day7 python针对心脏病数据集预处理
在数据科学与机器学习领域,数据预处理与可视化是挖掘数据价值的关键前置步骤。本文以 heart1.csv 心脑血管疾病数据集为例,借助 Python 中的 pandas、matplotlib、seaborn 以及 scikit-learn 库,详细演示数据加载、缺失值处理、特征相关性分析、单特征可视化等核心操作,帮助读者快速掌握数据探索的实用技能。
一、数据处理与可视化库导入
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
在数据探索任务中,选用合适的工具库能大幅提升工作效率。上述代码导入了六个关键库:
pandas:作为数据处理的核心库,用于读取、清洗、转换和分析结构化数据,在后续的数据加载与预处理环节中发挥重要作用。matplotlib与seaborn:数据可视化的利器,其中seaborn基于matplotlib进行了高级封装,能够绘制出更美观、专业的图表,助力数据特征的直观呈现。SimpleImputer(来自scikit-learn):专门用于处理数据中的缺失值,提供了多种填充策略,确保数据的完整性。OneHotEncoder(同样来自scikit-learn):针对离散特征进行独热编码,将分类数据转换为机器学习算法易于处理的数值形式。ColumnTransformer:可对数据集中不同类型的列,灵活应用不同的预处理方法,实现数据预处理流程的自动化与规范化。
二、数据加载与初步检查
2.1 数据加载
# 1. 数据加载与初步检查
data = pd.read_csv('heart1.csv')
print(f"数据集形状: {data.shape}\n")
数据探索的第一步是将数据集加载到内存中。通过 pd.read_csv('heart1.csv') 语句,pandas 库将 heart1.csv 文件中的数据读取,并存储为 DataFrame 格式,赋值给 data 变量。随后,两行打印语句分别输出数据加载成功的提示信息,以及数据集的形状(包含行数和列数),帮助我们快速了解数据集的规模。例如,若输出 数据集形状: (1000, 10),则表示该数据集包含 1000 条记录和 10 个特征。
2.2 数据预览与缺失值检查
# 数据预览
print(data.head())
print("缺失值分布:")
print(data.isnull().sum())
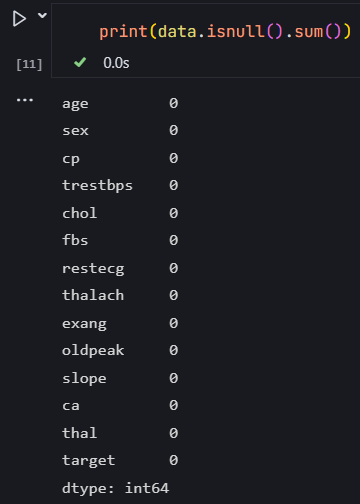
