第二章:14.1 倾斜数据集的误差指标
目录
1. 问题背景
2. 准确率的局限性
3. 混淆矩阵
4. 精确率和召回率
5. 精确率和召回率的重要性
混淆矩阵
精确率(Precision)
召回率(Recall)
解释
6. 结论
在训练一个二进制分类器来检测一种罕见疾病时,我们通常会用到一些误差度量标准来评估算法的性能。这是因为仅仅使用分类误差率(如准确率)可能无法准确反映算法的实际效果,尤其是在处理不平衡数据集时。
1. 问题背景
假设我们正在开发一个二进制分类器,用于检测一种罕见疾病。在这种情况下,y=1 表示患者患有该疾病,y=0 表示患者未患病。由于这种疾病非常罕见,假设在人群中只有 0.5% 的患者实际患病。这意味着数据集是高度不平衡的,大多数样本的标签为 y=0。
2. 准确率的局限性
在这种不平衡数据集中,仅使用准确率来评估算法可能具有误导性。例如,如果一个算法总是预测 y=0(即从未诊断出任何患者患病),它的准确率可能会非常高(99.5%),因为大多数样本本身就是未患病的。然而,这样的算法显然是无用的,因为它无法检测出任何真正的患者。
3. 混淆矩阵
为了更全面地评估算法性能,我们通常使用混淆矩阵(Confusion Matrix)。混淆矩阵是一个 2×2 的表格,用于记录算法预测结果与实际标签之间的关系。具体来说:
-
真正例(True Positive, TP):算法预测为患病(
y=1),且实际也患病。 -
假正例(False Positive, FP):算法预测为患病(
y=1),但实际未患病。 -
真负例(True Negative, TN):算法预测为未患病(
y=0),且实际也未患病。 -
假负例(False Negative, FN):算法预测为未患病(
y=0),但实际患病。
4. 精确率和召回率
为了更好地评估算法的性能,我们通常会计算精确率(Precision)和召回率(Recall):
-
精确率(Precision):衡量算法预测为患病的样本中,真正患病的比例。计算公式为:
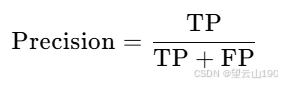
例如,如果算法预测了 20 个样本患病,其中 15 个实际患病,那么精确率为:
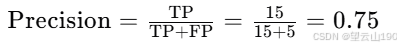
-
召回率(Recall):衡量所有实际患病的样本中,被算法正确预测为患病的比例。计算公式为:
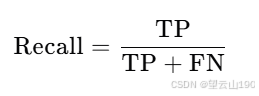
