文件系统惹(细)
块概念
os文件系统访问磁盘,不是以扇区为单位的,而是以块为单位的,一般是4KB(也就是连续的8个扇区)(可以调整大小)。
磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇区
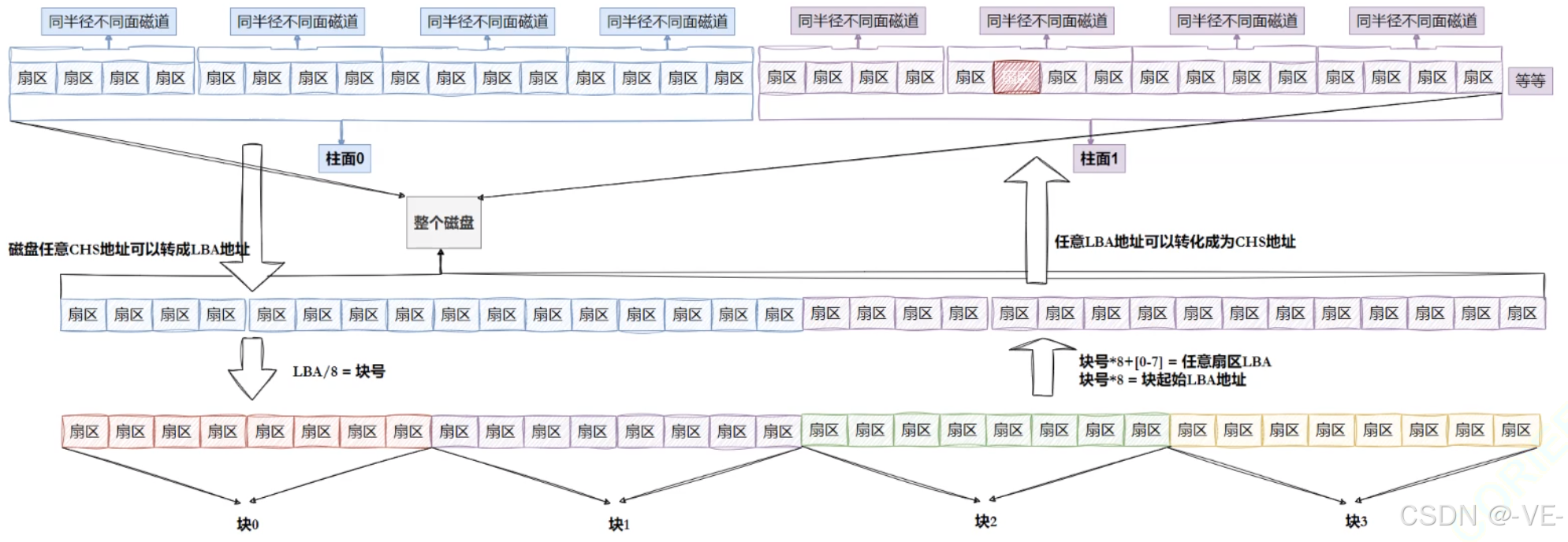
文件系统使用磁盘块,是以4KB为单位的。
分区
inode
liunx下文件=文件内容+文件属性,并且内容和属性是分开存储的。文件内容存储在Data Block中。
文件的属性存储在inode table中。linux中任何的正常文件都要有自己的属性集合。虽然每一个文件的属性内容可能不一样,但是每一个文件都要有相同类型的属性,所以文件的属性可以用一个结构体来描述(大小就一定了)。这个结构体所连成的表上的一个节点就叫做inode(大小固定,一般是128bytes)
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
};
};每一个文件都有其对应的inode,里面包含了与该文件有关的一些信息。
文件系统先格式化出 inode 和 block 块,假设某文件的权限和属性信息存放到 inode 4 号位置,这个 inode 记录了实际存储文件数据的 block 号,由此,操作系统就能快速地找到文件数据的存储位置。
注意:
3. Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,分析 inode 所记录的权限与用户是否符合,找到文件数据所在的block,读出数据。
4. ⽂件名属性并未纳⼊到inode数据结构内部
ext2文件系统
上面已经介绍了块和inode结构体(先描述),可是操作系统是怎么将这些管理起来的呢(再组织)?
