发数据一致性巡检,确保数据一致性问题能够被及时发现。
- 前端主动触发:提供了前端接口,允许管理员根据需要手动触发数据一致性巡检。
二、实现细节
1. 分桶采样
int totalBatches = totalCheckCount / batchSize;
if (totalCheckCount % batchSize != 0) {totalBatches++;
}
List<Integer> uniqueIndexes = generateUniqueIndexes(totalBatches).stream().toList();
- 根据总数据量和批次大小计算总批次数。
- 生成唯一索引(
generateUniqueIndexes),确保每批次采样的数据独立且不重复。
2. 采样数据的获取
// 获取数据 SQL 针对 ID 取余 SELECT orderNumber FROM scm_grabticket_order WHERE Status IN ('O', 'L') AND id % ? = ? LIMIT ?
List<String> orderNumberList = orderDao.sampleEffectiveOrderNumber(BUCKET_SIZE, bucketIndex, batchSize);
- 每批次从数据库中采样有效订单号(
sampleEffectiveOrderNumber)。 - 采样逻辑基于分桶索引(
bucketIndex)和批次大小(batchSize),确保采样数据的独立性和代表性。
3. 数据一致性校验
checkConsistencyByOrderNumber(channelEnum, orderNumber, samplingResultMapForNewCache, DataConsistencyQueryType.NEW_CACHE);
-
针对每个订单号,分别校验新旧缓存与数据库的一致性。
-
校验逻辑包括:
-
对象级别一致性
checkObjectConsistencyAndStoreResult(orderNumber, samplingResult, dbValue, redisValue);- 比较单个对象的字段值是否一致,排除指定字段(
CHECK_CONSISTENCY_EXCLUDE_FIELDS)。
- 比较单个对象的字段值是否一致,排除指定字段(
-
列表级别一致性
checkListConsistencyAndStoreResult(orderNumber, samplingResult, dbValue, redisValue);- 比较列表数据的条目数量和内容是否一致,记录仅存在于 DB 或 Redis 中的数据。
-
4. 采样结果的存储
storeSampleResultToRedis(dbNameEnum, createTime, samplingResultMapForOldCache, DataConsistencyQueryType.NEW_CACHE);
- 将采样结果存储到 Redis 的
SortedSet中,score为触发采样的时间戳。 - 存储逻辑包括:
- 设置采样结果的创建时间(
createTime)和不一致率(inconsistencyRatio)。 - 数据保留时间为 15 天(
