Spark-Streaming核心编程(2)
Kafka 0-10 Direct 模式
需求:
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
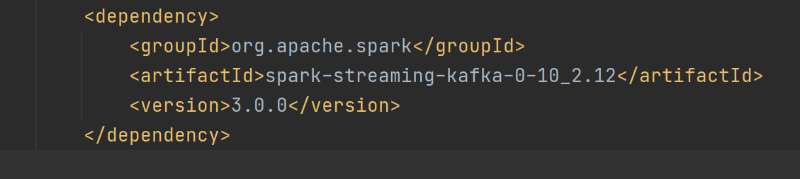
导入依赖
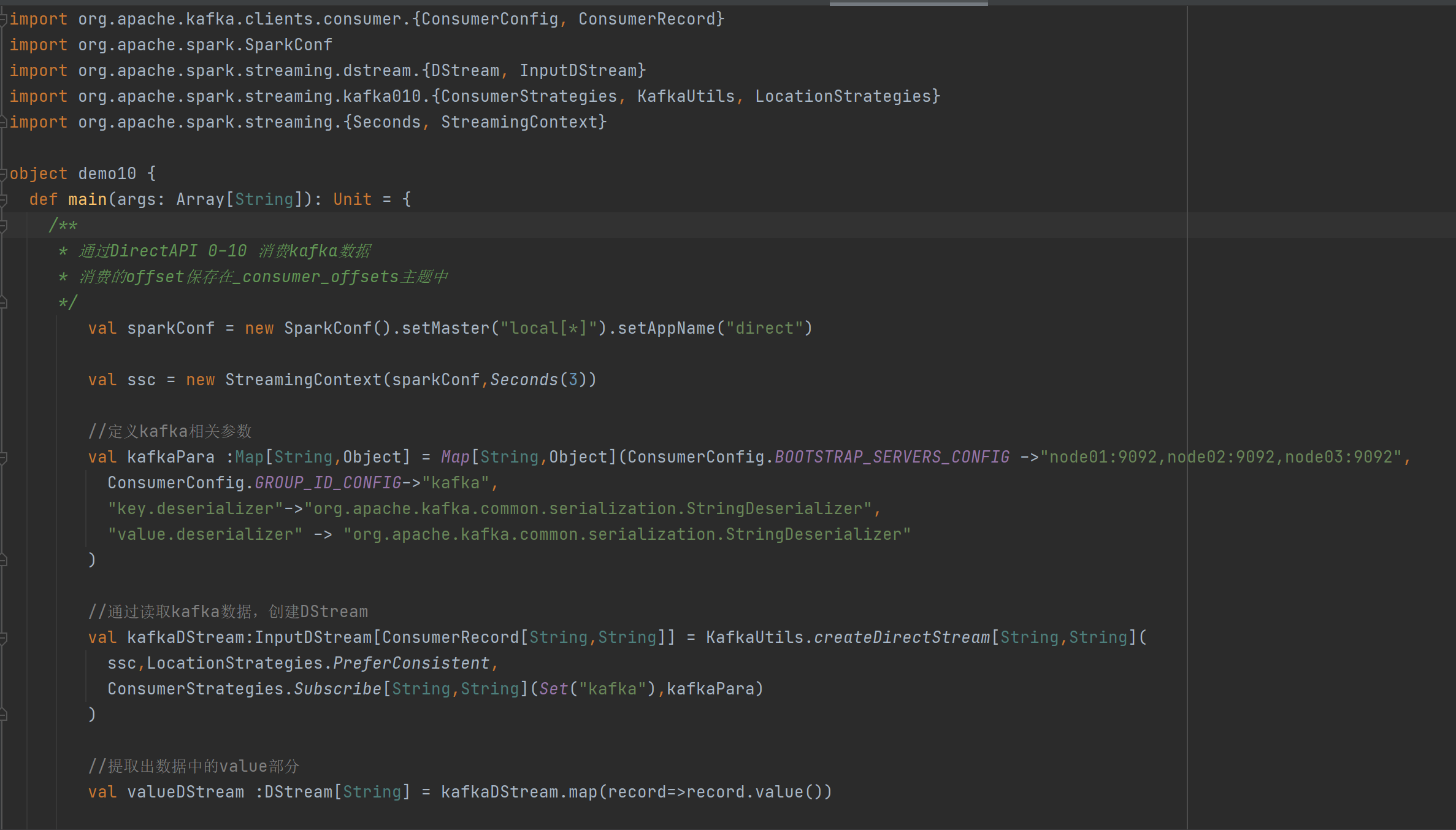