成功加载数据后,需要对数据的内容和质量进行初步检查。data.head() 方法默认展示数据集的前 5行数据,通过观察这些数据,可以了解数据的大致结构、各列的数据类型以及数据的取值范围。而 data.isnull().sum() 则用于统计数据集中每列缺失值的数量。例如,若某列输出的结果为 50,则表示该列存在 50 个缺失值。通过这一步骤,能够快速定位存在缺失值的特征列,为后续的缺失值处理提供依据。
三、数据可视化分析
3.1 特征相关性热力图
# 设置中文字体和负号显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False # 计算特征相关性矩阵
correlation_matrix = data.corr()# 绘制相关性热力图
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, cbar=True, annot=True, cmap='coolwarm')
plt.title('各特征之间的相关性热力图')
plt.show()
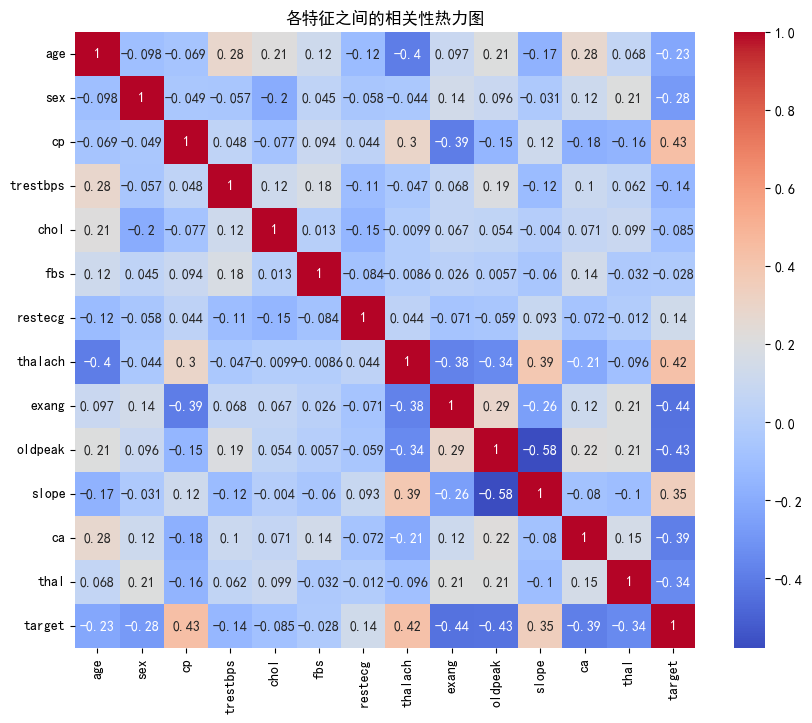
在数据探索过程中,了解特征之间的相关性至关重要。由于中文和负号在图表中可能出现显示异常的情况,因此首先通过 plt.rcParams 配置 matplotlib 的字体和负号显示规则,确保图表能够正确展示中文标签和负数值。
接下来,使用 data.corr() 计算数据集中所有数值型特征之间的相关性矩阵。相关性矩阵中的每个元素表示对应两个特征之间的相关系数,其取值范围在 -1 到 1 之间:
- 接近 1 表示两个特征之间存在强正相关关系,即一个特征值增加时,另一个特征值也倾向于增加。
- 接近 -1 表示两个特征之间存在强负相关关系,即一个特征值增加时,另一个特征值倾向于减少。
- 接近 0 则表示两个特征之间相关性较弱。
最后,借助 seaborn 的 heatmap 函数,将相关性矩阵绘制成热力图。cbar=True 显示图例,方便我们直观了解相关系数的取值范围;annot=True 在热力图的每个单元格中标注具体的相关系数数值;cmap='coolwarm' 指定颜色映射方案,通过颜色的深浅直观反映相关系数的大小。通过观察热力图,可以快速识别出哪些特征之间存在较强的相关性,为后续的特征选择和模型构建提供重要参考。
3.2 离散特征识别与单特征可视化
# 识别离散特征
discrete_features = []