LocalDateTime.now().plusDays(15))。
- 设置采样结果的创建时间(
5. 报警机制
dataInConsistencyAlert(samplingResultMapForNewCache, samplingResultMapForOldCache, dbNameEnum);
- 如果发现数据不一致,触发报警机制。
- 报警内容包括:
- 数据库名、表名、不一致率。
- 不一致订单的详细信息(最多展示 5 条)。
6. 数据维护机制
定期迁移数据到冷缓存
为了优化存储和查询效率,防止 Redis 数据内存占用过大,系统实现了一个数据维护机制,定期将旧数据从热缓存迁移到冷缓存,并清理过期数据。
public void maintainInConsistencyData(DBNameEnum dbNameEnum) {long fifteenDaysAgo = DateUtils.localDateTimeToLongAccurateMinute(LocalDateTime.now().minusDays(15));long sixMonthsAgo = DateUtils.localDateTimeToLongAccurateMinute(LocalDateTime.now().minusMonths(6));for (TableNameIndexEnum value : TableNameIndexEnum.values()) {for (DataConsistencyQueryType dataConsistencyQueryType : dataConsistencyQueryTypes) {// 1. 从热数据中查询 15 天以外的数据,备份到冷数据中backUpOldData(dbNameEnum, value.getTableNameEnum(), dataConsistencyQueryType, fifteenDaysAgo);// 2. 清理冷数据中半年以外的数据removeOldDataFromColdStore(dbNameEnum, value.getTableNameEnum(), dataConsistencyQueryType, sixMonthsAgo);}}
}
- 备份旧数据:将 15 天以前的数据从热缓存迁移到冷缓存。
- 清理过期数据:删除冷缓存中 6 个月以前的数据。
- 数据精简:迁移到冷缓存时,会清除详细的不一致订单信息,只保留统计数据。
触发方式
数据维护机制的触发方式有两种:
- 定时任务调度:系统会定期自动触发数据维护任务,确保数据定期得到整理和优化。
- 前端主动触发:提供了前端接口,允许管理员手动触发数据维护任务,以应对特殊情况或紧急需求。
这种双重触发机制既保证了数据维护的自动化,又提供了灵活的人工干预途径。
三、前端展示
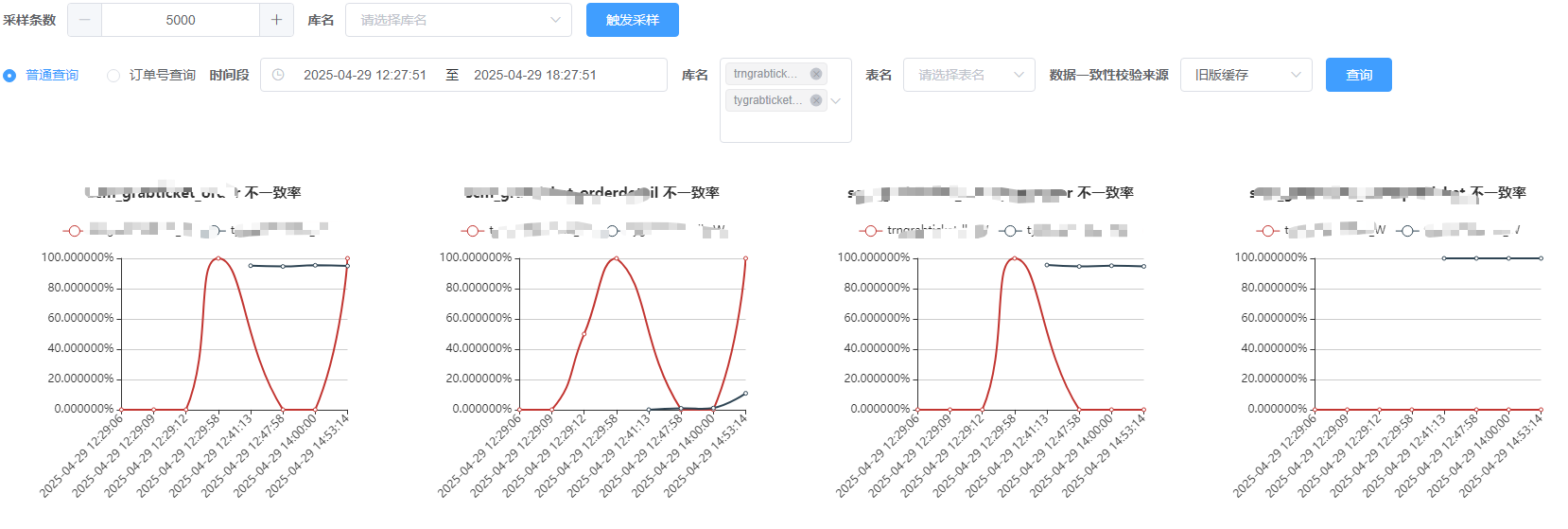
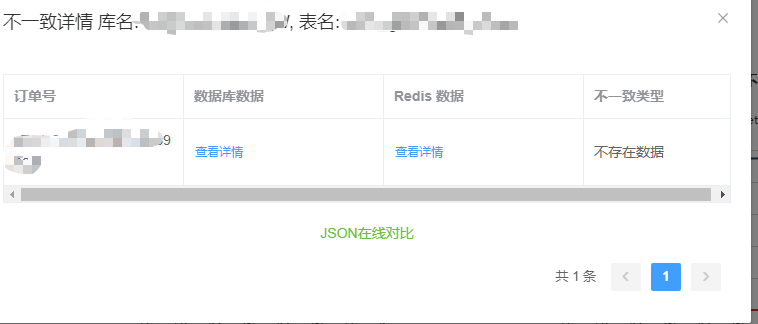
四、总结
本文总结了基于分桶采样的数据一致性巡检设计与实现,涵盖了分桶采样、分批处理、数据一致性校验、采样结果存储和报警机制等关键点。同时,介绍了数据维护机制,包括定期将旧数据迁移到冷缓存以及清理过期数据的策略。系统通过定时任务和前端主动触发两种方式来执行数据维护,既保证了自动化又提供了灵活性。