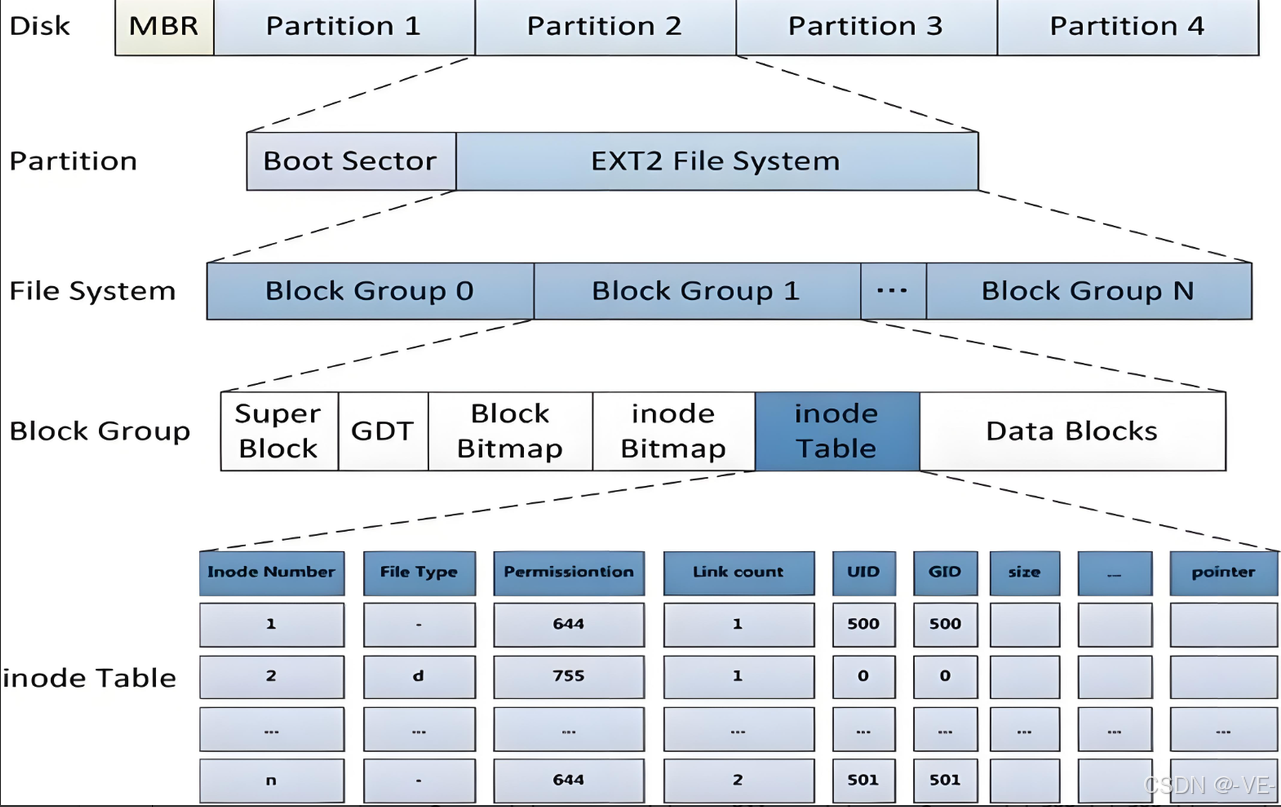
Boot Sector
Super Block
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le16 s_inode_size; /* size of inode structure */
。。。。。。。
};GDP(group descriptor table)
块组描述符表(是用来管理这个组块的),描述块组的属性信息,整个分区分为多少个块组就有多少个块组描述符表。每一个块组描述表都存放着一个块组的信息,如这个块组从哪开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。
注意块组描述描述符表在每一个块组的开头都有一份拷贝。
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap */
__le32 bg_inode_table; /* Inodes table block*/
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
};Block Bitmap(块位图)
每个位(bit)对应块组(block group)中的一个数据块(data block)。
-
1 表示对应的数据块已被占用。
-
0 表示数据块空闲可用。
用于快速分配和释放数据块。
Inode Bitmap (inode位图)
每个位对应块组中的一个inode(索引节点)。
-
1 表示对应的inode已被占用。
-
0 表示inode空闲。
用于管理文件/目录的元数据(如权限、大小等)的分配。
-
物理存储
每个位图占用一个完整的块(block),块大小由文件系统定义(如1KB、4KB等)。-
例如,4KB的块可存储
4 * 1024 * 8 = 32,768个位,管理对应数量的数据块或inode。
-
-
逻辑表示