for i in data.columns:if data[i].dtype == 'object':discrete_features.append(i)# 绘制单特征可视化图表
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(data['age'], kde=True, bins=20)
plt.title('年龄分布')plt.subplot(1, 2, 2)
sns.boxplot(x=data['chol'])
plt.title('年龄分布')
plt.tight_layout()
plt.show()
在数据集中,不同类型的特征需要采用不同的分析方法。首先,通过循环遍历数据集的所有列名,利用 data[i].dtype == 'object' 判断每列的数据类型是否为对象类型(在 pandas 中,对象类型通常用于存储字符串等离散数据),将符合条件的列名添加到 discrete_features 列表中,从而完成离散特征的识别。
为了更直观地了解数据集中连续特征的分布情况,使用 matplotlib 的 subplot 函数和 seaborn 的 histplot、boxplot 函数,在同一画布上绘制两个子图:
- 左侧子图:使用
sns.histplot(data['age'], kde=True, bins=20)绘制年龄(age列)的直方图。kde=True选项在直方图上叠加核密度估计曲线,能够更平滑地展示数据的分布趋势;bins=20将年龄数据划分为 20 个区间,有助于观察数据在不同年龄段的分布密度。 - 右侧子图:通过
sns.boxplot(x=data['chol'])绘制年龄(chol列)的箱线图。箱线图能够清晰地展示数据的中位数、四分位数、最小值、最大值以及可能存在的异常值,帮助我们快速了解数据的集中趋势、离散程度和分布形态。
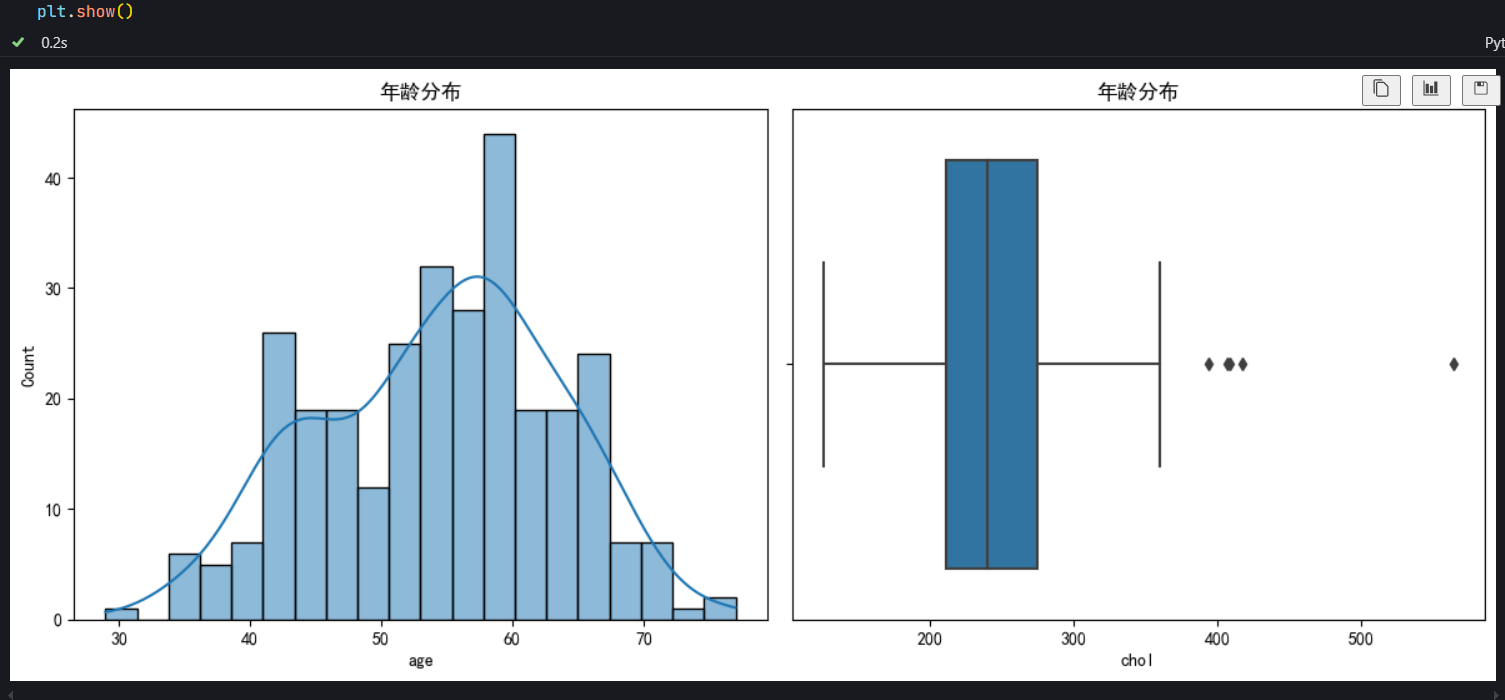
最后,plt.tight_layout() 自动调整子图的布局,确保子图之间不会出现标签重叠等问题,使图表更加美观和易于阅读。
通过以上一系列的数据探索操作,我们能够对 heart1.csv 数据集有更深入的了解,为后续的数据清洗、特征工程以及机器学习模型构建奠定坚实的基础。在实际的数据科学项目中,数据探索环节是不可或缺的重要步骤,通过不断尝试不同的可视化方法和分析手段,能够挖掘出数据中隐藏的有价值信息。
![]() @浙大疏锦行
@浙大疏锦行