数据集中常见的11种变量类型及其在数据分析中的重要性
本文介绍了数据集中常见的11种变量类型及其在数据分析中的重要性。自变量和因变量是基础,而混杂变量和相关变量需特别注意,因为它们会影响因果推断的准确性。控制变量用于消除混杂因素的影响,潜在变量则通过其他变量推断得出。交互变量衡量多个变量间的相互作用,平稳和非平稳变量在时间序列分析中至关重要。滞后变量用于捕捉历史信息,而泄露变量可能导致模型过拟合。了解这些变量类型有助于更好地构建和优化数据分析模型。
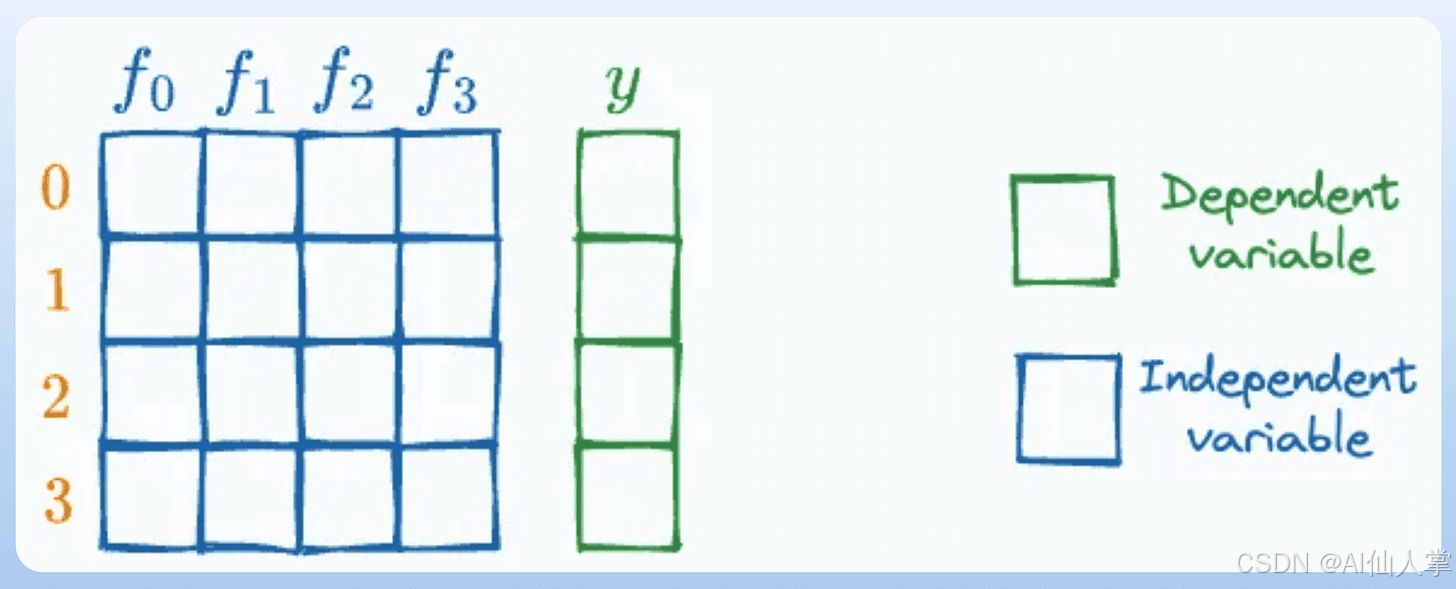
数据集中变量的类型
在任何表格型数据集中,我们通常会将列分为特征列或目标列。
然而,在数据集中可能会发现或定义出很多种变量,如下所示:
接下来我一个个的了解他们
1 - 2)自变量和因变量
自变量Independent variables是用于作为输入来预测结果的特征,也被称为预测变量、特征或解释变量。
因变量dependent variables是被预测的结果,也被称为目标变量、响应变量或输出变量。
3 - 4)混杂变量和相关变量
混杂变量通常出现在因果关系研究(因果推断)中。
这些变量并非总是研究的主要关注点,但如果处理不当,可能会导致奇怪的关联。
假设我们想衡量冰淇淋销量对空调销量的影响,而这两者是高