位数组按顺序排列,索引从0开始,直接映射到块组内的资源。 -
与块组的关系
-
每个块组独立维护自己的block bitmap和inode bitmap,实现分布式管理,减少竞争和碎片化。
-
超级块(superblock)和组描述符(group descriptor)记录位图的位置(前面提到了)
Data Block
inode和Datablock映射
然后需要确定该inode号属于哪个块组。每个块组中的inode数量应该是固定的,可以通过超级块中的s_inodes_per_group字段获得。假设超级块中有这个信息,那么块组号应该是(inode号 - 1)除以每个块组的inode数量,因为inode号通常从1开始。例如,如果每个块组有8192个inode,那么inode号8193属于第二个块组(索引从0开始的话,可能是块组1)。
确定了块组之后,接下来需要找到该块组的组描述符。组描述符里会有该块组的inode表的起始块号。然后,计算在该块组内的inode索引,即(inode号 - 1)% s_inodes_per_group。接着,用这个索引乘以inode的大小(比如128字节或256字节,由超级块中的s_inode_size决定),得到在inode表中的偏移量。这样就能找到该inode的具体位置了。
读取到inode结构之后,里面应该包含文件的元数据,比如模式(文件类型和权限)、用户和组ID、大小、时间戳等等。另外,inode中有直接块指针、间接指针、双重间接、三重间接指针等,用于定位文件的数据块。对于小文件,直接块指针就足够了;大文件则需要通过间接块来扩展寻址。
然后,要获取文件的内容,需要根据inode中的块指针读取相应的数据块。每个块指针指向一个数据块,数据块中存储着文件的实际内容。如果是目录的话,数据块中的内容会是目录条目,包含文件名和对应的inode号等信息。但题目中已经知道inode号,所以如果是普通文件,直接读取这些数据块即可得到文件内容。