例如,如果实际有 25 个患者患病,算法正确预测了 15 个,那么召回率为:
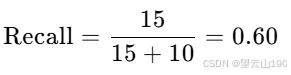
5. 精确率和召回率的重要性
-
精确率:帮助我们评估算法的可靠性。如果精确率很高,说明当算法预测患者患病时,有很大概率是正确的。
-
召回率:帮助我们评估算法的覆盖能力。如果召回率很高,说明算法能够检测出大部分实际患病的患者。
如果一个算法总是预测 y=0,那么它的精确率和召回率都会很低(甚至为零),因为没有真正例(TP)。因此,精确率和召回率可以帮助我们识别那些看似准确率很高但实际上无用的算法。
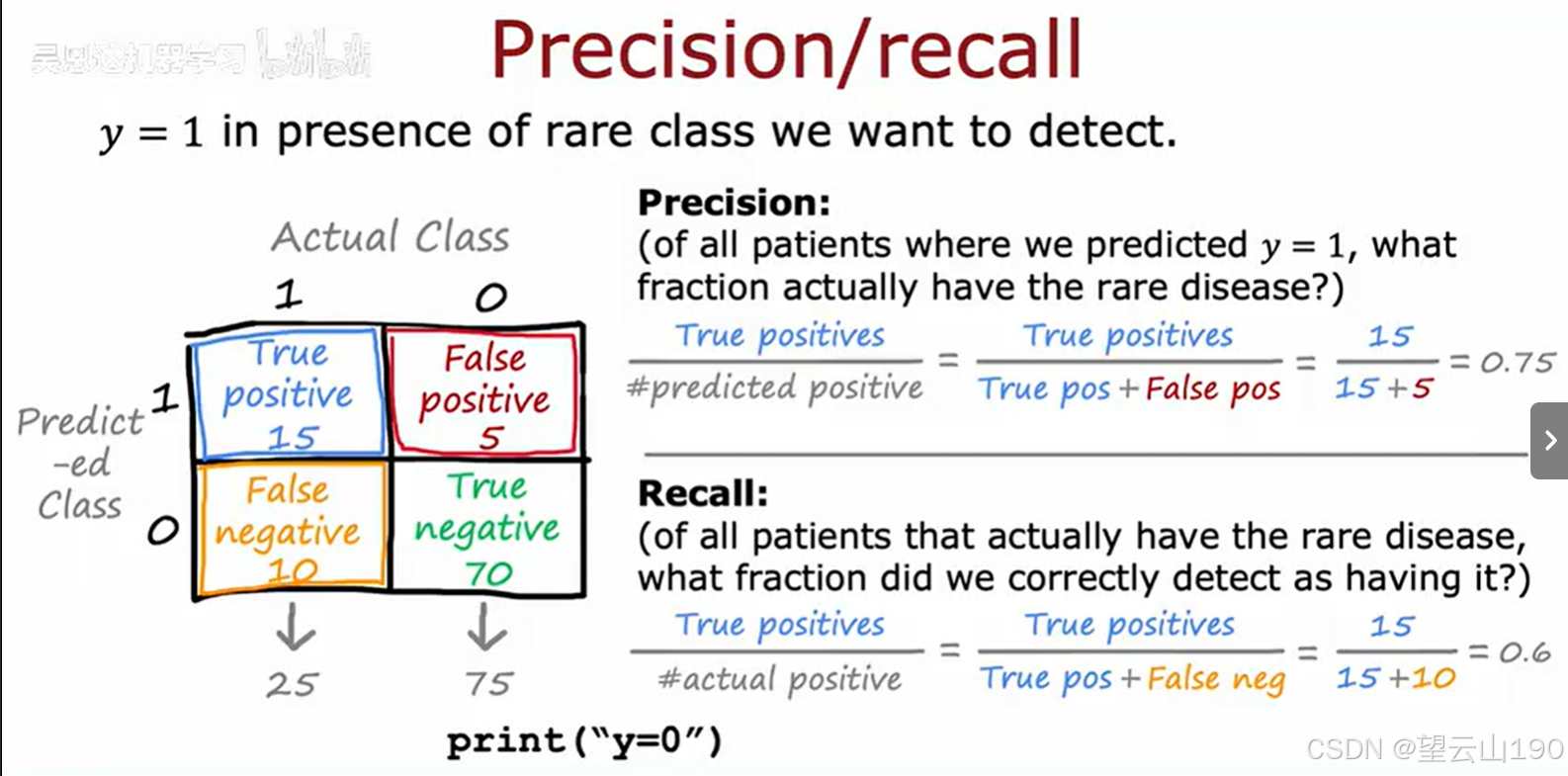
图片展示了一个关于精确率(Precision)和召回率(Recall)的混淆矩阵示例,用于评估一个二元分类器在检测罕见疾病时的性能。以下是图片中的内容整理:
混淆矩阵
| 实际类别\预测类别 | 1(患病) | 0(未患病) |
|---|---|---|
| 1(患病) | 真正例 (True Positive, TP) 15 | 假负例 (False Negative, FN) 10 |
| 0(未患病) | 假正例 (False Positive, FP) 5 | 真负例 (True Negative, TN) 70 |
精确率(Precision)
精确率是指在所有被预测为正类(患病)的样本中,实际为正类的比例。 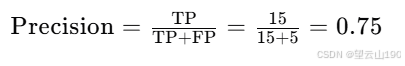
召回率(Recall)
召回率是指在所有实际为正类(患病)的样本中,被正确预测为正类的比例。 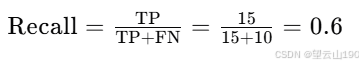
解释
-
精确率:反映了模型预测为患病的准确性。在这个例子中,精确率为75%,意味着在所有被预测为患病的病人中,有75%的病人确实患有这种疾病。
-
召回率:反映了模型识别出所有实际患病病人的能力。在这个例子中,召回率为60%,意味着在所有实际患病的病人中,有60%的病人被正确地诊断为患病。
这个例子说明了在处理罕见疾病时,除了准确率之外,精确率和召回率也是非常重要的评估指标。
6. 结论
在处理不平衡数据集时,仅靠准确率是不够的。精确率和召回率能够更全面地评估算法的性能,帮助我们确保算法不仅能够正确预测患者是否患病,还能在实际应用中真正发挥作用。一个好的算法应该在精确率和召回率上都表现出色,这样才能在实际诊断中提供可靠的帮助。