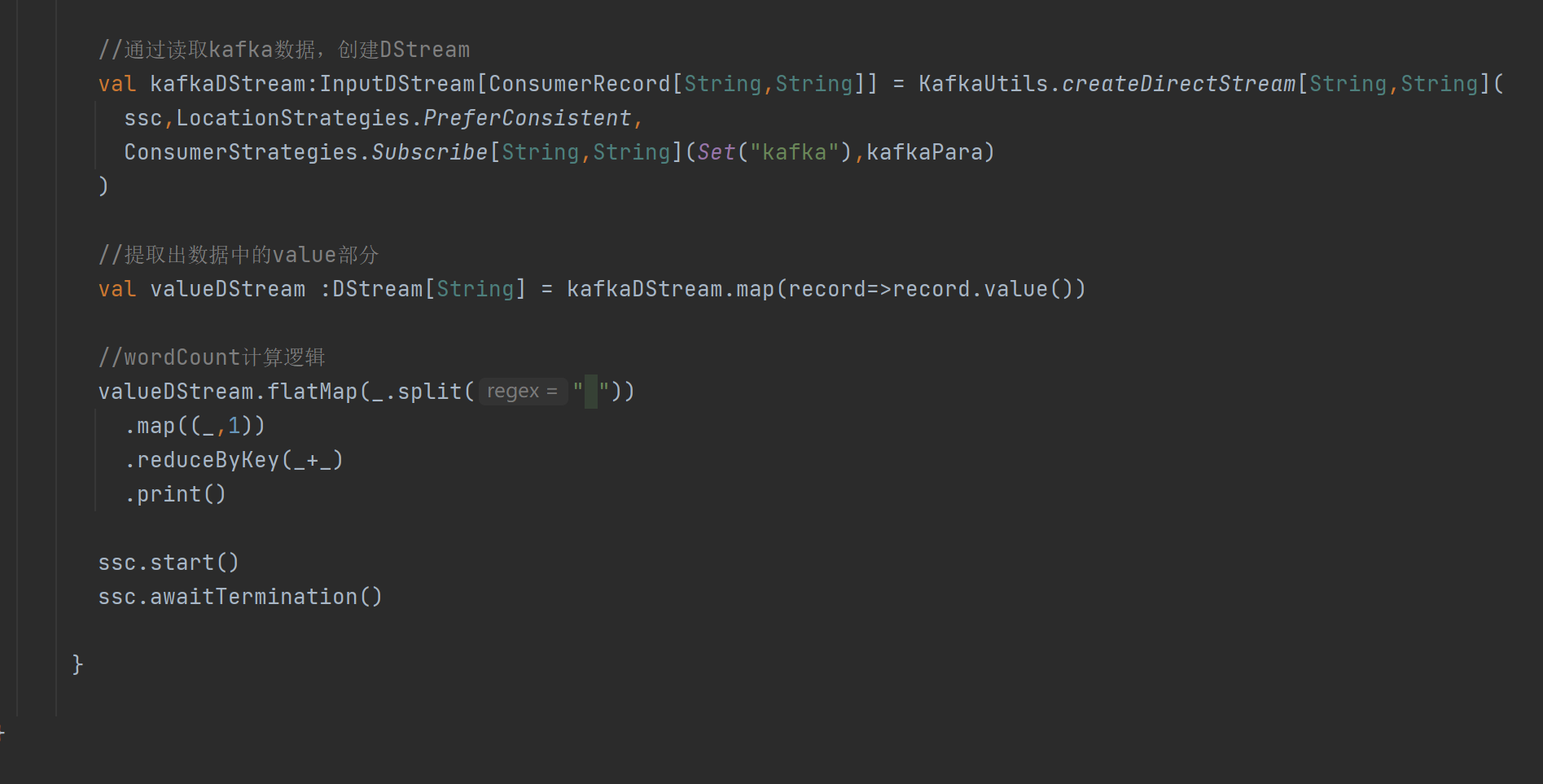
编写代码
开启Kafka集群和Kafka生产者
注意:开启Kafka集群前需要开启三台机器的zookeeper,启动命令zkServer.sh start
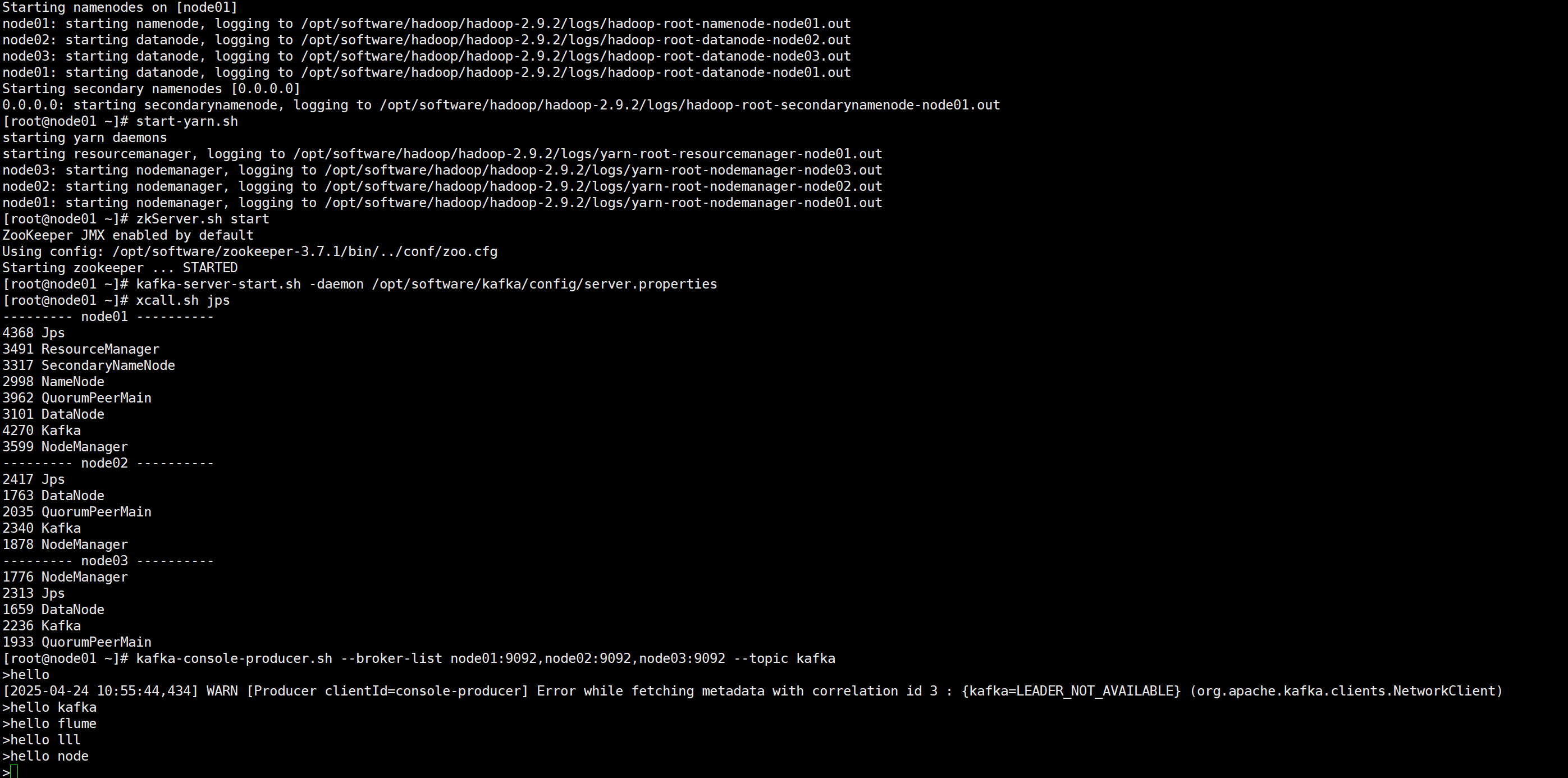
在控制台输入数据,运行程序,接受Kafka生产的数据
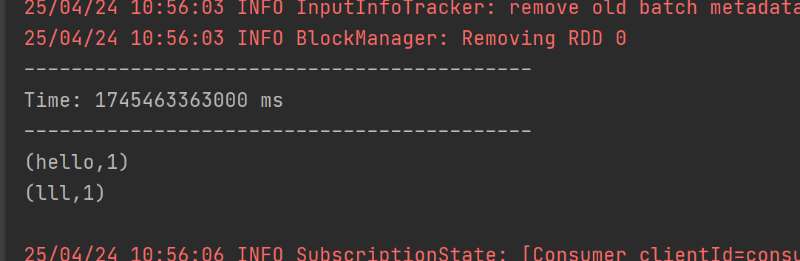
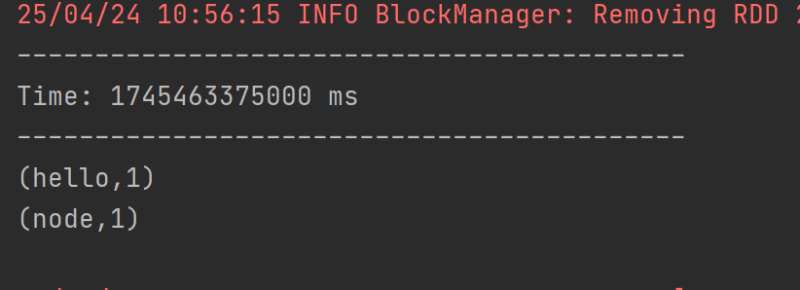
需求:
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
注意:开启Kafka集群前需要开启三台机器的zookeeper,启动命令zkServer.sh start
在控制台输入数据,运行程序,接受Kafka生产的数据