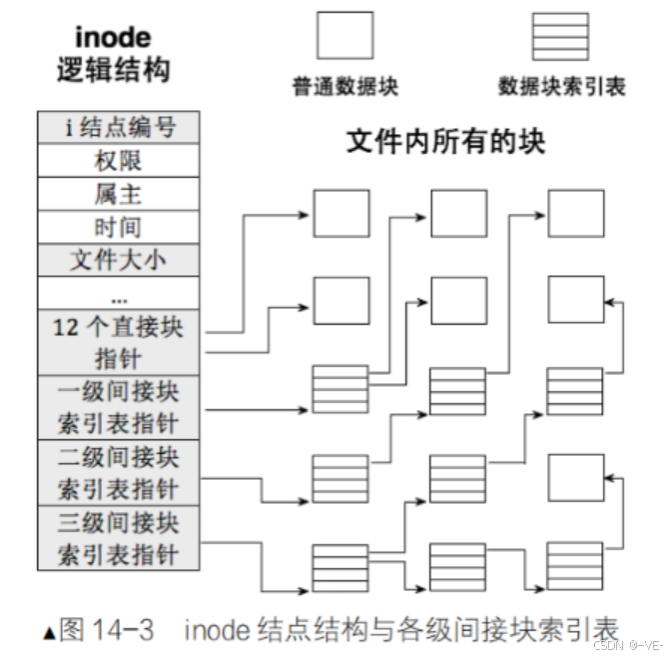
我们在来看一下新建一个文件是如何完成的吧:
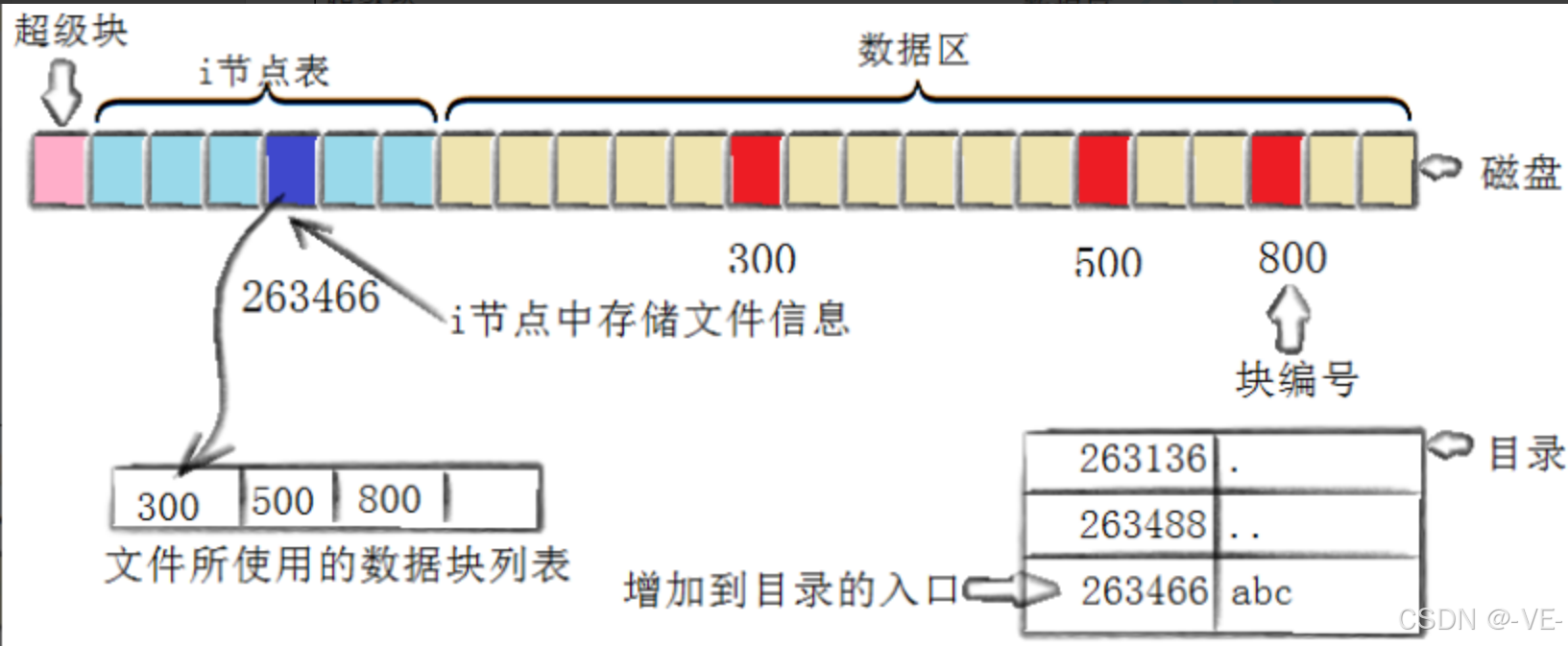
目录和文件名
目录是文件,磁盘上是没有目录的概念的,都是文件属性+文件内容,对于目录的属性就不用多说了,目录的内容保存的是文件名+文件对应的inode号。
所以可以看到对于一个你要访问的文件,以一定要知道这个文件的路径,只有知道了路径你才能找打这个文件所在的文件夹,然后才能通过你提供的文件名来找到对应的inode号,才算是真正地找到了文件。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 系统调⽤,⾃⾏查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL)
{
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")== 0)
continue;
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}路径解析
聪明的读者已经发现了问题,我们当前工作目录也是一个文件,所以要访问他还是需要打开他的上级目录,那就还要打开他的上上级目录。。。。
⽽实际上,任何⽂件,都有路径,访问⽬标⽂件,⽐如: /home/whb/code/test/test/test.c 都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问 到test.c。这个过程叫做Linux路径解析。
那么路径都是谁提供的:
路径缓存
struct dentry
{
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union
{
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中