python:sklearn 决策树(Decision Tree)
5. 决策树(Decision Tree) - 第5章
算法思想:基于信息增益(ID3)或基尼不纯度(CART)递归划分特征。
编写 test_dtree_1.py 如下
# -*- coding: utf-8 -*-
""" 5. 决策树(Decision Tree) """
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split# 加载 乳腺癌数据
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)model = DecisionTreeClassifier(criterion='entropy', max_depth=3)
model.fit(X_train, y_train)
print("Accuracy:", model.score(X_test, y_test))
Anaconda 3
运行 python test_dtree_1.py
Accuracy: 0.9736842105263158
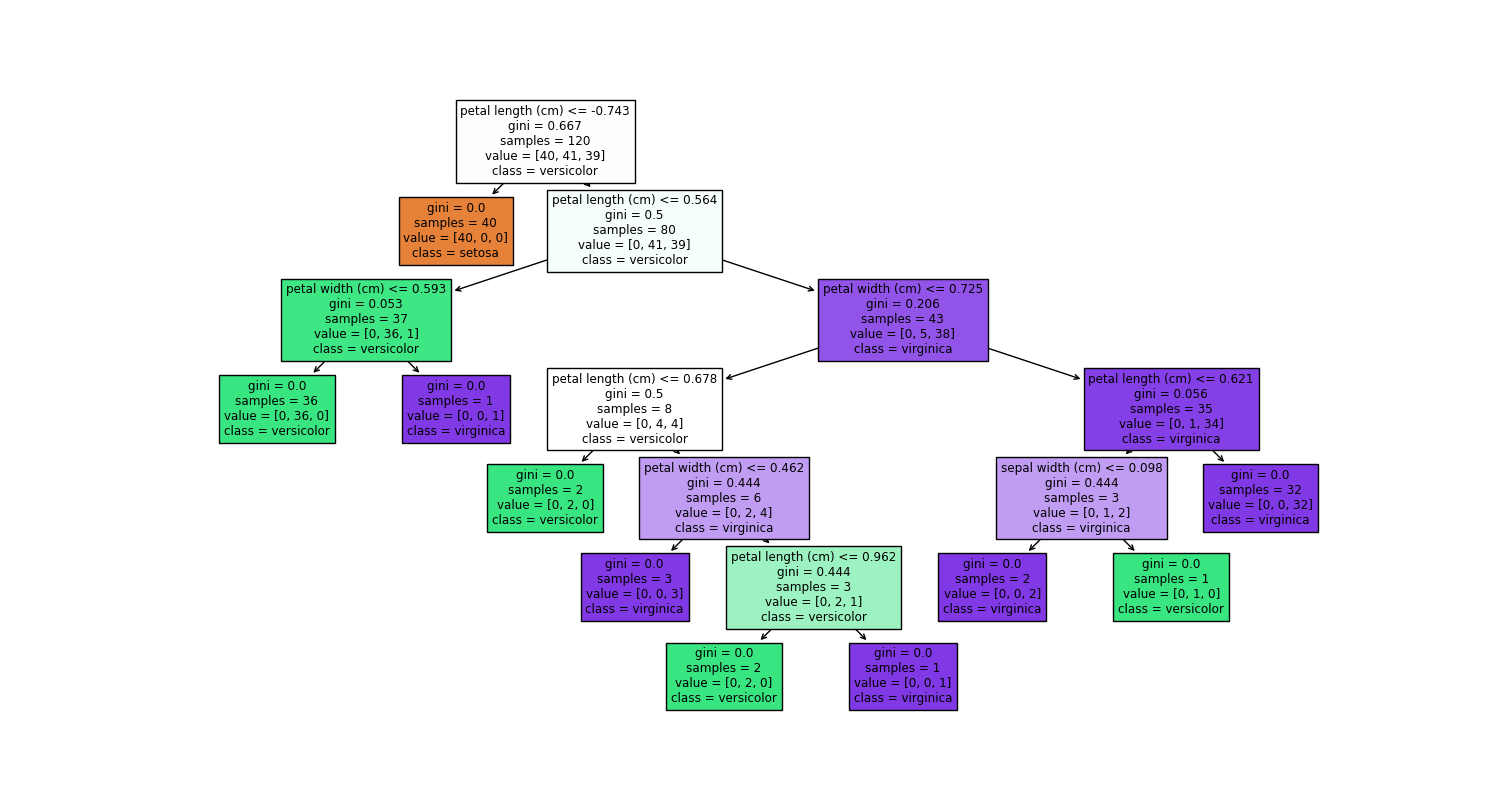
编写 test_dtree_2.py 如下
# -*- coding: utf-8 -*-
""" 5. 决策树(Decision Tree) """
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,accuracy_score
from sklearn.tree import plot_tree# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
f_names = iris.feature_names
t_names = iris.target_names# 数据预处理:按列归一化
X = preprocessing.scale(X)
# 切分数据集:测试集 20%
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化 决策树 分类模型
dtc = DecisionTreeClassifier()
# 模型训练
dtc.fit(X_train,y_train)
# 模型预测
y_pred = dtc.predict(X_test)
# 模型评估
# 混淆矩阵
#print(confusion_matrix(y_test,y_pred))
print("准确率: %.4f" % accuracy_score(y_test,y_pred))# 可视化决策树
plt.figure(figsize=(12,10))
plot_tree(dtc, feature_names=f_names, class_names=t_names, filled=True)
plt.show()
运行 python test_dtree_2.py